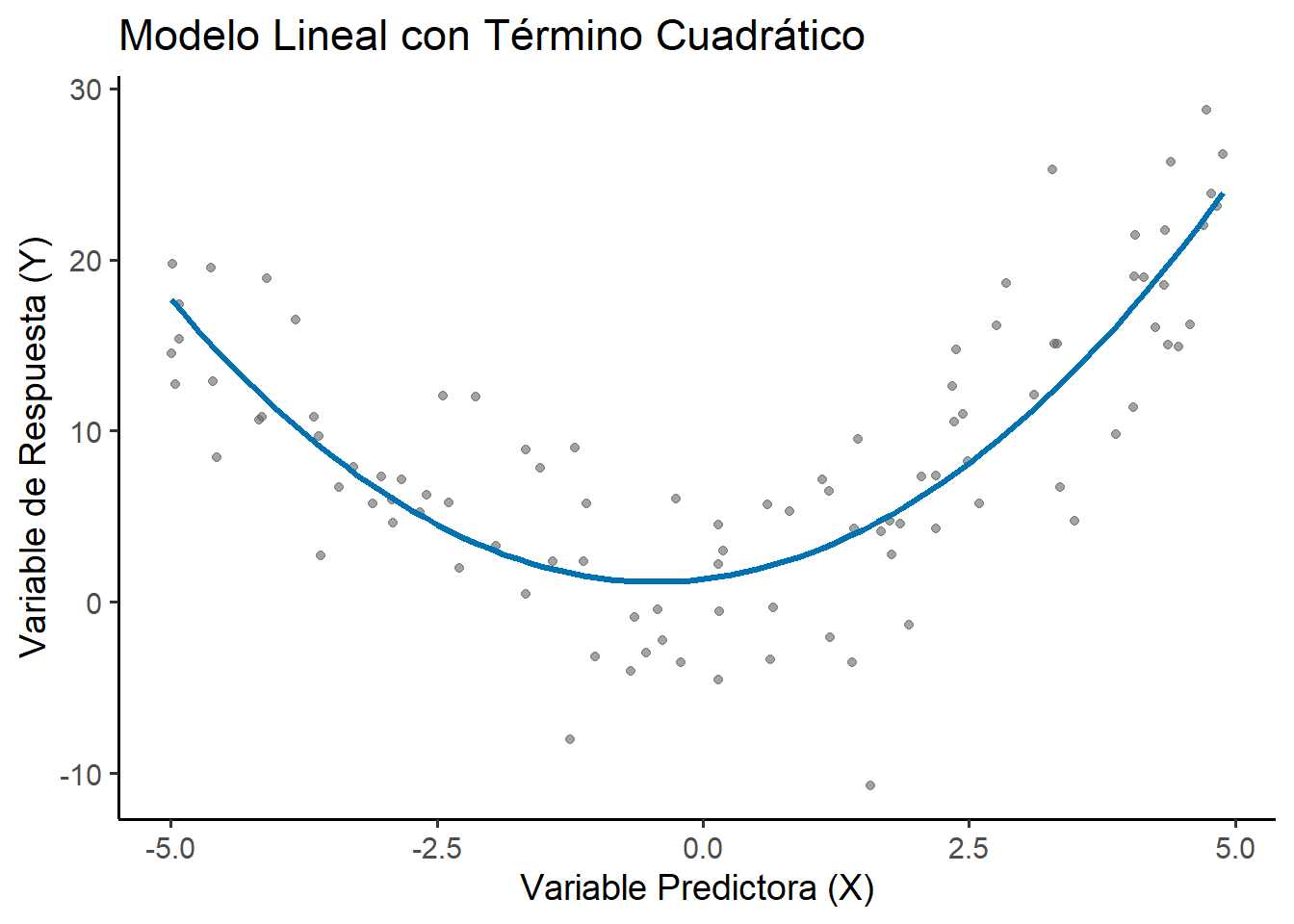
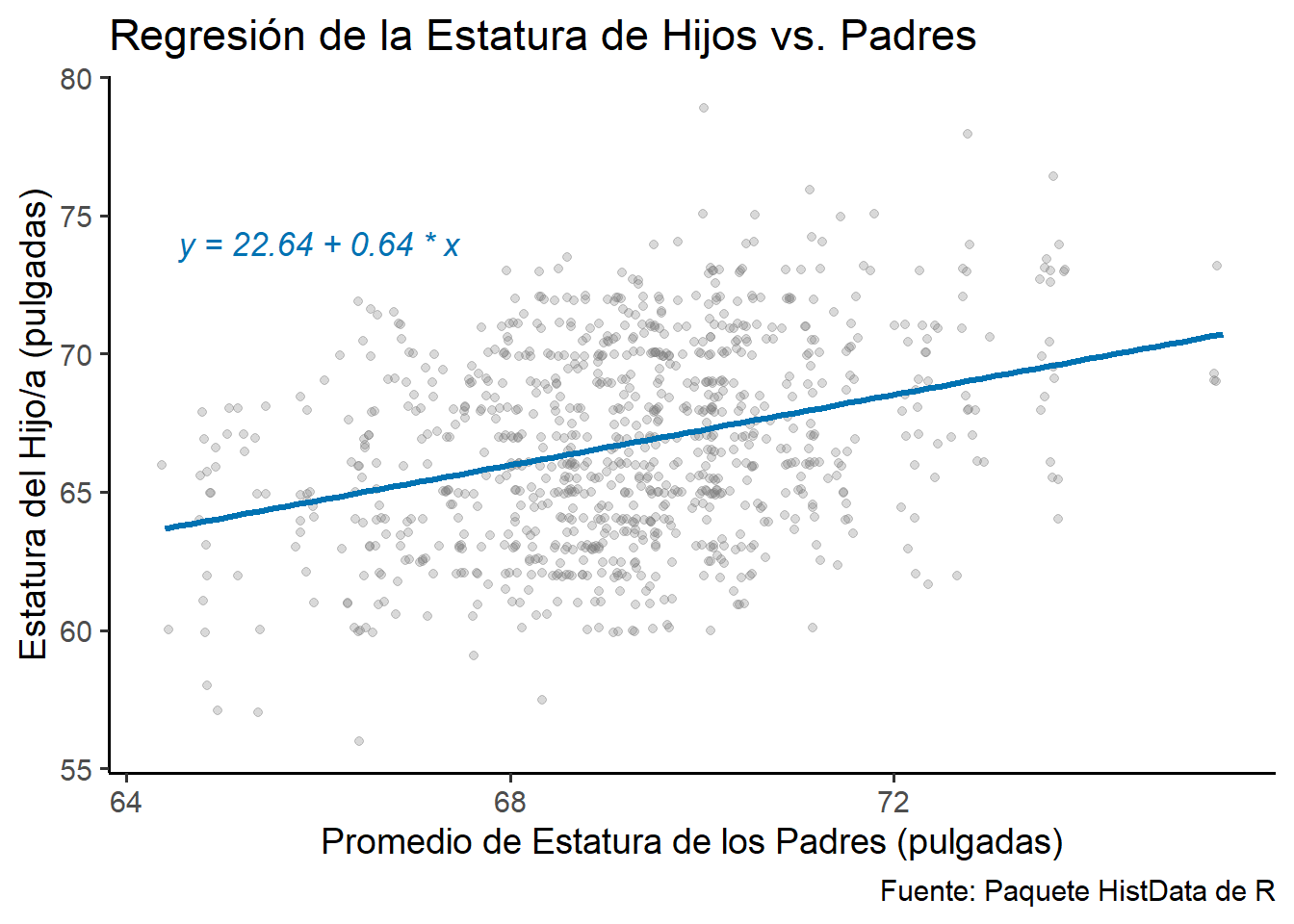
Este legado continúa evolucionando a un ritmo vertiginoso, con la inclusión de modelos jerárquicos y bayesianos, métodos no paramétricos y de machine learning como los árboles de regresión, y la adaptación de la regresión al análisis de datos masivos (big data). La regresión ha evolucionado desde una observación sobre la herencia biológica hasta convertirse en una de las herramientas más versátiles y poderosas del arsenal analítico moderno.
Bates, Douglas, Martin Mächler, Ben Bolker, y Steve Walker. 2015. «Fitting Linear Mixed-Effects Models Using lme4». Journal of Statistical Software 67 (1): 1-48.
Galton, Francis. 1886. «Regression towards mediocrity in hereditary stature». The Journal of the Anthropological Institute of Great Britain and Ireland 15: 246-63.
Harrell, Frank E., Jr. 2015. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. Second. Springer.
James, Gareth, Daniela Witten, Trevor Hastie, y Robert Tibshirani. 2021. An Introduction to Statistical Learning with Applications in R. Second. Springer.
Kutner, Michael H, Christopher J Nachtsheim, John Neter, y William Li. 2005. Applied linear statistical models. McGraw-hill.
Nelder, John Ashworth, y Robert WM Wedderburn. 1972. «Generalized linear models». Journal of the Royal Statistical Society Series A: Statistics in Society 135 (3): 370-84.
Pinheiro, José C., y Douglas M. Bates. 2000. Mixed-Effects Models in S and S-PLUS. New York: Springer.
Shmueli, Galit. 2010. «To Explain or to Predict?» Statistical Science 25 (3): 289-310.
Wood, Simon N. 2017. Generalized Additive Models: An Introduction with R. Second. Chapman; Hall/CRC.