3Modelos no lineales. Transformación de variables. Ingeniería de características.
En el análisis de datos, muchas relaciones entre variables no pueden ser capturadas adecuadamente mediante modelos de regresión lineal. Aunque la regresión lineal es una herramienta poderosa por su simplicidad e interpretabilidad, existen numerosos escenarios donde las relaciones entre las variables son inherentemente no lineales.
Limitaciones de la regresión lineal:
Relaciones no lineales: En muchos casos, la relación entre las variables no es proporcional ni constante. Por ejemplo, el crecimiento poblacional o la desintegración radiactiva siguen patrones exponenciales.
Interacciones no consideradas: La regresión lineal simple no capta interacciones entre variables a menos que se incluyan explícitamente.
Sensibilidad a valores atípicos: Los modelos lineales pueden verse influenciados por outliers, afectando la precisión del modelo.
Supuestos estrictos: La regresión lineal asume homocedasticidad, normalidad de los errores e independencia, lo cual no siempre se cumple en la práctica.
Estas limitaciones abren la puerta a la necesidad de modelos más flexibles (modelos no lineales) que puedan capturar relaciones complejas entre las variables.
Además de utilizar modelos no lineales, otra estrategia fundamental es la transformación de variables. Mediante transformaciones matemáticas (como logaritmos, potencias o funciones exponenciales), es posible linearizar relaciones no lineales o mejorar la adecuación del modelo. Estas transformaciones pueden también ayudar a cumplir con los supuestos de normalidad y homocedasticidad en los modelos.
Finalmente, la ingeniería de características juega un papel crucial en la mejora del rendimiento de los modelos predictivos. Este proceso implica la creación, modificación o combinación de variables explicativas para extraer mayor información de los datos. La ingeniería de características es clave para mejorar la capacidad predictiva de los modelos, especialmente en entornos de alta dimensionalidad o con datos complejos.
A lo largo de este tema, exploraremos estos tres pilares: cómo identificar y ajustar modelos no lineales, cómo aplicar transformaciones efectivas a las variables y cómo desarrollar nuevas características que potencien el análisis y la predicción.
3.1 Modelos no lineales
Los modelos de regresión no lineal son herramientas esenciales cuando las relaciones entre las variables no pueden capturarse adecuadamente con modelos lineales. La regresión polinómica, exponencial, logarítmica y los modelos por tramos ofrecen diferentes enfoques para representar patrones complejos en los datos. Comprender cuándo y cómo aplicar estos modelos es fundamental para mejorar la precisión y la interpretabilidad en el análisis de datos.
3.1.1 Regresión Polinómica
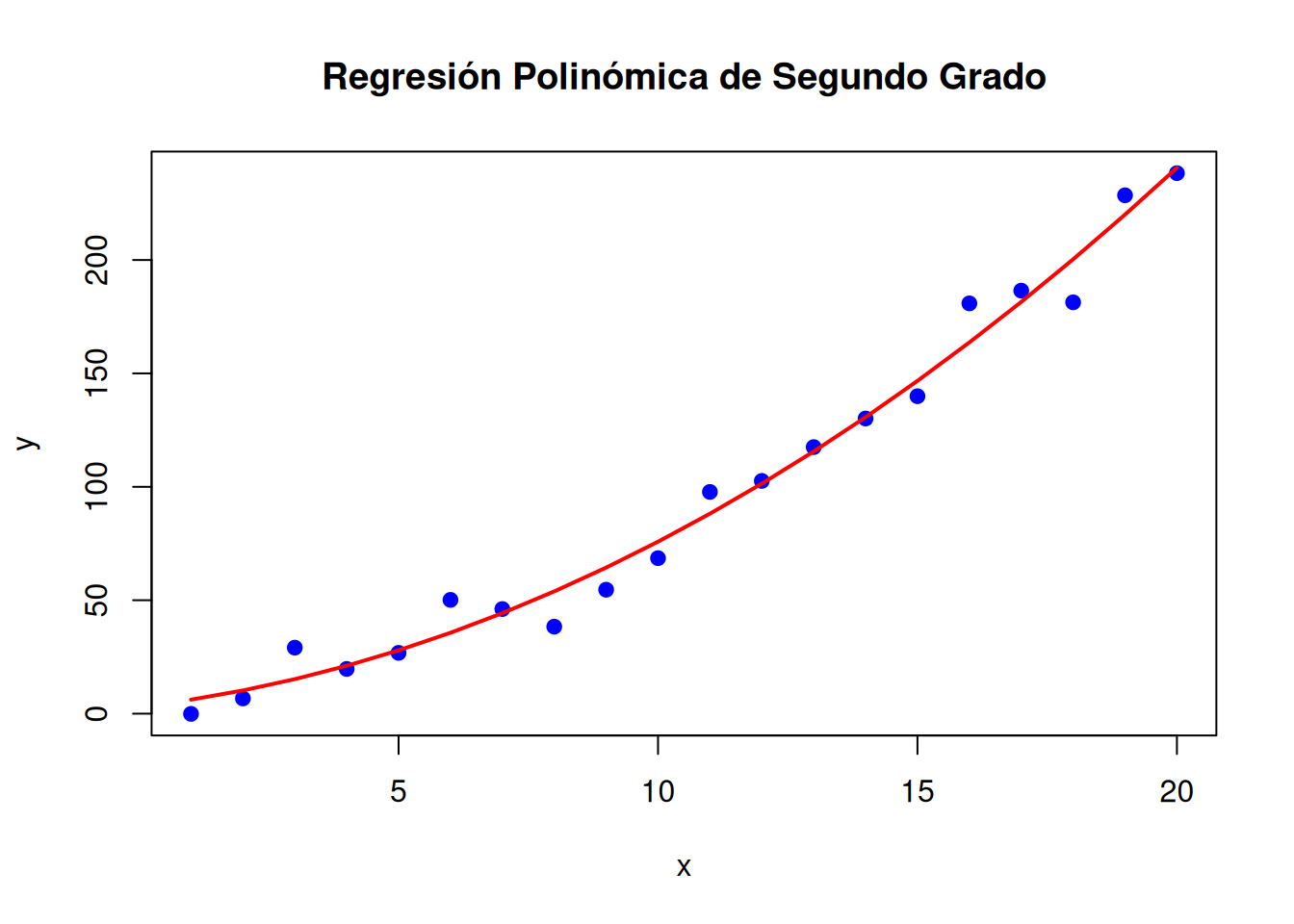
La regresión polinómica es una extensión de la regresión lineal que permite capturar relaciones no lineales mediante la inclusión de términos polinómicos (cuadráticos, cúbicos, etc.). Aunque sigue siendo un modelo lineal en los parámetros, la inclusión de potencias de las variables independientes permite ajustar curvas en lugar de líneas rectas.
Donde \(k\) es el grado del polinomio. A medida que aumenta el grado, el modelo se vuelve más flexible y puede ajustarse a relaciones más complejas.
Este tipo de modelos son capaces de capturar curvaturas suaves en los datos. Se trata de modelos fáciles de implementar y comprender, aunque la interpretación de los coeficientes asociados a altos grados del polinomio puede ser compleja. De hecho, exite un claro riesgo de sobreajuste cuando se utilizan polinomios de alto grado.
Ejemplo
# Datos simuladosset.seed(123)x <-1:20y <-3+2* x +0.5* x^2+rnorm(20, mean =0, sd =10)# Ajuste del modelo polinómico de grado 2modelo_polinomico <-lm(y ~poly(x, 2))summary(modelo_polinomico)
Call:
lm(formula = y ~ poly(x, 2))
Residuals:
Min 1Q Median 3Q Max
-18.9643 -6.4011 -0.8541 5.8504 17.2160
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 97.17 2.27 42.796 < 2e-16 ***
poly(x, 2)1 318.21 10.15 31.339 < 2e-16 ***
poly(x, 2)2 60.98 10.15 6.006 1.42e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10.15 on 17 degrees of freedom
Multiple R-squared: 0.9836, Adjusted R-squared: 0.9816
F-statistic: 509.1 on 2 and 17 DF, p-value: 6.778e-16
# Visualizaciónplot(x, y, main ="Regresión Polinómica de Segundo Grado", pch =19, col ="blue")lines(x, predict(modelo_polinomico), col ="red", lwd =2)
3.1.2 Modelos de Regresión Exponencial y Logarítmica
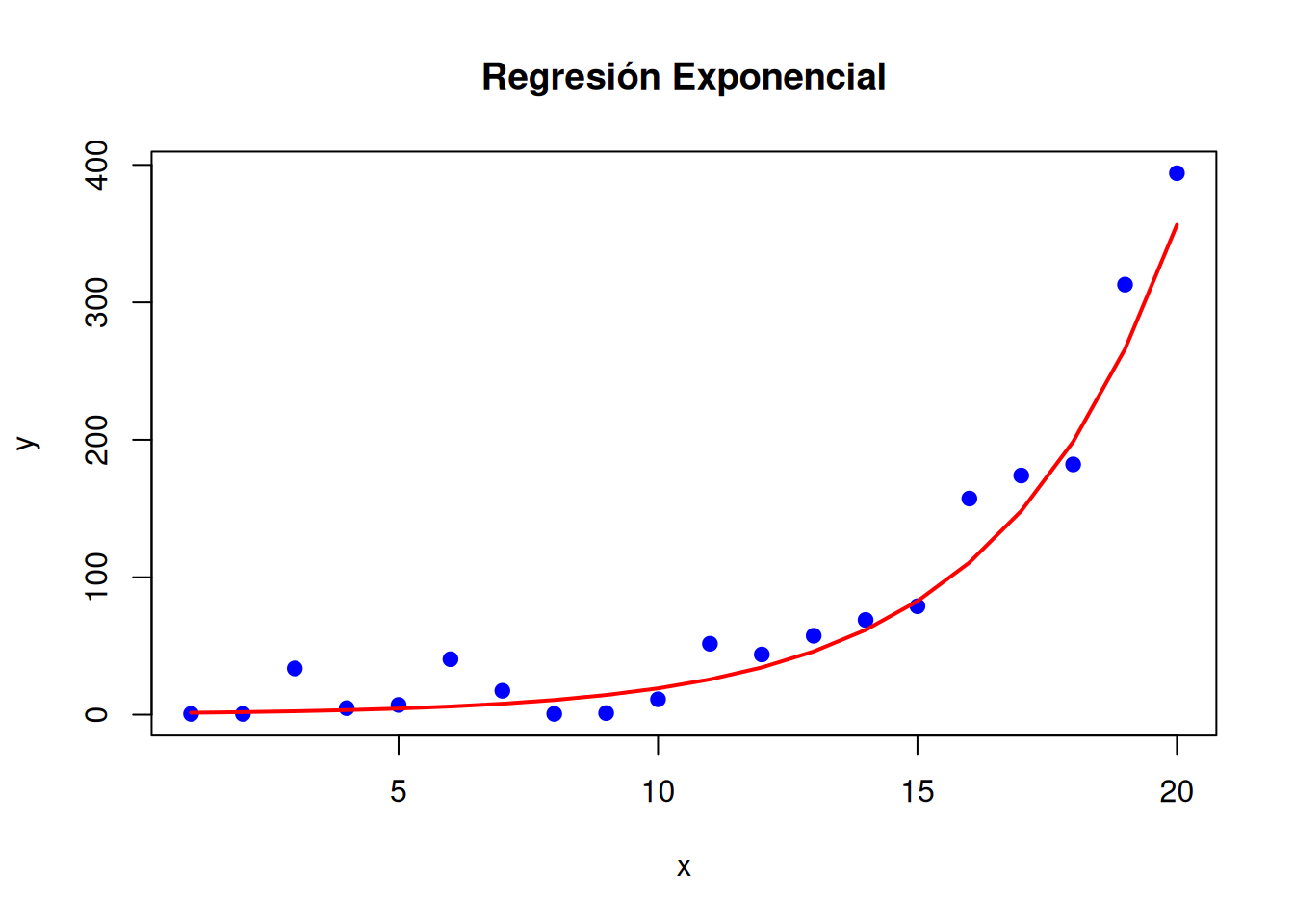
Cuando la relación entre la variable dependiente y la independiente sigue un crecimiento o decaimiento exponencial, o una relación logarítmica, los modelos lineales tradicionales no son suficientes. En estos casos, se pueden utilizar transformaciones exponenciales o logarítmicas.
Regresión Exponencial
Este modelo es útil cuando la variable dependiente crece (o decrece) a una tasa proporcional a su valor actual.
\[
Y = \beta_0 e^{\beta_1 X} + \varepsilon
\]
Este modelo puede linearizarse tomando el logaritmo de la variable dependiente:
\[
\log(Y) = \log(\beta_0) + \beta_1 X + \varepsilon
\]
Regresión Logarítmica
Útil cuando la tasa de cambio de la variable dependiente disminuye a medida que aumenta la variable independiente.
\[
Y = \beta_0 + \beta_1 \log(X) + \varepsilon
\]
Ejemplo
# Datos simulados para un modelo exponencialset.seed(123)x <-1:20y <-exp(0.3* x) +rnorm(20, mean =0, sd =20)# Asegurarse de que todos los valores de 'y' sean positivos para aplicar logaritmoy[y <=0] <-min(y[y >0]) *0.5# Reemplaza valores no positivos por un valor pequeño positivo# Ajuste del modelo exponencial (transformación logarítmica)modelo_exponencial <-lm(log(y) ~ x)# Resumen del modelosummary(modelo_exponencial)
Call:
lm(formula = log(y) ~ x)
Residuals:
Min 1Q Median 3Q Max
-2.9269 -0.1997 0.1612 0.3837 2.6104
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.02791 0.59598 0.047 0.963
x 0.29240 0.04975 5.877 1.45e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.283 on 18 degrees of freedom
Multiple R-squared: 0.6574, Adjusted R-squared: 0.6384
F-statistic: 34.54 on 1 and 18 DF, p-value: 1.45e-05
# Visualizaciónplot(x, y, main ="Regresión Exponencial", pch =19, col ="blue", ylab ="y", xlab ="x")# Predicciones para los mismos valores de xpredicciones <-predict(modelo_exponencial, newdata =data.frame(x = x))# Convertir predicciones a la escala original (exponencial inverso del log)lines(x, exp(predicciones), col ="red", lwd =2)
3.1.3 Regresión Spline y modelos basados en Segmentos
Los splines y los modelos segmentados son técnicas que permiten ajustar relaciones no lineales mediante la división de los datos en segmentos y el ajuste de funciones lineales o polinómicas en cada segmento. Estos métodos son especialmente útiles cuando la relación entre las variables cambia en diferentes rangos de los datos.
Modelos por tramos (Piecewise Regression)
En este enfoque, se ajustan diferentes regresiones lineales a distintos rangos de la variable independiente. A diferencia de los splines, las transiciones entre segmentos no necesariamente son suaves.
Estos modelos permiten capturar relaciones complejas con menor riesgo de sobreajuste en comparación con polinomios de alto grado.
Splines
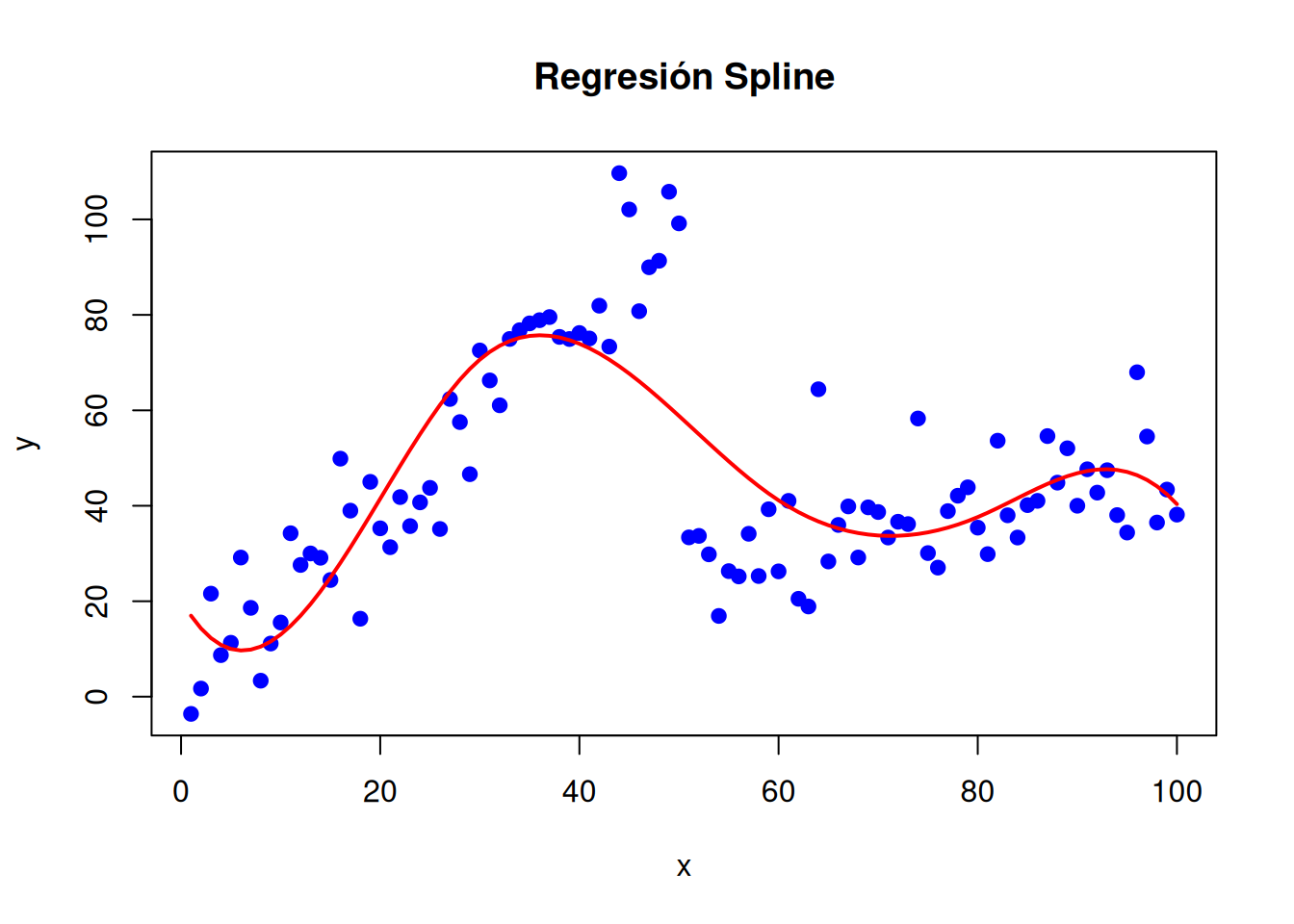
Los splines son una poderosa herramienta en el análisis de regresión para modelar relaciones no lineales entre variables. A diferencia de los modelos polinómicos tradicionales, que ajustan un solo polinomio a todos los datos, los splines permiten dividir el rango de la variable independiente en diferentes tramos y ajustar polinomios separados en cada uno de ellos. Esto proporciona mayor flexibilidad para capturar patrones complejos en los datos, sin los problemas de inestabilidad y sobreajuste que pueden surgir al utilizar polinomios de alto grado.
Un spline es una función que está compuesta por múltiples polinomios por tramos que se ajustan en diferentes intervalos del dominio de la variable independiente. Estos polinomios están conectados en puntos específicos llamados nudos (knots), que marcan el final de un tramo y el inicio de otro. La principal característica de los splines es que estos polinomios están diseñados para unirse de manera suave en los nudos, asegurando que la función resultante sea continua y, en muchos casos, que sus derivadas también sean continuas.
Elementos clave
Tramos: Intervalos del dominio de la variable independiente en los que se ajusta un polinomio distinto.
Nudos: Puntos donde los tramos se conectan. Los nudos definen la estructura del spline y determinan dónde la función puede cambiar de forma.
Continuidad: Los splines están construidos para que no haya saltos abruptos en la función o en sus derivadas en los nudos. Por ejemplo, un spline cúbico asegura continuidad en la función, la primera derivada (pendiente) y la segunda derivada (curvatura).
Tipos de Splines
Splines Lineales:
Se ajustan líneas rectas entre los nudos.
Garantizan la continuidad en los puntos de unión, pero no necesariamente en la pendiente.
Son simples, pero pueden generar ángulos abruptos en los nudos.
Splines Cuadráticos:
Se utilizan polinomios de segundo grado en cada tramo.
Aseguran continuidad en la función y en la pendiente, pero no en la curvatura.
Splines Cúbicos:
Los splines cúbicos son los más utilizados en análisis de regresión.
Utilizan polinomios de tercer grado en cada tramo.
Garantizan suavidad en la función y en sus primeras dos derivadas, lo que significa que la función es continua, su pendiente es continua y la curvatura es suave.
Evitan el sobreajuste que puede ocurrir con polinomios de alto grado, proporcionando un ajuste flexible sin perder estabilidad.
A diferencia de los polinomios globales de alto grado, los splines cúbicos pueden capturar patrones complejos sin oscilar de manera excesiva entre los puntos de datos.
Los splines permiten que el modelo se adapte localmente a diferentes patrones en distintos tramos del dominio de la variable independiente.
Splines Naturales:
Son una variante de los splines cúbicos que imponen condiciones adicionales en los extremos del rango de los datos, forzando la segunda derivada a ser cero en los extremos. Esto ayuda a evitar oscilaciones no deseadas fuera del rango de los datos.
El uso de splines en regresión permite modelar relaciones no lineales de manera flexible. La elección del número y la ubicación de los nudos es un aspecto fundamental del ajuste con splines:
Número de nudos: Demasiados nudos pueden llevar a un sobreajuste, mientras que muy pocos pueden no capturar adecuadamente la relación entre las variables. El uso de técnicas de validación cruzada puede ayudar a encontrar el equilibrio adecuado.
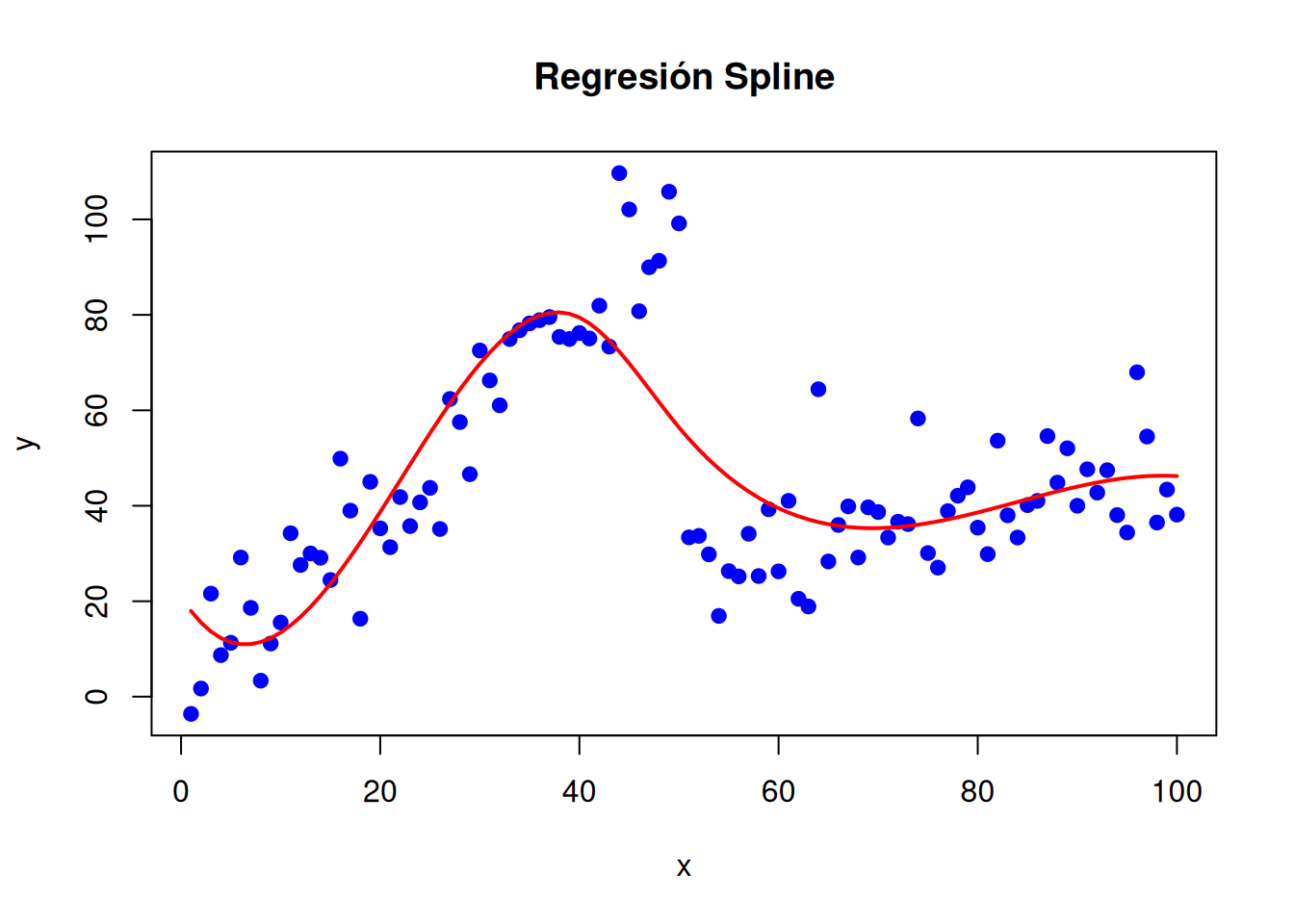
Ubicación de los nudos: Los nudos pueden colocarse en puntos equidistantes, en cuantiles de la variable independiente, o en puntos donde se sospecha que la relación entre las variables cambia. La colocación de nudos es clave para obtener un buen ajuste. Los nudos pueden seleccionarse de manera automática (por ejemplo, en los cuantiles de la variable independiente) o manualmente según el conocimiento del problema.
Aviso
A diferencia de la regresión lineal simple, los coeficientes de los splines no tienen una interpretación directa. El enfoque se centra en la forma general del ajuste en lugar de en el valor de los coeficientes individuales.
Ejemplo
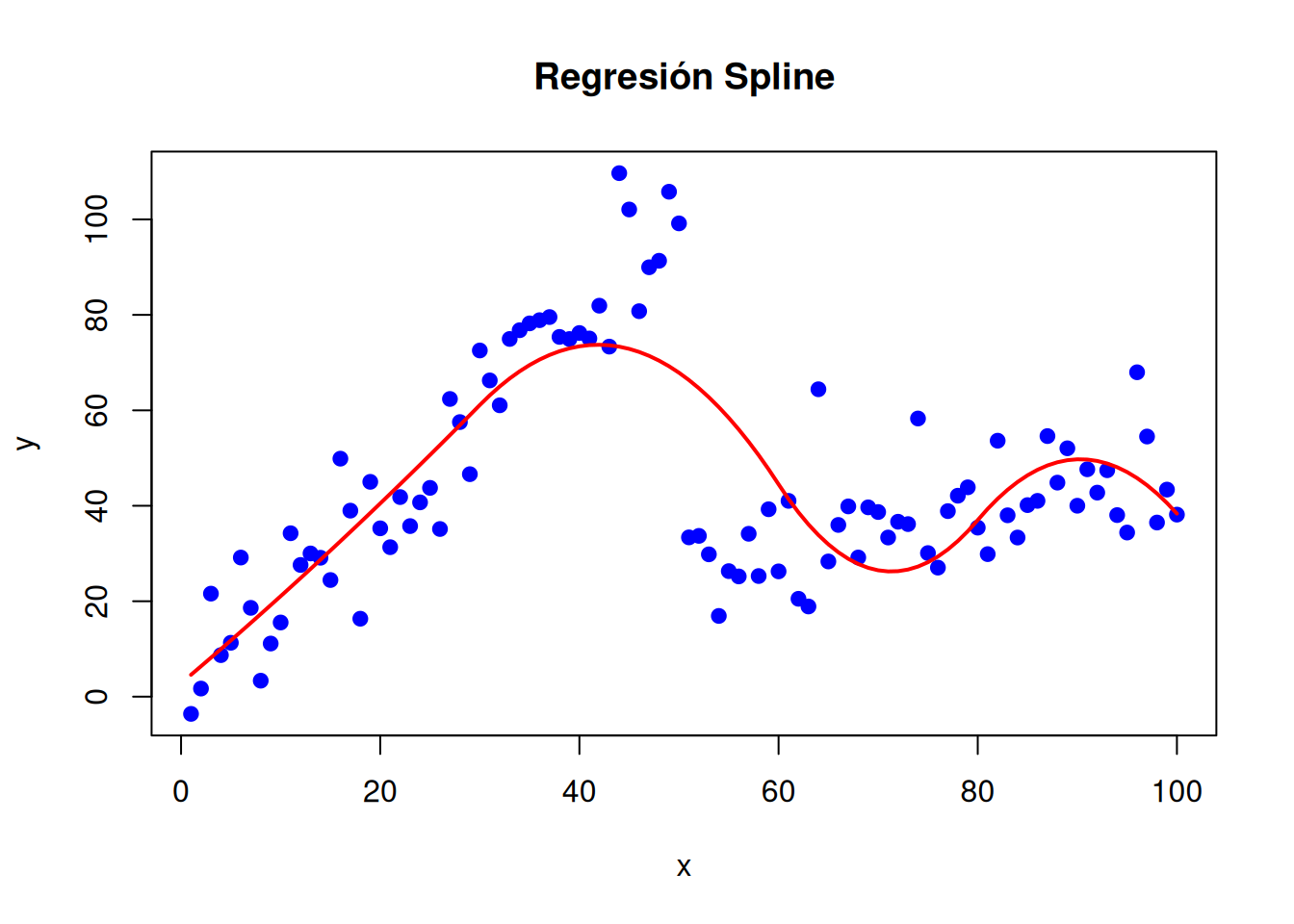
# Cargar librería para splineslibrary(splines)# Datos simuladosset.seed(123)x <-seq(1, 100, by =1)y <-ifelse(x <=50, 2* x +rnorm(100, 0, 10), 0.5* x +rnorm(100, 0, 10))# Ajuste del modelo splinemodelo_spline <-lm(y ~bs(x, knots =c(30, 60, 80)))# Visualizaciónplot(x, y, main ="Regresión Spline", pch =19, col ="blue")lines(x, predict(modelo_spline), col ="red", lwd =2)
# Cambio en la posición de los nodos# Ajuste del modelo splinemodelo_spline <-lm(y ~bs(x, knots =c(40, 50)))# Visualizaciónplot(x, y, main ="Regresión Spline", pch =19, col ="blue")lines(x, predict(modelo_spline), col ="red", lwd =2)
# Ajustamos un spline cuadrático # Ajuste del modelo splinemodelo_spline <-lm(y ~bs(x, degree=2, knots =c(30, 60, 80)))# Visualizaciónplot(x, y, main ="Regresión Spline", pch =19, col ="blue")lines(x, predict(modelo_spline), col ="red", lwd =2)
3.2 Transformación de variables
En el análisis de datos y la construcción de modelos estadísticos, no siempre es posible capturar adecuadamente la relación entre las variables independientes y la variable dependiente utilizando modelos lineales en su forma original. Aquí es donde entran en juego las transformaciones de variables, que permiten modificar la estructura de los datos para mejorar el ajuste del modelo, cumplir con los supuestos de la regresión y, en muchos casos, facilitar la interpretación.
Las transformaciones de variables son una herramienta fundamental para mejorar el rendimiento y la precisión de los modelos estadísticos. Estas transformaciones pueden aplicarse tanto a la variable dependiente como a las variables independientes.
Objetivos
Linearizar relaciones no lineales:
Muchas relaciones entre variables no son lineales en su forma original. Aplicar una transformación adecuada puede convertir una relación no lineal en lineal, permitiendo el uso de técnicas de regresión lineal. Por ejemplo, una relación exponencial \[Y = \beta_0 e^{\beta_1 X}\] puede linearizarse tomando el logaritmo de \(Y\): \[
\log(Y) = \log(\beta_0) + \beta_1 X
\]
Corregir problemas de heterocedasticidad:
La regresión lineal asume que los errores tienen varianza constante (homocedasticidad). Sin embargo, en la práctica, es común encontrar datos con heterocedasticidad (la varianza de los errores cambia con el nivel de la variable independiente). Las transformaciones pueden ayudar a estabilizar la varianza. Por ejemplo, transformar la variable dependiente \(Y\) usando un logaritmo o una raíz cuadrada puede reducir la heterocedasticidad.
Normalizar la distribución de los errores:
La regresión lineal también asume que los errores están normalmente distribuidos. Las transformaciones pueden ayudar a que los residuos del modelo se ajusten mejor a una distribución normal, lo que mejora la validez de los intervalos de confianza y las pruebas de hipótesis.
Reducir la influencia de valores atípicos:
Algunas transformaciones pueden disminuir la influencia de los valores atípicos en el modelo, haciendo que el ajuste sea más robusto.
Mejorar la interpretabilidad del modelo:
Aunque algunas transformaciones pueden complicar la interpretación directa de los coeficientes, otras pueden facilitar el entendimiento de la relación entre variables (por ejemplo, tasas de crecimiento constantes).
3.2.1 Tipos de transformaciones comunes
Existen diversas transformaciones que pueden aplicarse a los datos según el problema que se desea abordar. A continuación, se describen las transformaciones más utilizadas en el análisis de regresión.
Transformación Logarítmica (\(\log\))
Se emplea para linearizar relaciones exponenciales, reducir la heterocedasticidad, y estabilizar la varianza: - \[ Y = \log(Y) \] o \[ X = \log(X) \]
Es una transformación adecuada cuando la variable tiene una distribución sesgada a la derecha o cuando el efecto marginal disminuye con el valor de la variable (Ingresos, crecimiento poblacional, y tasas de interés, etc).
Ejemplo
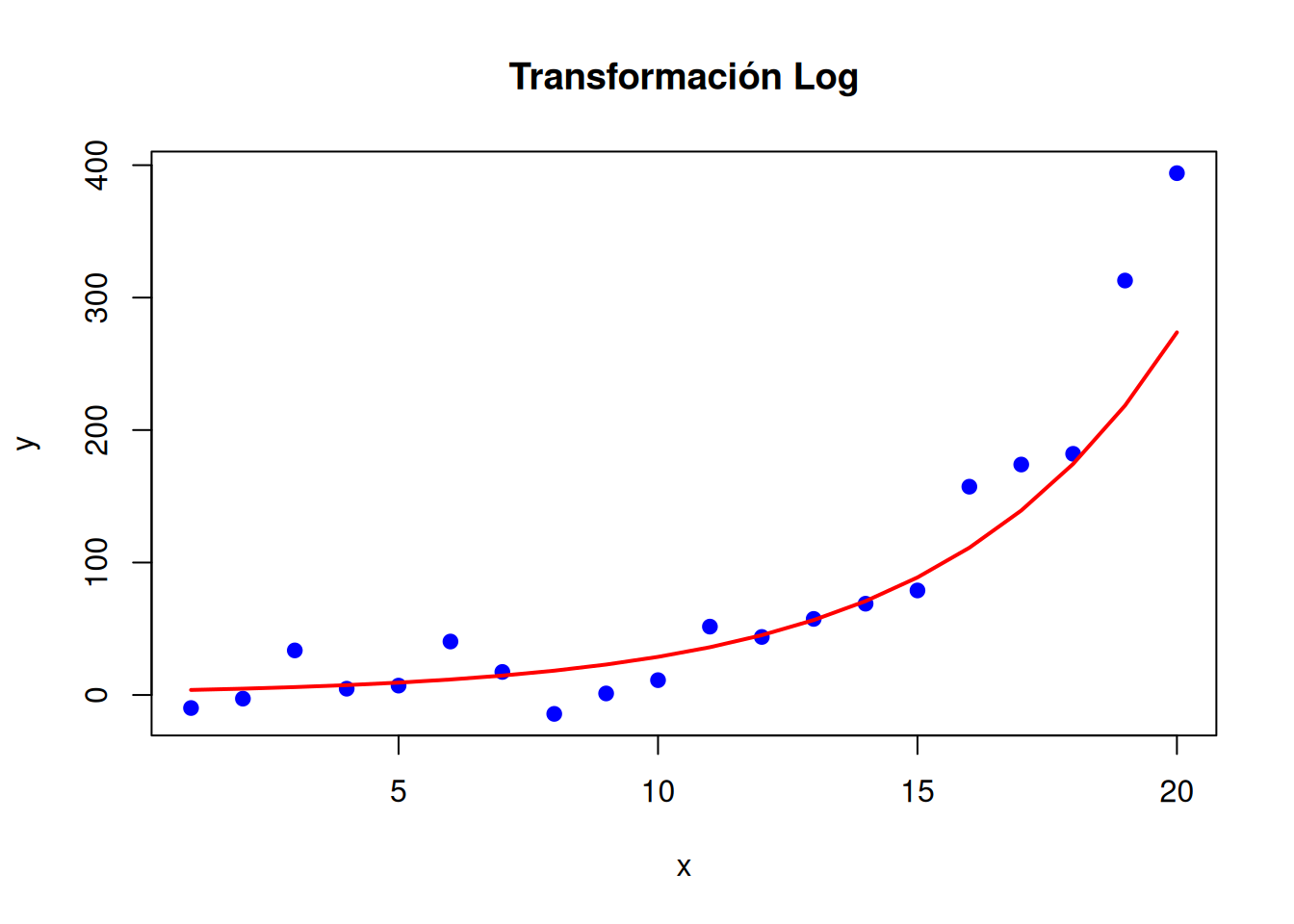
# Datos simulados con crecimiento exponencialset.seed(123)x <-1:20y <-exp(0.3* x) +rnorm(20, mean =0, sd =20)# Transformación logarítmica para linearizar la relaciónmodelo_log <-lm(log(y) ~ x)
Warning in log(y): Se han producido NaNs
summary(modelo_log)
Call:
lm(formula = log(y) ~ x)
Residuals:
Min 1Q Median 3Q Max
-3.00071 -0.11760 0.04277 0.35876 1.73316
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.10652 0.59757 1.852 0.083853 .
x 0.22528 0.04655 4.839 0.000217 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.011 on 15 degrees of freedom
(3 observations deleted due to missingness)
Multiple R-squared: 0.6096, Adjusted R-squared: 0.5835
F-statistic: 23.42 on 1 and 15 DF, p-value: 0.0002166
# Visualizaciónplot(x, y, main ="Transformación Log", pch =19, col ="blue", ylab ="y", xlab ="x")# Predicciones para los mismos valores de xpredicciones <-predict(modelo_log, newdata =data.frame(x = x))# Convertir predicciones a la escala original (exponencial inverso del log)lines(x, exp(predicciones), col ="red", lwd =2)
Transformación de Raíz Cuadrada (\(\sqrt{}\))
Se emplea para reducir la heterocedasticidad, especialmente cuando la varianza aumenta linealmente con la media: \[Y = \sqrt{Y}\] o \[X = \sqrt{X}\]
Se emplea comúnmente en conteos de eventos o variables positivas (número de llamadas, defectos, etc.).
Ejemplo
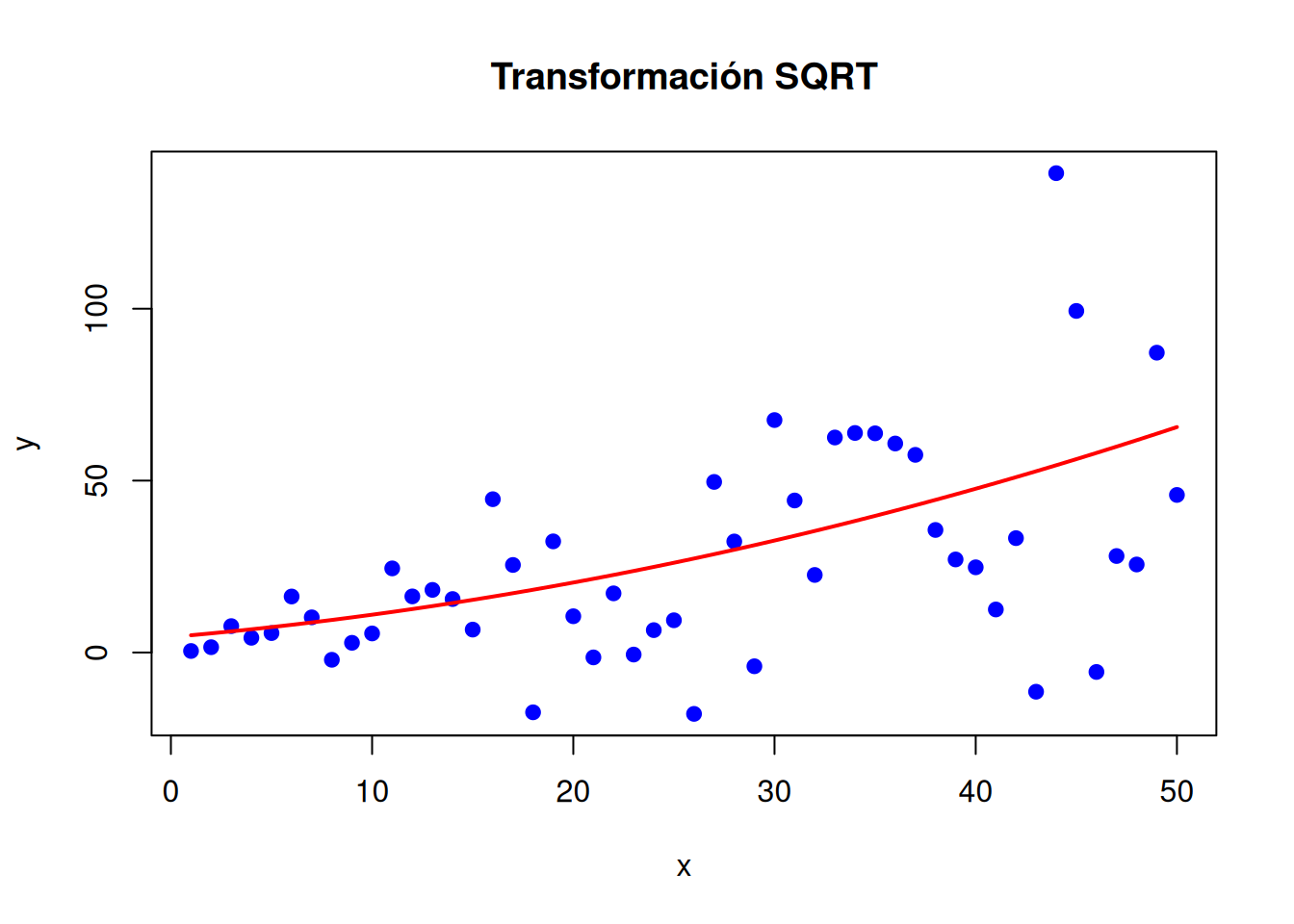
# Datos simulados con variabilidad crecienteset.seed(123)x <-1:50y <- x +rnorm(50, mean =0, sd = x)# Aplicando raíz cuadrada a la variable dependientemodelo_sqrt <-lm(sqrt(y) ~ x)
Warning in sqrt(y): Se han producido NaNs
summary(modelo_sqrt)
Call:
lm(formula = sqrt(y) ~ x)
Residuals:
Min 1Q Median 3Q Max
-3.4838 -1.3312 0.1822 1.3441 4.4278
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.12028 0.53305 3.978 0.000284 ***
x 0.11955 0.01819 6.574 7.39e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.752 on 40 degrees of freedom
(8 observations deleted due to missingness)
Multiple R-squared: 0.5193, Adjusted R-squared: 0.5073
F-statistic: 43.22 on 1 and 40 DF, p-value: 7.387e-08
# Visualizaciónplot(x, y, main ="Transformación SQRT", pch =19, col ="blue", ylab ="y", xlab ="x")# Predicciones para los mismos valores de xpredicciones <-predict(modelo_sqrt, newdata =data.frame(x = x))# Convertir predicciones a la escala originallines(x, predicciones^2, col ="red", lwd =2)
Transformación Inversa (\(\frac{1}{X}\))
Se emplea la tranformación inversa para modelar relaciones donde el efecto de la variable independiente disminuye rápidamente. \[ Y = \frac{1}{X} \]
Es especialmente útil cuando se espera que un aumento en \(X\) tenga un efecto decreciente en \(Y\) (Relaciones físicas como la ley de la gravitación, velocidad vs. tiempo en fricción, etc).
Ejemplo
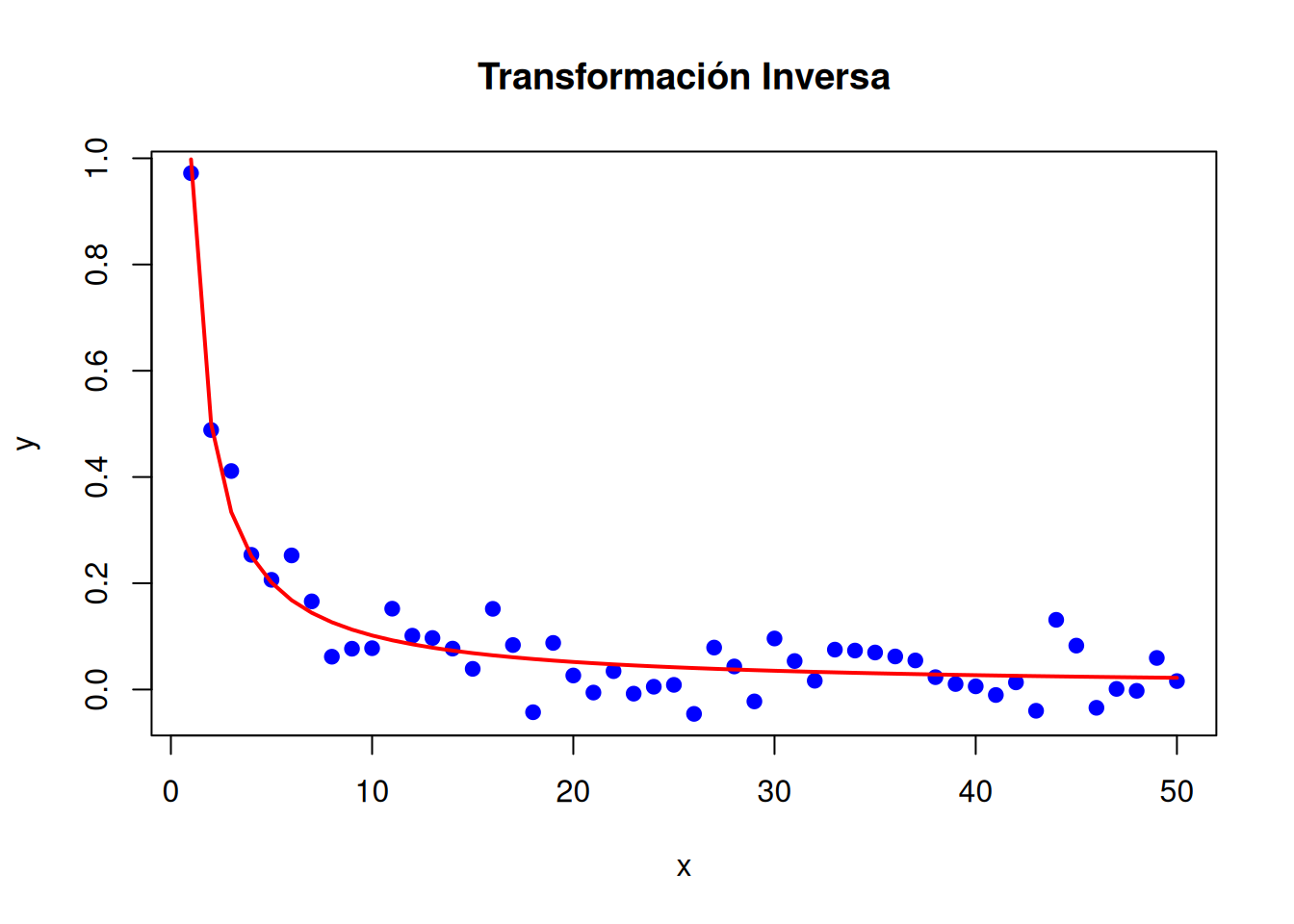
# Datos simulados con relación inversaset.seed(123)x <-1:50y <-1/ x +rnorm(50, mean =0, sd =0.05)# Ajuste del modelo con transformación inversamodelo_inverso <-lm(y ~I(1/x))summary(modelo_inverso)
Call:
lm(formula = y ~ I(1/x))
Residuals:
Min 1Q Median 3Q Max
-0.100193 -0.028703 -0.005628 0.033009 0.106450
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.002092 0.007633 0.274 0.785
I(1/x) 0.995869 0.042338 23.522 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.04677 on 48 degrees of freedom
Multiple R-squared: 0.9202, Adjusted R-squared: 0.9185
F-statistic: 553.3 on 1 and 48 DF, p-value: < 2.2e-16
# Visualizaciónplot(x, y, main ="Transformación Inversa", pch =19, col ="blue", ylab ="y", xlab ="x")# Predicciones para los mismos valores de xpredicciones <-predict(modelo_inverso, newdata =data.frame(x = x))# Convertir predicciones a la escala originallines(x, predicciones, col ="red", lwd =2)
3.2.2 Transformación de Box-Cox
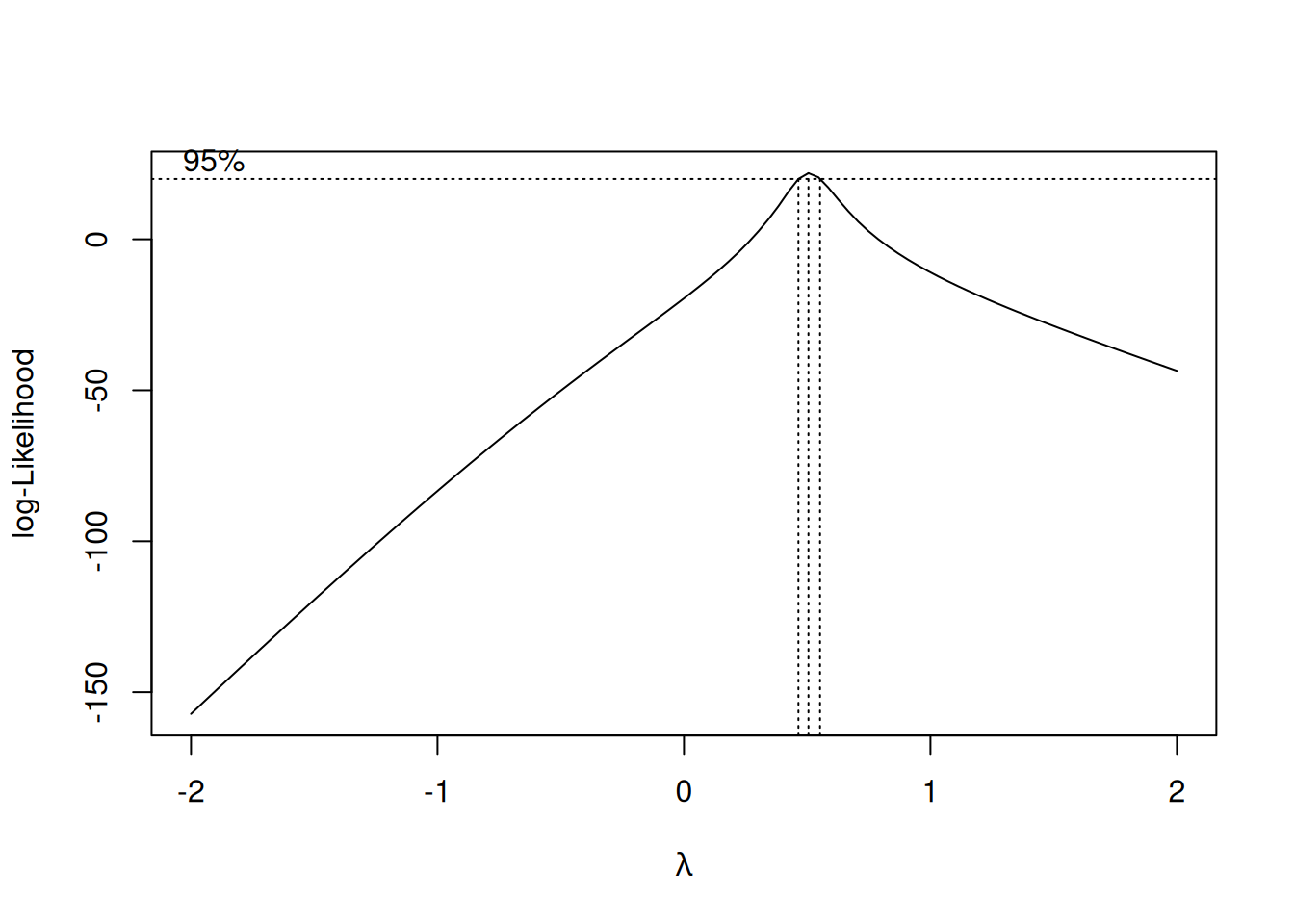
La transformación de Box-Cox es un método que busca automáticamente la mejor transformación para estabilizar la varianza y aproximar la normalidad de los errores. La transformación se define como:
Se emplea para encontrar la transformación óptima para los datos. Se utiliza cuando no está claro qué transformación aplicar. Por ejemplo, en caso de variables continuas con varianza no constante o distribución no normal.
Ejemplo
# Cargar librería para Box-Coxlibrary(MASS)# Datos simuladosset.seed(123)x <-1:20y <- x^2+rnorm(20, mean =0, sd =5)# Verificar si hay valores negativosmin(y)
[1] -1.802378
# Si hay valores negativos, sumar una constante para que todos los valores sean positivosif (min(y) <=0) { y <- y +abs(min(y)) +1# Desplaza todos los valores para que sean positivos}# Ajuste de un modelo lineal simplemodelo_bc <-lm(y ~ x)# Aplicación de la transformación de Box-Coxboxcox(modelo_bc)
La gráfica de Box-Cox mostrará el valor óptimo de \(\lambda\), que indica la mejor transformación para los datos.
3.2.3 Consideracione sobre las transformaciones
Antes de aplicar transformaciones, es importante diagnosticar si realmente son necesarias. Existen varias herramientas para identificar problemas en los datos que pueden solucionarse con transformaciones:
Gráficos de Dispersión: Visualizar la relación entre la variable dependiente y las independientes puede revelar patrones no lineales o heterocedasticidad.
Análisis de Residuos: Un gráfico de los residuos frente a los valores ajustados debe mostrar una distribución aleatoria. Patrones sistemáticos o “abanicos” indican la necesidad de transformación. El gráfico de QQ-Plot de los residuos ayuda a evaluar la normalidad.
Pruebas Estadísticas: Pruebas de normalidad como Shapiro-Wilk para los residuos. Pruebas de heterocedasticidad como Breusch-Pagan.
Si bien las transformaciones pueden mejorar el ajuste del modelo, también pueden afectar la interpretación de los coeficientes. Es importante tener en cuenta cómo cambia el significado de los resultados:
Transformaciones en la variable dependiente:
Si aplicas \(\log(Y)\), los coeficientes representan cambios proporcionales en \(Y\).
Si aplicas \(\sqrt{Y}\), los coeficientes representan la tasa de cambio en la raíz cuadrada de \(Y\).
Transformaciones en la variable independiente:
Si transformas \(X\) con \(\log(X)\), los coeficientes indican cómo cambia \(Y\) por cada incremento porcentual en \(X\).
Si transformas \(X\) con \(\frac{1}{X}\), los coeficientes representan el cambio en \(Y\) por cada unidad de disminución en \(X\).
Revertir Transformaciones para Interpretación: Después de ajustar un modelo, es posible transformar las predicciones de nuevo a la escala original para facilitar la interpretación.
3.3 Ingeniería de características
La ingeniería de características es el arte y la ciencia de transformar los datos brutos en representaciones que faciliten el aprendizaje y mejoren la capacidad predictiva de los modelos. Consiste en el proceso de crear, transformar y seleccionar las variables que se utilizan en un modelo para mejorar su rendimiento. Una característica bien diseñada puede hacer que un modelo simple supere a modelos más complejos, mientras que características irrelevantes o mal definidas pueden degradar significativamente la calidad del análisis. Este proceso incluye:
Creación de nuevas variables a partir de las existentes.
Transformación de variables para mejorar su distribución o relación con la variable objetivo.
Selección de las características más relevantes, eliminando aquellas que no aportan valor o introducen ruido.
Preparación de datos para modelos específicos, asegurando que las variables cumplan con los requisitos del algoritmo (por ejemplo, escalado, normalización o codificación).
3.3.1 Creación de nuevas variables
Una de las tareas más importantes en la ingeniería de características es la creación de nuevas variables que puedan capturar relaciones complejas entre las variables independientes y la variable objetivo.
Las interacciones entre variables permiten capturar relaciones no lineales entre las variables al considerar cómo el efecto de una variable puede depender del valor de otra. Si se dispone de dos variables \(X_i\) y \(X_j\), es posible crear una nueva variable de interacción $X_{} = X_i X_j $.
Ejemplo
# Ejemplo en R de interacción de variablesset.seed(123)X1 <-rnorm(100)X2 <-rnorm(100)Y <-3+2* X1 +4* X2 +1.5* X1 * X2 +rnorm(100)# Crear variable de interacciónX_interaccion <- X1 * X2# Ajustar modelo con interacciónmodelo_interaccion <-lm(Y ~ X1 + X2 + X_interaccion)summary(modelo_interaccion)
Call:
lm(formula = Y ~ X1 + X2 + X_interaccion)
Residuals:
Min 1Q Median 3Q Max
-1.8719 -0.6777 -0.1086 0.5897 2.3166
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.14098 0.09578 32.80 <2e-16 ***
X1 1.90719 0.10834 17.60 <2e-16 ***
X2 4.03434 0.09881 40.83 <2e-16 ***
X_interaccion 1.65911 0.11449 14.49 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9468 on 96 degrees of freedom
Multiple R-squared: 0.953, Adjusted R-squared: 0.9516
F-statistic: 649.2 on 3 and 96 DF, p-value: < 2.2e-16
Tal y como estudiamos cuando tratamos el tema de regresión polinómica, agregar términos polinómicos permite capturar relaciones no lineales al incluir potencias de las variables independientes. Por ejemplo, para una variable \(X\), se puede crear \(X^2\), \(X^3\), etc.
Ejemplo
# Datos simuladosx <-1:20y <-5+2* x +0.5* x^2+rnorm(20, mean =0, sd =5)# Incluir término cuadrático en el modelomodelo_polinomico <-lm(y ~ x +I(x^2))summary(modelo_polinomico)
Call:
lm(formula = y ~ x + I(x^2))
Residuals:
Min 1Q Median 3Q Max
-9.9235 -2.9142 0.6081 3.0085 9.6944
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.49742 4.18141 -0.119 0.90670
x 2.85574 0.91705 3.114 0.00631 **
I(x^2) 0.47433 0.04242 11.182 2.94e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.62 on 17 degrees of freedom
Multiple R-squared: 0.9953, Adjusted R-squared: 0.9947
F-statistic: 1792 on 2 and 17 DF, p-value: < 2.2e-16
Crear combinaciones simples de variables puede capturar relaciones ocultas en los datos. Por ejemplo:
Sumas o diferencias: \(X_{\text{nuevo}} = X_1 + X_2\)
Ratios: \(X_{\text{ratio}} = \frac{X_1}{X_2}\)
Variables categóricas combinadas: Fusionar categorías relacionadas en una nueva variable. Deben ser categorías que, desde un punto de vista del dominio de aplicación, tenga sentido combinar.
3.3.2 Selección y Reducción de variables
Una vez que se han creado nuevas características, es importante seleccionar las que son más relevantes para el modelo y eliminar aquellas que no aportan valor o introducen ruido.
Se trató con detalle estos conceptos en el tema anterior. Planteamos un ejemplo de selección Stepwise.
Ejemplo
# Datos simuladosset.seed(123)X1 <-rnorm(100)X2 <-rnorm(100)X3 <-rnorm(100)Y <-3+2* X1 +4* X2 +rnorm(100)# Modelo completo con todas las variablesmodelo_completo <-lm(Y ~ X1 + X2 + X3)# Selección de variables usando stepwisemodelo_seleccionado <-step(modelo_completo, direction ="both")
Call:
lm(formula = Y ~ X1 + X2)
Residuals:
Min 1Q Median 3Q Max
-2.47672 -0.67285 0.09839 0.70676 2.62566
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.9729 0.1059 28.08 <2e-16 ***
X1 1.9522 0.1155 16.91 <2e-16 ***
X2 4.0449 0.1090 37.11 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.048 on 97 degrees of freedom
Multiple R-squared: 0.943, Adjusted R-squared: 0.9418
F-statistic: 802.3 on 2 and 97 DF, p-value: < 2.2e-16
Recordemos que los métodos de regularización, estudiados en el tema 2, no solo ajustan el modelo, sino que también penalizan la complejidad, lo que ayuda a eliminar variables irrelevantes.
3.3.3 Escalado y Normalización de Variables
Muchos algoritmos de aprendizaje automático, como la regresión, las redes neuronales y los métodos basados en distancia (k-NN, SVM), son sensibles a la escala de las variables. Por lo tanto, es fundamental escalar o normalizar los datos para garantizar que todas las variables contribuyan de manera equitativa al modelo.
Estandarización (Z-Score Normalization)
La estandarización consiste en restar la media y dividir por la desviación estándar, lo que produce variables con media cero y desviación estándar uno.
3.3.4 Técnicas avanzadas de Ingeniería de Características
Cuando se trabaja con grandes conjuntos de datos o con variables altamente correlacionadas, puede ser necesario aplicar técnicas más avanzadas para reducir la dimensionalidad y extraer características relevantes.
3.3.4.1 Análisis de Componentes Principales (PCA)
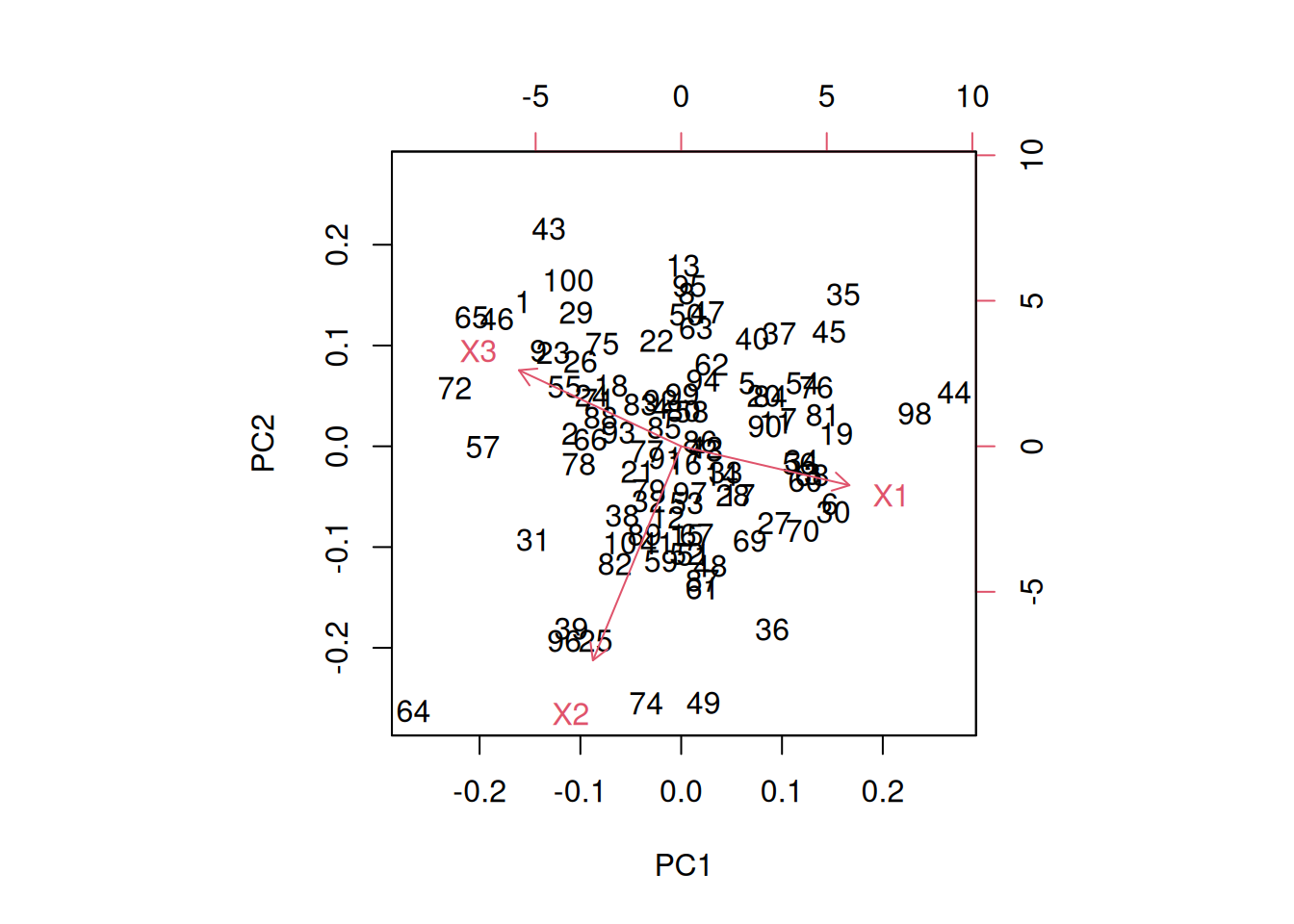
El Análisis de Componentes Principales (PCA) es una técnica de reducción de dimensionalidad que transforma un conjunto de variables correlacionadas en un conjunto más pequeño de componentes principales no correlacionados que explican la mayor parte de la varianza en los datos.
Aviso
Los detalles del Análisis de Componentes Principales son tratados en la asignatura de Aprendizaje Automático.
Ejemplo
# Datos simuladosset.seed(123)datos <-data.frame(X1, X2, X3)# Aplicar PCApca_resultado <-prcomp(datos, scale. =TRUE)# Visualización de los resultadossummary(pca_resultado)
Importance of components:
PC1 PC2 PC3
Standard deviation 1.0726 0.9900 0.9324
Proportion of Variance 0.3835 0.3267 0.2898
Cumulative Proportion 0.3835 0.7102 1.0000
biplot(pca_resultado)
3.3.4.2 Codificación de variables categóricas
Las variables categóricas deben convertirse en variables numéricas antes de ser utilizadas en muchos modelos. Esto puede hacerse mediante:
Codificación One-Hot
El One-Hot Encoding es una técnica utilizada en el preprocesamiento de datos para convertir variables categóricas en variables numéricas. Muchos algoritmos de aprendizaje automático y estadística (como la regresión lineal, redes neuronales y máquinas de soporte vectorial) requieren que las variables de entrada sean numéricas, ya que no pueden manejar directamente datos categóricos.
El One-Hot Encoding transforma cada categoría en una nueva columna binaria (0 o 1), donde el 1 indica la presencia de una categoría específica y el 0 su ausencia.
Supongamos que tienes una variable categórica llamada Color con tres categorías: Rojo, Verde, y Azul.
ID
Color
1
Rojo
2
Verde
3
Azul
4
Rojo
5
Verde
Con One-Hot Encoding, creamos una nueva columna para cada categoría única:
ID
Color_Rojo
Color_Verde
Color_Azul
1
1
0
0
2
0
1
0
3
0
0
1
4
1
0
0
5
0
1
0
Cada fila tiene un único 1 que indica la categoría correspondiente y ceros en las otras columnas. Esto convierte la información categórica en un formato que los algoritmos numéricos pueden procesar.
Propiedades Clave
Ventajas del One-Hot Encoding
Compatibilidad con algoritmos numéricos: La mayoría de los modelos de aprendizaje automático requieren variables numéricas. El One-Hot Encoding convierte las categorías en un formato adecuado.
Evita suposiciones erróneas A diferencia de la codificación ordinal, que asigna valores numéricos secuenciales a categorías (por ejemplo, Rojo = 1, Verde = 2, Azul = 3), el One-Hot Encoding no introduce un orden artificial entre las categorías. Esto es importante cuando no hay una jerarquía natural.
Mejora la Interpretabilidad en Modelos Lineales: En modelos como la regresión lineal, cada columna creada mediante One-Hot Encoding representa el efecto específico de esa categoría.
Desventajas del One-Hot Encoding
Incremento de la Dimensionalidad: Si la variable categórica tiene muchas categorías únicas (por ejemplo, países o códigos postales), el número de columnas creadas puede ser muy grande. Esto puede conducir a problemas de “curse of dimensionality” (la maldición de la dimensionalidad), afectando el rendimiento del modelo y aumentando el tiempo de computación.
Colinealidad Perfecta (Dummy Variable Trap): Al crear una columna para cada categoría, una de las columnas se puede representar como una combinación lineal de las demás. Esto puede causar problemas en modelos lineales. Para evitarlo, se elimina una categoría de referencia (típicamente la primera), lo que se conoce como evitar la trampa de las variables ficticias (dummy variable trap).
# Instalar y cargar la librería caretlibrary(caret)# Crear un data framedatos <-data.frame(ID =1:5, Color =c("Rojo", "Verde", "Azul", "Rojo", "Verde"))# Aplicar One-Hot Encoding usando dummyVarsdummy <-dummyVars(~ Color, data = datos)one_hot <-predict(dummy, newdata = datos)# Ver los resultadosprint(one_hot)
Cuando aplicamos One-Hot Encoding, el conjunto de variables resultantes puede generar colinealidad perfecta, lo que puede ser problemático en modelos lineales. Para evitarlo, es común eliminar una de las columnas creadas (que actuará como categoría de referencia).
# One-Hot Encoding con eliminación de una categoría (categoría de referencia)one_hot_ref <-model.matrix(~ Color, data = datos)[, -1] # Eliminar la primera columnaprint(one_hot_ref)
Esto elimina una columna (por ejemplo, ColorAzul) y permite que las otras columnas se interpreten en relación a la categoría de referencia.
3.3.4.3 Codificación Ordinal
La codificación ordinal es una técnica de preprocesamiento de datos utilizada para convertir variables categóricas en valores numéricos manteniendo el orden natural entre las categorías. A diferencia del One-Hot Encoding, que trata a todas las categorías como independientes y sin relación entre sí, la codificación ordinal es útil cuando las categorías tienen una jerarquía o un orden lógico.
En la codificación ordinal, a cada categoría se le asigna un número entero que refleja su posición o nivel en un orden determinado. Esto permite que los modelos estadísticos y de aprendizaje automático interpreten que algunas categorías son mayores o menores que otras, lo que es especialmente útil en variables que representan rangos, niveles o clasificaciones.
Supongamos que tenemos una variable llamada “Nivel de Satisfacción” con las siguientes categorías:
Nivel de Satisfacción
Muy Insatisfecho
Insatisfecho
Neutral
Satisfecho
Muy Satisfecho
Aquí, hay un orden lógico desde “Muy Insatisfecho” hasta “Muy Satisfecho”. Aplicando codificación ordinal, asignamos números que reflejen esta jerarquía:
Nivel de Satisfacción
Codificación Ordinal
Muy Insatisfecho
1
Insatisfecho
2
Neutral
3
Satisfecho
4
Muy Satisfecho
5
Propiedades clave
La codificación ordinal es adecuada cuando:
Las categorías tienen un orden natural: Ejemplos incluyen niveles educativos (Primaria, Secundaria, Universidad), calificaciones (Bajo, Medio, Alto), o satisfacción del cliente (Insatisfecho, Neutral, Satisfecho).
El modelo puede interpretar la relación de orden: Algunos algoritmos, como la regresión lineal o las máquinas de vectores soporte (SVM), pueden beneficiarse de la codificación ordinal si el orden es relevante para la variable objetivo.
Reducción de dimensionalidad: A diferencia del One-Hot Encoding, que puede crear muchas columnas para variables con múltiples categorías, la codificación ordinal mantiene la variable en una sola columna, lo que es más eficiente para conjuntos de datos grandes.
Ventajas y desventajas
Ventajas
Preserva la jerarquía de las categorías: Permite que el modelo entienda que ciertas categorías son mayores o menores que otras.
Reducción de la dimensionalidad: A diferencia del One-Hot Encoding, no aumenta el número de columnas, lo que reduce el riesgo de la maldición de la dimensionalidad.
Simplicidad Computacional: Es más eficiente en términos de almacenamiento y tiempo de computación, especialmente para variables con muchas categorías.
Desventajas
Riesgo de interpretación incorrecta del orden: Si la variable categórica no tiene un orden lógico, la codificación ordinal puede inducir al modelo a asumir relaciones que no existen. Por ejemplo, supongamos que tienes una variable Color con categorías Rojo, Verde, y Azul. Asignarles valores como Rojo = 1, Verde = 2, Azul = 3 podría inducir al modelo a pensar que Verde es “mayor” que Rojo y Azul es “mayor” que Verde, lo cual no tiene sentido en este contexto.
No Captura la Magnitud de la Diferencia: Aunque las categorías están ordenadas, la codificación ordinal no refleja la magnitud real de las diferencias entre categorías. Por ejemplo, la diferencia entre “Insatisfecho” y “Neutral” puede no ser la misma que entre “Satisfecho” y “Muy Satisfecho”.
Ejemplo
# Crear un data frame con una variable categórica ordinaldatos <-data.frame(ID =1:5,Satisfaccion =c("Muy Insatisfecho", "Insatisfecho", "Neutral", "Satisfecho", "Muy Satisfecho"))# Convertir la variable en un factor ordenadodatos$Satisfaccion_ordinal <-factor(datos$Satisfaccion, levels =c("Muy Insatisfecho", "Insatisfecho", "Neutral", "Satisfecho", "Muy Satisfecho"), ordered =TRUE)# Ver la estructura del factorstr(datos)
# Asignar valores numéricos a las categorías ordenadasdatos$Satisfaccion_codificada <-as.numeric(datos$Satisfaccion_ordinal)# Ver el resultadoprint(datos)
ID Satisfaccion Satisfaccion_ordinal Satisfaccion_codificada
1 1 Muy Insatisfecho Muy Insatisfecho 1
2 2 Insatisfecho Insatisfecho 2
3 3 Neutral Neutral 3
4 4 Satisfecho Satisfecho 4
5 5 Muy Satisfecho Muy Satisfecho 5
Podemos usar la variable codificada ordinalmente en un modelo de regresión para evaluar su impacto en una variable dependiente, como una puntuación de satisfacción general.
Ejemplo
# Simular una variable de respuesta (puntuación general)set.seed(123)datos$Puntuacion <-c(2, 4, 6, 8, 10) +rnorm(5, mean =0, sd =0.5)# Ajustar un modelo de regresión lineal usando la variable codificadamodelo_ordinal <-lm(Puntuacion ~ Satisfaccion_codificada, data = datos)# Resumen del modelosummary(modelo_ordinal)
Call:
lm(formula = Puntuacion ~ Satisfaccion_codificada, data = datos)
Residuals:
1 2 3 4 5
-0.2090 -0.1279 0.6826 -0.1455 -0.2002
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.1552 0.4640 -0.335 0.759968
Satisfaccion_codificada 2.0840 0.1399 14.896 0.000657 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4424 on 3 degrees of freedom
Multiple R-squared: 0.9867, Adjusted R-squared: 0.9822
F-statistic: 221.9 on 1 and 3 DF, p-value: 0.0006565
El modelo ajustará la relación entre la puntuación de satisfacción y el nivel de satisfacción codificado ordinalmente. El coeficiente de la variable Satisfaccion_codificada indicará cómo cambia la puntuación a medida que aumenta el nivel de satisfacción.
3.3.4.4 Diferencias entre Codificación Ordinal y One-Hot Encoding
Característica
Codificación Ordinal
One-Hot Encoding
Preserva el orden
Sí, refleja la jerarquía entre categorías.
No, trata cada categoría como independiente.
Aumenta la dimensionalidad
No, mantiene la variable en una sola columna.
Sí, crea una columna para cada categoría única.
Adecuado para
Variables con orden natural (ej. educación).
Variables sin orden (ej. color, género, ciudad).
Riesgo
Puede inducir al modelo a asumir relaciones falsas si no hay orden real.