4Ingeniería de características: transformaciones de variables e interacciones
En la práctica del análisis de datos, los datos en su estado bruto raramente están en la forma óptima para el modelado estadístico. La ingeniería de características es el proceso fundamental que transforma, combina y crea variables para maximizar la capacidad predictiva y la interpretabilidad de nuestros modelos (Kuhn y Johnson 2019; Zheng y Casari 2018).
Este proceso abarca tres áreas principales que exploraremos en profundidad:
Transformaciones de variables: Las transformaciones matemáticas nos permiten abordar múltiples problemas simultaneamente: linearizar relaciones no lineales, estabilizar la varianza (heterocedasticidad), aproximar la distribución de los errores a la normalidad, y reducir la influencia de valores atípicos. Dominar cuándo y cómo aplicar transformaciones logarítmicas, potenciales, Box-Cox o Yeo-Johnson es fundamental para optimizar nuestros modelos (Box y Cox 1964; Yeo y Johnson 2000).
Tratamiento de variables categóricas: Las variables categóricas requieren estrategias específicas de codificación que preserven la información relevante sin introducir supuestos erróneos. La elección entre codificación ordinal, one-hot encoding, o técnicas más avanzadas puede impactar significativamente el rendimiento del modelo (Potdar, Pardawala, y Pai 2017).
Interacciones entre variables: Las interacciones capturan cómo el efecto de una variable puede cambiar según el nivel de otra variable, revelando patrones que los efectos principales por sí solos no pueden detectar. Comprender los diferentes tipos de interacciones y sus aplicaciones es clave para modelar relaciones complejas en el mundo real (Jaccard y Turrisi 2003).
ImportanteObjetivos de aprendizaje
Al finalizar este capítulo, serás capaz de:
Identificar cuándo aplicar transformaciones específicas según el problema: linearización, heterocedasticidad, normalidad, o atípicos.
Aplicar transformaciones clásicas (logarítmica, potencial, inversa) y avanzadas (Box-Cox, Yeo-Johnson) de manera apropiada.
Interpretar modelos transformados, comprendiendo cómo cambia el significado de los coeficientes después de la transformación.
Codificar variables categóricas using ordinal encoding y one-hot encoding según la naturaleza de las categorías.
Crear e interpretar términos de interacción entre variables continuas, categóricas, y mixtas.
Aplicar ingeniería de características para crear nuevas variables predictivas mediante combinaciones, ratios y transformaciones.
4.1 Transformaciones de variables: propósitos y aplicaciones
En el análisis de datos y la construcción de modelos estadísticos, los datos en su forma original no siempre están preparados para obtener el máximo rendimiento de nuestros modelos. Las transformaciones de variables son herramientas fundamentales que nos permiten modificar la estructura matemática de nuestros datos para abordar problemas específicos y mejorar significativamente el ajuste del modelo (Box y Cox 1964; Carroll y Ruppert 1988).
La clave del éxito en las transformaciones está en diagnosticar correctamente el problema que enfrentamos y seleccionar la transformación apropiada. Cada transformación tiene propósitos específicos y consecuencias interpretativas que debemos comprender profundamente.
4.1.1 Diagnóstico: ¿Cuándo transformar?
El arte de las transformaciones no está en aplicarlas indiscriminadamente, sino en diagnosticar correctamente cuál es el problema que enfrentamos y seleccionar la transformación más apropiada para resolverlo. Un diagnóstico erróneo puede llevarnos a aplicar una transformación innecesaria o, peor aún, contraproducente que distorsione las relaciones reales en los datos.
La práctica común de “probar transformaciones hasta que mejore el ajuste” es metodológicamente peligrosa. Este enfoque de transformación por ensayo y error puede llevarnos a:
Sobreajuste: Optimizar el modelo para los datos específicos que tenemos, perdiendo capacidad de generalización.
Pérdida de interpretabilidad: Aplicar transformaciones complejas sin comprender su significado teórico.
Violación de supuestos: Resolver un problema creando otros nuevos (ej. transformar para normalidad pero introducir heterocedasticidad).
Sesgo de selección: Elegir la transformación que da los “mejores” resultados sin justificación teórica.
El proceso de diagnóstico debe ser sistemático y basado en evidencia visual y estadística. No basta con aplicar transformaciones porque “mejoran el R²”; debemos entender qué problema específico estamos resolviendo y cómo la transformación aborda ese problema desde una perspectiva teórica sólida.
Un enfoque metodológicamente sólido sigue estos principios:
Diagnóstico previo: Identificar problemas específicos mediante análisis visual y tests estadísticos antes de decidir transformar.
Justificación teórica: Cada transformación debe tener una base conceptual sólida. Por ejemplo, usar logaritmos para relaciones multiplicativas o raíz cuadrada para estabilizar varianza Poisson.
Evaluación integral: No solo considerar el ajuste estadístico, sino también la interpretabilidad, robustez y generalización del modelo transformado.
Validación posterior: Verificar que la transformación realmente resuelve el problema identificado sin crear nuevos problemas.
Parsimonia: Preferir la transformación más simple que resuelva efectivamente el problema (principio de Occam aplicado a transformaciones).
NotaRecordatorio: Diagnóstico de problemas en regresión lineal
Identificación de no linealidad: La no linealidad es uno de los problemas más comunes que enfrentamos en el modelado. Diagnóstico visual: gráficos de dispersión (Y vs. X), gráficos de componente + residuo (CPR plots), análisis de residuos vs. valores ajustados. Diagnóstico estadístico: Test de Ramsey RESET que evalúa si potencias de los valores ajustados mejoran significativamente el modelo.
Detección de heterocedasticidad: La heterocedasticidad (varianza no constante) viola supuestos fundamentales de la regresión lineal y sesga las inferencias estadísticas. Diagnóstico visual: gráfico de residuos vs. valores ajustados (patrón “embudo”), gráfico Scale-Location, residuos vs. variables predictoras individuales. Diagnóstico estadístico: Test de Breusch-Pagan (el más utilizado) y Test de White (más general).
Evaluación de normalidad de residuos: Aunque la normalidad no es crítica para estimación de coeficientes, sí es importante para inferencia estadística. Diagnóstico visual: histograma de residuos, QQ-plot de residuos. Diagnóstico estadístico: Test de Shapiro-Wilk (muestras pequeñas n<50) y Test de Jarque-Bera.
Detección de outliers y observaciones influyentes: Es fundamental distinguir entre outliers (valores extremos en Y) y observaciones influyentes (impacto en coeficientes). Outliers: boxplot de variable respuesta, residuos estudentizados, criterios |t\(_i\)| > 2. Observaciones influyentes: análisis de leverage, distancia de Cook, DFBETAS, DFFITS, con criterios específicos como h\(_i\) > 2p/n y D\(_i\) > 4/n. Las observaciones se clasifican en: normales, outliers no influyentes, influyentes sin ser outliers, y outliers influyentes.
4.2 Escalado y normalización: preparando variables para el análisis
Antes de aplicar transformaciones complejas, es fundamental asegurar que nuestras variables estén en escalas comparables. Aunque la regresión lineal ordinaria no requiere estrictamente el escalado de variables para obtener estimadores insesgados, el escalado se vuelve crítico para la interpretación y esencial en métodos avanzados de modelado.
En regresión múltiple, los coeficientes representan el cambio en Y por unidad de cambio en cada variable predictora. Cuando las variables tienen escalas muy diferentes, los coeficientes pierden comparabilidad directa. Una variable medida en miles de euros tendrá coeficientes numéricamente pequeños, mientras que una variable medida en porcentajes tendrá coeficientes grandes, independientemente de su importancia real en el modelo.
Esta disparidad de escalas genera problemas interpretativos fundamentales: comparar la “importancia” relativa de las variables se vuelve imposible basándose únicamente en la magnitud de los coeficientes. El escalado resuelve este problema permitiendo que los coeficientes estandarizados (beta coefficients) representen cambios en desviaciones estándar, facilitando comparaciones directas entre predictores y proporcionando una base sólida para evaluar la importancia relativa de cada variable.
NotaEscalado en métodos de regularización
En regresión con regularización (Ridge, Lasso), el problema se agrava dramáticamente. Las penalizaciones L1 y L2 afectan desproporcionadamente a variables con escalas grandes, llevando a regularización injusta donde variables con unidades grandes son penalizadas más severamente que variables con unidades pequeñas, independientemente de su relevancia predictiva. Esto puede resultar en selección de variables sesgada y estimadores subóptimos. Este tema se desarrollará en profundidad en el siguiente capítulo sobre métodos de regularización.
El escalado no es solo una cuestión técnica, sino una decisión metodológica que afecta directamente la interpretación y validez de nuestros resultados. La elección entre estandarización, normalización min-max, o escalado robusto debe basarse en las características de los datos y los objetivos del análisis, considerando siempre el impacto en la interpretabilidad de los resultados finales.
4.2.1 Estandarización (Z-Score)
La estandarización es la técnica de escalado más utilizada en estadística. Transforma cada variable para que tenga media cero y desviación estándar uno, preservando la forma de la distribución original.
Rango acotado: Todas las variables transformadas tienen el mismo rango [0,1].
Preserva relaciones: Las distancias relativas entre observaciones se mantienen.
Interpretación intuitiva: 0 representa el mínimo observado, 1 el máximo observado.
Cuándo usar normalización Min-Max:
Cuando necesitamos un rango específico (ej. entradas de redes neuronales).
Variables con distribuciones uniformes o sin outliers extremos.
Cuando la interpretación en términos de mínimo-máximo es relevante.
En algoritmos que requieren entradas en [0,1] (algunos métodos de ensemble).
Limitaciones:
Muy sensible a outliers: Un solo valor extremo puede comprimir toda la distribución.
No preserva la normalidad: Una distribución normal se vuelve uniforme tras Min-Max.
4.2.3 Escalado robusto
Para datos con outliers significativos, el escalado robusto utiliza la mediana y el rango intercuartílico (IQR) en lugar de la media y desviación estándar:
Este método es menos sensible a valores extremos y preserva mejor la estructura de los datos en presencia de outliers.
TipEjemplo comparativo: Escalado de variables
# Generar datos de ejemplo con diferentes escalasset.seed(123)n <-100# Variable de ejemplo: Ingresos en miles de eurosingresos <-rnorm(n, mean =50, sd =15)# Aplicar diferentes transformacionesingresos_std <-scale(ingresos)[,1] # Estandarizacióningresos_norm <- (ingresos -min(ingresos)) / (max(ingresos) -min(ingresos)) # Min-Maxingresos_robust <- (ingresos -median(ingresos)) /IQR(ingresos) # Robusto# Crear tabla comparativalibrary(knitr)tabla_escalado <-data.frame( Método =c("Original", "Estandarización", "Min-Max", "Escalado Robusto"),Media =round(c(mean(ingresos), mean(ingresos_std), mean(ingresos_norm), median(ingresos_robust)), 3), Desviación =round(c(sd(ingresos), sd(ingresos_std), sd(ingresos_norm), mad(ingresos_robust)), 3), Mínimo =round(c(min(ingresos), min(ingresos_std), min(ingresos_norm), min(ingresos_robust)), 3), Máximo =round(c(max(ingresos), max(ingresos_std), max(ingresos_norm), max(ingresos_robust)), 3),Rango =round(c(max(ingresos) -min(ingresos),max(ingresos_std) -min(ingresos_std),max(ingresos_norm) -min(ingresos_norm),max(ingresos_robust) -min(ingresos_robust) ), 3))kable(tabla_escalado, caption ="Comparación de métodos de escalado en variable Ingresos")
Comparación de métodos de escalado en variable Ingresos
Método
Media
Desviación
Mínimo
Máximo
Rango
Original
51.356
13.692
15.362
82.810
67.448
Estandarización
0.000
1.000
-2.629
2.297
4.926
Min-Max
0.534
0.203
0.000
1.000
1.000
Escalado Robusto
0.000
0.750
-2.000
1.793
3.792
Interpretación de los resultados:
Original: Ingresos en miles de euros con gran variabilidad (SD ≈ 15)
Estandarización: Media = 0, SD = 1, preservando la forma de la distribución
Min-Max: Valores acotados entre [0,1], comprimiendo toda la variabilidad en este rango
Escalado Robusto: Centrado en la mediana, menos sensible a valores extremos
Cada método transforma los datos de manera diferente según el objetivo: comparabilidad (estandarización), rango específico (min-max), o robustez ante outliers (robusto).
Comparación de métodos de escalado con outliers presentes
Método
Media_Mediana
Desviación
Mínimo
Máximo
Q25_Q75
Original
11.447
5.996
5.491
45.000
8.93 - 11.81
Estandarización
0.000
1.000
-0.993
5.595
-0.42 - 0.06
Min-Max
0.151
0.152
0.000
1.000
0.09 - 0.16
Escalado Robusto
0.000
0.778
-1.654
12.108
-0.45 - 0.55
Análisis del impacto de outliers:
Datos originales: Los outliers extienden el rango de ~6-14 a 6-45, distorsionando las medidas centrales
Estandarización: Afectada por outliers en media y desviación estándar, resultando en distribución asimétrica
Min-Max: Extremadamente sensible. Los datos normales quedan comprimidos en un rango muy pequeño (~0.0-0.2)
Escalado robusto: Mantiene mejor las proporciones de la distribución central, minimizando la influencia de valores extremos
Conclusión: El escalado robusto es superior cuando hay outliers, preservando la estructura de la mayoría de observaciones.
4.3 Catálogo de transformaciones según el propósito
Una vez realizado el diagnóstico, debemos seleccionar la transformación más apropiada. Cada transformación tiene propósitos específicos y efectos secundarios que debemos considerar. La clave está en entender no solo qué transformación aplicar, sino por qué esa transformación específica resuelve nuestro problema.
4.3.1 Transformaciones para linearizar relaciones
Muchas relaciones en el mundo real no son lineales, pero pueden linearizarse mediante transformaciones apropiadas. La linearización no solo mejora el ajuste del modelo, sino que también facilita la interpretación y cumple con los supuestos de la regresión lineal.
4.3.1.1 Transformación logarítmica
La transformación logarítmica es probablemente la más utilizada en estadística aplicada debido a su versatilidad y propiedades interpretativas únicas.
Cuándo utilizarla:
Relaciones exponenciales: Cuando Y crece exponencialmente respecto a X, \(Y = ae^{bX}\) se lineariza como \(\log(Y) = \log(a) + bX\)
Relaciones multiplicativas: En modelos donde los efectos se combinan multiplicativamente
Procesos de crecimiento proporcional: Donde la tasa de cambio es proporcional al nivel actual
Variables con crecimiento acelerado: Ingresos, precios, donde cada unidad adicional tiene impacto decreciente
Patrones de identificación:
Curva cóncava que se aplana hacia la derecha (rendimientos decrecientes)
Relación donde duplicar X no duplica Y, sino que el efecto se atenúa
Heterocedasticidad donde la varianza aumenta con el nivel de Y
Aplicaciones matemáticas:
\(Y' = \log(Y)\): Lineariza relaciones exponenciales en Y
\(X' = \log(X)\): Lineariza relaciones de potencia en X
\(\log(Y) = a + b\log(X)\): Modelo log-log que produce elasticidades constantes
Interpretación especial: En modelos log-lineales y log-log, los coeficientes tienen interpretaciones económicas directas. En el modelo log-lineal \(\log(Y) = a + bX\), el coeficiente b representa el cambio porcentual en Y por unidad de cambio en X. En el modelo log-log \(\log(Y) = a + b\log(X)\), b es la elasticidad.
Casos típicos: Economía (relaciones ingreso-consumo, funciones de producción), biología (crecimiento poblacional, relaciones alométricas), finanzas (rendimientos de inversión).
4.3.1.2 Transformación de potencia
Las transformaciones de potencia son fundamentales cuando trabajamos con leyes físicas o relaciones alométricas donde esperamos relaciones del tipo \(Y = aX^b\).
Identificación y aplicación:
Relaciones curvilíneas que en escala log-log se vuelven lineales
Método de linearización: tomar logaritmo de ambas variables \(\log(Y) = \log(a) + b\log(X)\)
El exponente b representa la elasticidad o exponente de escalamiento
Ejemplos clásicos: Ley de Stevens en psicofísica, relaciones masa-metabolismo (Ley de Kleiber), economía urbana donde PIB de ciudades escala con población elevada a una potencia.
4.3.2 Transformaciones para estabilizar la varianza
La heterocedasticidad no solo viola supuestos del modelo, sino que también indica que diferentes observaciones tienen diferentes niveles de información. Las transformaciones de varianza estabilizan esta heterogeneidad.
4.3.2.1 Transformación de raíz cuadrada
La transformación \(Y' = \sqrt{Y}\) es especialmente útil para datos de conteo donde la varianza es proporcional a la media, característica típica de la distribución de Poisson.
Fundamento teórico: En una distribución de Poisson con parámetro \(\lambda\), tanto la media como la varianza son iguales a \(\lambda\). La transformación de raíz cuadrada estabiliza la varianza porque \(\text{Var}(\sqrt{Y}) \approx \frac{1}{4}\) (constante).
Cuándo aplicarla:
Conteos de eventos: número de defectos, llamadas telefónicas, accidentes, ventas por período
Datos de frecuencia: número de visitas, clicks, transacciones
Variables discretas con varianza creciente proporcional al nivel
Patrón de diagnóstico: Gráfico de residuos con forma de embudo donde la dispersión aumenta linealmente con la media, y gráfico de varianza vs. media de grupos muestra relación lineal.
Limitaciones: Solo apropiada para valores no negativos, interpretación complicada (unidades en raíz cuadrada), y para conteos con muchos ceros puede requerir \(\sqrt{Y + c}\).
4.3.2.2 Transformación logarítmica para heterocedasticidad multiplicativa
Cuando la varianza es proporcional al cuadrado de la media (heterocedasticidad multiplicativa), la transformación logarítmica es la solución natural.
Características típicas:
Variables monetarias: ingresos, precios, costos donde el error relativo es constante
Porcentajes de crecimiento: donde el error de medición es proporcional al nivel
Procesos multiplicativos: donde los errores se acumulan multiplicativamente
Efectos múltiples: La transformación logarítmica frecuentemente resuelve múltiples problemas simultáneamente: lineariza relaciones exponenciales, estabiliza varianza multiplicativa, reduce el impacto de outliers extremos, y aproxima distribuciones asimétricas a la normalidad.
4.3.3 Transformaciones para normalizar residuos y controlar outliers
Algunas transformaciones son especialmente efectivas para aproximar distribuciones a la normalidad y reducir la influencia de valores extremos.
4.3.3.1 Transformación inversa
La transformación inversa \(Y' = \frac{1}{Y}\) o \(X' = \frac{1}{X}\) es útil para relaciones hiperbólicas y distribuciones con colas pesadas hacia la derecha.
Identificación matemática:
Relación hiperbólica: \(Y = \frac{a}{X} + b\) se lineariza como \(Y = a \cdot \frac{1}{X} + b\)
Asíntota horizontal: la relación se aproxima a un valor límite cuando X aumenta
Aplicaciones específicas: Tiempo hasta el evento (con asíntota natural), tasas de decaimiento, relaciones dosis-respuesta en farmacología, curvas de demanda con elasticidad precio variable.
Efecto en outliers: La transformación inversa invierte la escala, comprimiendo fuertemente los valores grandes y expandiendo los pequeños. Útil para reducir influencia de outliers extremos, pero debe usarse con precaución ya que amplifica errores en valores pequeños.
Consideraciones prácticas: Solo aplicable a valores estrictamente positivos (o negativos), los coeficientes representan el impacto en la escala inversa, y requiere tratamiento especial para valores cercanos a cero.
4.4 Transformación de Box-Cox
La transformación de Box-Cox es un método que optimiza automáticamente el parámetro de transformación para maximizar la normalidad y homocedasticidad de los residuos (Box y Cox 1964). En lugar de elegir manualmente entre transformación logarítmica, raíz cuadrada o inversa, Box-Cox encuentra el valor \(\lambda\) (lambda) que mejor normaliza los datos.
Los valores especiales de \(\lambda\) corresponden a transformaciones clásicas:
\(\lambda\) = 1: Sin transformación (identidad)
\(\lambda\) = 0.5: Transformación de raíz cuadrada
\(\lambda\) = 0: Transformación logarítmica
\(\lambda\) = -1: Transformación inversa
4.4.2 Propósito y ventajas
Para qué sirve Box-Cox:
Encuentra automáticamente la transformación óptima sin prueba y error
Maximiza la verosimilitud del modelo, mejorando simultáneamente normalidad y homocedasticidad
Proporciona un método objetivo para seleccionar la transformación apropiada
Incluye intervalos de confianza para \(\lambda\), permitiendo evaluar la incertidumbre de la estimación
Procedimiento de aplicación:
Se ajusta el modelo original y se calculan los residuos
Se evalúa la función de verosimilitud para diferentes valores de \(\lambda\)
Se selecciona el \(\lambda\) que maximiza la verosimilitud
Se aplica la transformación con el \(\lambda\) óptimo encontrado
4.4.3 Limitaciones importantes
Restricción de dominio: Box-Cox requiere que todos los valores de Y sean estrictamente positivos. Esta es su limitación más importante, ya que muchos conjuntos de datos reales incluyen ceros o valores negativos.
Aplicación tradicional: Se aplica principalmente a la variable dependiente Y, no a las variables predictoras. Aunque técnicamente es posible aplicarla a X, la interpretación se complica considerablemente.
Interpretación compleja: Cuando \(\lambda\) no corresponde a valores “simples” (como 0, 0.5, o 1), la interpretación de los coeficientes se vuelve difícil. Por ejemplo, si \(\lambda\) = 0.37, ¿cómo interpretar un coeficiente en la escala transformada?
Dependencia del modelo: El \(\lambda\) óptimo depende del modelo específico (predictores incluidos), por lo que cambiar el modelo puede requerir recalcular la transformación.
NotaExtensión: Transformación de Yeo-Johnson
La transformación de Yeo-Johnson (Yeo y Johnson 2000) fue desarrollada específicamente para superar la limitación principal de Box-Cox: la restricción a valores positivos.
Ventajas de Yeo-Johnson sobre Box-Cox:
Sin restricción de dominio: Acepta cualquier valor real, incluyendo negativos y cero
Preserva el signo: Los valores negativos permanecen negativos tras la transformación
Continuidad: La transformación es continua en Y = 0, evitando discontinuidades
Casos especiales familiares: Incluye como casos especiales todas las transformaciones comunes
Cuándo usar cada una:
Box-Cox: Para datos estrictamente positivos, especialmente cuando se busca comparabilidad con literatura existente
Yeo-Johnson: Cuando los datos incluyen valores negativos o cero, o cuando se necesita mayor flexibilidad
La elección entre ambas depende fundamentalmente de las características de sus datos y los objetivos del análisis.
4.5 Tratamiento de variables categóricas
Las variables categóricas son fundamentales en el modelado estadístico, pero requieren una preparación especial antes de ser utilizadas en algoritmos que esperan entradas numéricas (Potdar, Pardawala, y Pai 2017). La elección del método de codificación puede impactar significativamente tanto la interpretabilidad como el rendimiento del modelo.
4.5.1 Principios de codificación categórica
¿Por qué codificar? La mayoría de algoritmos de machine learning y modelos estadísticos requieren entradas numéricas. Las variables categóricas deben transformarse preservando su información semántica sin introducir supuestos erróneos sobre relaciones entre categorías.
Criterios de selección del método:
Naturaleza de la variable: ¿Existe orden inherente entre categorías?
Número de categorías: Variables con muchas categorías requieren consideraciones especiales
Interpretabilidad: ¿Qué método facilita la interpretación de resultados?
Eficiencia computacional: Balance entre precisión y complejidad
4.5.2 Codificación One-Hot (variables nominales)
El One-Hot Encoding transforma variables categóricas nominales en un conjunto de variables binarias (0/1), donde cada nueva variable representa la presencia o ausencia de una categoría específica. Esta técnica es fundamental cuando trabajamos con variables categóricas que no tienen orden inherente, como color, género, región geográfica, o tipo de producto.
La transformación convierte una variable categórica con k categorías en k nuevas columnas binarias (o k-1 para evitar colinealidad). Cada fila tendrá exactamente un “1” en la columna correspondiente a su categoría y “0” en todas las demás.
AdvertenciaDummy Variable Trap
Cuando se crean todas las columnas (k para k categorías), una puede expresarse como combinación lineal de las demás, causando colinealidad perfecta en modelos lineales.
Solución: Eliminar una categoría de referencia (usar k-1 columnas).
¿Por qué es necesario? La mayoría de algoritmos de machine learning requieren entradas numéricas y no pueden procesar directamente texto categórico. Más importante aún, el One-Hot Encoding no impone orden artificial entre categorías, tratando cada una como completamente independiente.
Ejemplo práctico: Consideremos una variable “Color” con valores [Rojo, Verde, Azul]. La codificación One-Hot creará tres columnas:
ID
Color
Color_Rojo
Color_Verde
Color_Azul
1
Rojo
1
0
0
2
Verde
0
1
0
3
Azul
0
0
1
4
Rojo
1
0
0
Cada observación queda representada por un vector binario que identifica unívocamente su categoría sin asumir relaciones ordinales entre colores.
Interpretación en regresión: En un modelo de regresión lineal, cada variable binaria creada tendrá su propio coeficiente que representa la diferencia en la variable respuesta entre esa categoría específica y la categoría de referencia (la omitida). Por ejemplo, si omitimos “Azul”, el coeficiente de “Color_Rojo” indicará cuánto mayor (o menor) es el valor esperado de Y cuando el color es Rojo comparado con cuando es Azul.
TipImplementación práctica
# Crear datos de ejemplosuppressPackageStartupMessages(library(caret))datos <-data.frame(ID =1:5,Color =c("Rojo", "Verde", "Azul", "Rojo", "Verde"))
Método 1: usando model.matrix (incluye todas las categorías)
one_hot_completo <-model.matrix(~ Color -1, data = datos)one_hot_completo
No asume orden: Trata cada categoría como independiente
Interpretabilidad: Cada coeficiente representa el efecto específico de esa categoría
Compatibilidad: Funciona con todos los algoritmos numéricos
Desventajas:
Dimensionalidad: Crea k columnas para k categorías (o k-1 con categoría de referencia)
Dispersión: Matrices resultantes son muy dispersas (muchos ceros)
Colinealidad: Riesgo de “dummy variable trap” sin categoría de referencia
4.5.3 Codificación Ordinal (variables ordinales)
La codificación ordinal transforma variables categóricas ordinales en números enteros que preservan el orden jerárquico natural de las categorías. Esta técnica es fundamental cuando trabajamos with variables categóricas que tienen un orden inherente y significativo, como nivel educativo, satisfacción del cliente, grado de severidad, o calificaciones de crédito.
La transformación asigna números enteros consecutivos que reflejan la jerarquía natural de las categorías, preservando tanto la información categórica como el orden relativo entre ellas.
AdvertenciaCuándo usar codificación ordinal
La codificación ordinal es apropiada cuando las categorías tienen un orden natural claro y este orden es relevante para el fenómeno que estamos modelando. El modelo puede aprovechar esta información ordinal para capturar tendencias o patrones relacionados con la jerarquía de las categorías.
¿Por qué preservar el orden? Los algoritmos de machine learning pueden aprovechar la información ordinal para identificar tendencias y patrones que se perderían con one-hot encoding. Cuando el orden es significativo, la codificación ordinal es más eficiente y puede mejorar el rendimiento del modelo.
Ejemplo práctico: Consideremos una variable “Satisfacción” con valores ordenados [Muy Insatisfecho, Insatisfecho, Neutral, Satisfecho, Muy Satisfecho]. La codificación ordinal asignará:
ID
Satisfacción
Satisfacción_Codificada
1
Muy Insatisfecho
1
2
Insatisfecho
2
3
Neutral
3
4
Satisfecho
4
5
Muy Satisfecho
5
Cada observación queda representada por un número entero que preserva el orden jerárquico de las categorías originales.
Interpretación en regresión: En un modelo de regresión lineal, el coeficiente de la variable ordinal codificada representa el cambio promedio en la variable respuesta por cada incremento de una unidad en el nivel ordinal. Por ejemplo, si el coeficiente es 2.5, esto significa que pasar del nivel 1 al 2, o del 3 al 4, se asocia en promedio con un aumento de 2.5 unidades en la variable respuesta, asumiendo intervalos uniformes entre niveles.
TipImplementación práctica
# Crear datos de ejemplodatos <-data.frame(ID =1:5,Satisfaccion =c("Muy Insatisfecho", "Insatisfecho", "Neutral", "Satisfecho", "Muy Satisfecho"))# Convertir en factor ordenadodatos$Satisfaccion_factor <-factor(datos$Satisfaccion, levels =c("Muy Insatisfecho", "Insatisfecho", "Neutral", "Satisfecho", "Muy Satisfecho"), ordered =TRUE)# Codificación ordinal manualdatos$Satisfaccion_codificada <-as.numeric(datos$Satisfaccion_factor)# Verificar la codificacióndatos
ID Satisfaccion Satisfaccion_factor Satisfaccion_codificada
1 1 Muy Insatisfecho Muy Insatisfecho 1
2 2 Insatisfecho Insatisfecho 2
3 3 Neutral Neutral 3
4 4 Satisfecho Satisfecho 4
5 5 Muy Satisfecho Muy Satisfecho 5
Ejemplo de uso en regresión:
# Simular variable respuesta correlacionada con el ordenset.seed(123)datos$Puntuacion <-c(2, 4, 6, 8, 10) +rnorm(5, mean =0, sd =0.5)# Modelo de regresiónmodelo <-lm(Puntuacion ~ Satisfaccion_codificada, data = datos)summary(modelo)
Call:
lm(formula = Puntuacion ~ Satisfaccion_codificada, data = datos)
Residuals:
1 2 3 4 5
-0.2090 -0.1279 0.6826 -0.1455 -0.2002
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.1552 0.4640 -0.335 0.759968
Satisfaccion_codificada 2.0840 0.1399 14.896 0.000657 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4424 on 3 degrees of freedom
Multiple R-squared: 0.9867, Adjusted R-squared: 0.9822
F-statistic: 221.9 on 1 and 3 DF, p-value: 0.0006565
NotaVentajas y desventajas
Ventajas de la codificación ordinal:
Preserva la jerarquía: Mantiene el orden natural entre categorías
Eficiencia dimensional: Una sola columna independiente del número de categorías
Interpretabilidad: Coeficientes representan cambios por unidad de nivel ordinal
Eficiencia computacional: Menor uso de memoria y procesamiento
Desventajas:
Supuesto de intervalos uniformes: Asume que las diferencias entre niveles consecutivos son iguales
Riesgo con variables no-ordinales: Puede imponer orden artificial en variables nominales
Pérdida de flexibilidad: No puede capturar relaciones no-lineales entre niveles ordinales
4.5.4 Comparación directa: Ordinal vs One-Hot Encoding
La elección entre codificación ordinal y one-hot encoding depende fundamentalmente de la naturaleza de la variable categórica y los objetivos del análisis. Una decisión incorrecta puede llevar a interpretaciones erróneas y modelos subóptimos.
Característica
Codificación Ordinal
One-Hot Encoding
Preserva el orden
Sí, refleja la jerarquía entre categorías
No, trata cada categoría como independiente
Dimensionalidad
Una sola columna
k columnas (o k-1)
Adecuado para
Variables con orden natural (educación, satisfacción)
Variables nominales (color, género, región)
Interpretación
Cambio por unidad de nivel
Diferencia vs. categoría de referencia
Eficiencia computacional
Alta (menos parámetros)
Menor (más parámetros)
Riesgo principal
Orden artificial en variables nominales
Dimensionalidad excesiva
4.6 Interacciones entre variables
Las interacciones entre variables representan uno de los conceptos más poderosos y subestimados en el modelado estadístico. Mientras que los efectos principales capturan el impacto promedio de cada variable por separado, las interacciones revelan cómo el efecto de una variable cambia según el nivel de otra variable. Este fenómeno es omnipresente en el mundo real: el efecto del precio en las ventas depende del nivel de publicidad, el impacto de la experiencia en el salario varía según la educación, o la efectividad de un tratamiento médico puede diferir entre grupos demográficos.
ImportantePrincipios para feature engineering efectivo
Justificación teórica: Cada nueva variable debe tener sentido conceptual en el dominio
Validación rigurosa: Evaluar el poder predictivo real en datos no vistos
Simplicidad primero: Preferir transformaciones simples e interpretables
Documentación exhaustiva: Registrar el proceso de creación y la lógica detrás de cada feature
Monitoreo continuo: Verificar que las relaciones se mantienen en producción
Ignorar las interacciones relevantes puede llevar a conclusiones erróneas y pérdida significativa de poder predictivo. Por otro lado, incluir interacciones irrelevantes incrementa la complejidad del modelo sin beneficios, violando el principio de parsimonia. La clave está en identificar, interpretar y validar interacciones de manera sistemática y teoricamente fundamentada.
4.6.1 Interacciones entre variables continuas
El caso más directo es la interacción entre dos variables continuas:
Interpretación del coeficiente de interacción (\(\beta_3\)):
Si \(\beta_3 > 0\): El efecto de \(X_1\) se amplifica cuando \(X_2\) aumenta
Si $_3 < 0: El efecto de \(X_1\) se atenúa cuando \(X_2\) aumenta
Si \(\beta_3 = 0\): No hay interacción (efectos aditivos)
TipEjemplo: Interacción precio-publicidad en ventas
# Simulación: efecto de precio y publicidad en ventas# con interacción (mayor publicidad reduce sensibilidad al precio)set.seed(789)n <-200precio <-runif(n, 50, 150) # precio en eurospublicidad <-runif(n, 0, 10) # gasto en publicidad (miles €)# Efecto principal negativo del precio, positivo de publicidad# Interacción: mayor publicidad reduce sensibilidad negativa al precioventas <-1000-5*precio +50*publicidad +0.8*precio*publicidad/10+rnorm(n, 0, 50)datos_inter <-data.frame(precio, publicidad, ventas)# Modelo con interacciónmodelo_interaccion <-lm(ventas ~ precio * publicidad, data = datos_inter)summary(modelo_interaccion)
Call:
lm(formula = ventas ~ precio * publicidad, data = datos_inter)
Residuals:
Min 1Q Median 3Q Max
-158.256 -35.577 0.296 37.460 118.605
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 968.37048 27.53011 35.175 <2e-16 ***
precio -4.74324 0.26860 -17.659 <2e-16 ***
publicidad 55.77675 4.48175 12.445 <2e-16 ***
precio:publicidad 0.03470 0.04432 0.783 0.435
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 50.87 on 196 degrees of freedom
Multiple R-squared: 0.9518, Adjusted R-squared: 0.9511
F-statistic: 1291 on 3 and 196 DF, p-value: < 2.2e-16
Interpretación numérica de los coeficientes:
# Extraer coeficientes y p-valores para interpretacióncoef_int <-coef(modelo_interaccion)summary_model <-summary(modelo_interaccion)p_valores <- summary_model$coefficients[, "Pr(>|t|)"]# Crear tabla de interpretación de efectostabla_efectos <-data.frame(Nivel_Publicidad =c("0 (sin publicidad)", "5 (media)", "10 (alta)"),Efecto_Precio =c(round(coef_int[2], 2),round(coef_int[2] +5*coef_int[4], 2),round(coef_int[2] +10*coef_int[4], 2) ))kable(tabla_efectos, caption ="Efecto del precio según el nivel de publicidad (hipotético)",col.names =c("Nivel de Publicidad", "Efecto del Precio (€/unidad)"))
Efecto del precio según el nivel de publicidad (hipotético)
Nivel de Publicidad
Efecto del Precio (€/unidad)
0 (sin publicidad)
-4.74
5 (media)
-4.57
10 (alta)
-4.40
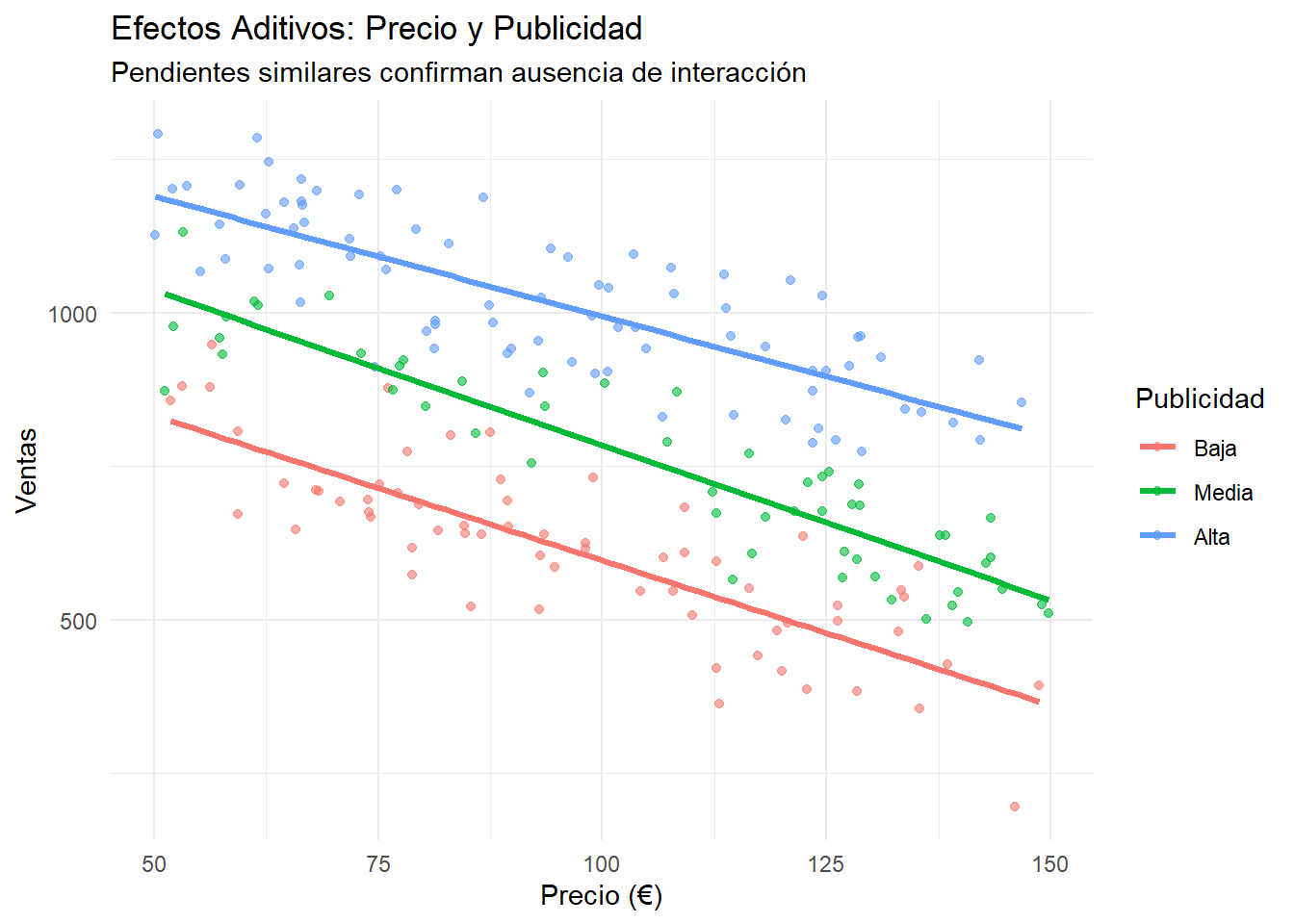
Evidencia estadística: La interacción tiene un coeficiente de 0.035 con un p-valor de 0.435. Dado que p > 0.05, no hay evidencia estadística de interacción entre precio y publicidad.
Interpretación del gráfico: El primer gráfico (scatter plot con líneas de tendencia por grupos de publicidad) muestra líneas prácticamente paralelas, confirmando la ausencia de interacción. Aunque visualmente las pendientes parecen ligeramente diferentes, esta variación está dentro del rango esperado por el ruido aleatorio.
Implicaciones prácticas:
El efecto del precio sobre las ventas es constante (-€5 por unidad) independientemente del nivel de publicidad
Los efectos son aditivos: cada €1000 adicional en publicidad aumenta las ventas base en ~50 unidades, sin modificar la sensibilidad al precio
Modelo recomendado:ventas ~ precio + publicidad (sin término de interacción)
Lección metodológica: Este caso demuestra la importancia de confiar en la evidencia estadística formal sobre las impresiones visuales cuando hay variabilidad muestral significativa.
Visualización para verificar ausencia de interacción:
# Visualización de la interacciónlibrary(ggplot2)# Crear grupos de publicidad para visualizardatos_inter$pub_grupo <-cut(datos_inter$publicidad, breaks =3, labels =c("Baja", "Media", "Alta"))ggplot(datos_inter, aes(x = precio, y = ventas, color = pub_grupo)) +geom_point(alpha =0.6) +geom_smooth(method ="lm", formula = y ~ x, se =FALSE, linewidth =1.2) +labs(title ="Efectos Aditivos: Precio y Publicidad",subtitle ="Pendientes similares confirman ausencia de interacción",x ="Precio (€)", y ="Ventas", color ="Publicidad") +theme_minimal()
Interpretación crítica: Visual vs Estadística
Observando el gráfico, las líneas parecen tener pendientes diferentes, lo que visualmente sugeriría la presencia de interacción. Sin embargo, el análisis estadístico formal nos indica que esta diferencia no es estadísticamente significativa (p = 0.435).
¿Por qué esta aparente contradicción?
Variabilidad aleatoria: Las diferencias observadas pueden deberse al ruido aleatorio en los datos
Tamaño de muestra: Puede no ser suficiente para detectar una interacción débil si realmente existe
Poder estadístico: El test puede no tener suficiente poder para detectar efectos pequeños
Agrupación artificial: Los grupos de publicidad se crearon artificialmente para visualización, no reflejan la variable continua real
Decisión metodológica correcta:
Confiar en la estadística formal: El p-valor > 0.05 indica no significancia
Modelo parsimonioso: Eliminar el término de interacción no significativo
Interpretación conservadora: Los efectos son aditivos hasta que se demuestre lo contrario
Lección crucial:
Este ejemplo demuestra por qué la inspección visual nunca debe ser el único criterio para decidir sobre la inclusión de términos de interacción. La estadística inferencial formal debe prevalecer sobre las impresiones visuales, especialmente cuando hay incertidumbre debido a la variabilidad muestral.
Modelo final recomendado:ventas ~ precio + publicidad (sin interacción)
4.6.2 Interacciones entre variables categóricas
Cuando ambas variables son categóricas, las interacciones representan efectos específicos de combinaciones de categorías que no pueden explicarse por los efectos principales por separado.
Para dos variables categóricas A (con niveles i) y B (con niveles j), el modelo incluye:
Donde \((\alpha\beta)_{ij}\) representa la interacción específica entre el nivel i de A y el nivel j de B.
La interacción \((\alpha\beta)_{ij}\) indica cuánto la combinación específica (i,j) se desvía del efecto que esperaríamos si solo sumáramos los efectos principales \(\alpha_i + \beta_j\).
TipEjemplo: Interacción género-departamento en salarios
# Simulación: salarios por género y departamento con interacción# (brecha salarial varía según departamento)set.seed(456)n <-300# Variables categóricasgenero <-sample(c("Masculino", "Femenino"), n, replace =TRUE)departamento <-sample(c("Ventas", "IT", "RRHH"), n, replace =TRUE)# Efectos principales y de interacción simuladosefecto_base <-40000# salario baseefecto_masculino <-ifelse(genero =="Masculino", 2000, 0)efecto_it <-ifelse(departamento =="IT", 8000, 0)efecto_rrhh <-ifelse(departamento =="RRHH", 3000, 0)# Interacción: brecha de género mayor en ITinteraccion <-ifelse(genero =="Masculino"& departamento =="IT", 4000, 0)salario <- efecto_base + efecto_masculino + efecto_it + efecto_rrhh + interaccion +rnorm(n, 0, 3000)datos_cat <-data.frame(genero, departamento, salario)# Modelo con interacciónmodelo_cat <-lm(salario ~ genero * departamento, data = datos_cat)summary(modelo_cat)
Call:
lm(formula = salario ~ genero * departamento, data = datos_cat)
Residuals:
Min 1Q Median 3Q Max
-8037.9 -1930.7 48.4 1968.1 7486.9
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 47627.4 461.2 103.270 < 2e-16 ***
generoMasculino 6166.3 593.4 10.391 < 2e-16 ***
departamentoRRHH -4433.3 633.9 -6.994 1.80e-11 ***
departamentoVentas -7744.7 597.4 -12.964 < 2e-16 ***
generoMasculino:departamentoRRHH -4007.2 857.1 -4.675 4.48e-06 ***
generoMasculino:departamentoVentas -3793.8 814.4 -4.659 4.83e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2917 on 294 degrees of freedom
Multiple R-squared: 0.7372, Adjusted R-squared: 0.7327
F-statistic: 164.9 on 5 and 294 DF, p-value: < 2.2e-16
# Medias por grupo para interpretar la interacciónmedias_grupo <-aggregate(salario ~ genero + departamento, data = datos_cat, FUN = mean)medias_grupo <- medias_grupo[order(medias_grupo$departamento, medias_grupo$genero), ]kable(medias_grupo, caption ="Salario promedio por género y departamento")
Salario promedio por género y departamento
genero
departamento
salario
Femenino
IT
47627.44
Masculino
IT
53793.71
Femenino
RRHH
43194.15
Masculino
RRHH
45353.23
Femenino
Ventas
39882.76
Masculino
Ventas
42255.23
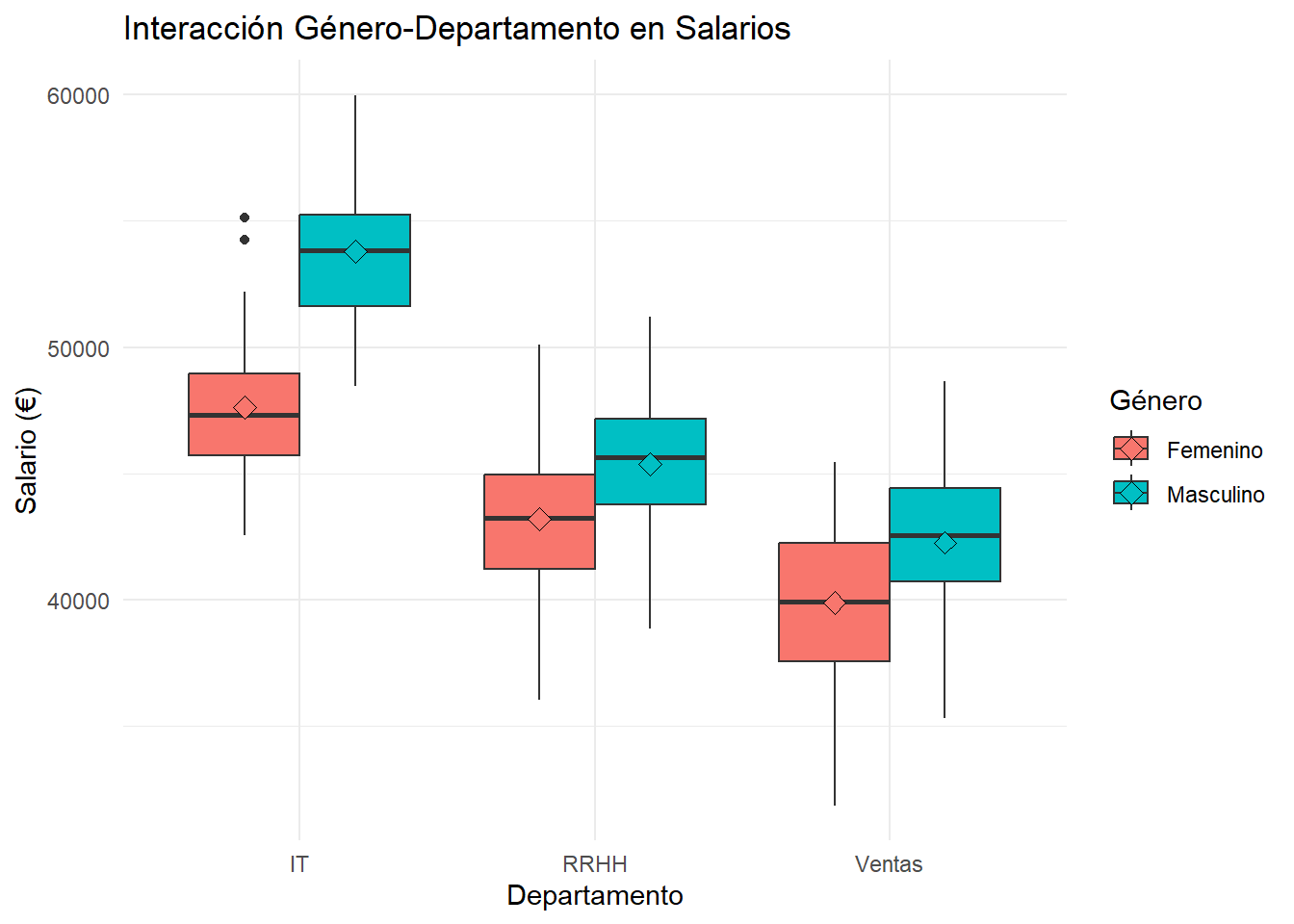
# Visualización de la interacciónlibrary(ggplot2)ggplot(datos_cat, aes(x = departamento, y = salario, fill = genero)) +geom_boxplot(position ="dodge") +stat_summary(fun = mean, geom ="point", shape =23, size =3, position =position_dodge(0.75)) +labs(title ="Interacción Género-Departamento en Salarios",x ="Departamento", y ="Salario (€)", fill ="Género") +theme_minimal()
Evidencia visual clara: El segundo gráfico (boxplots por género y departamento) revela patrones de interacción marcados que se manifiestan de forma diferente en cada departamento.
Patrones específicos por departamento:
IT: La brecha de género es máxima (~€8,000). Los hombres tienen salarios significativamente superiores y mayor variabilidad salarial
RRHH: Brecha moderada (~€3,000) con distribuciones más similares entre géneros
Ventas:Menor brecha de género (~€1,500), con salarios más homogéneos entre grupos
Interpretación de la interacción: Las líneas no paralelas en el patrón de medias confirman que el efecto del género sobre el salario varía significativamente según el departamento. Esto sugiere:
Diferencias en culturas departamentales respecto a equidad salarial
Estructuras de compensación variables entre departamentos
Posibles diferencias en poder de negociación o demanda de talento
Implicaciones organizacionales: La interacción indica que las políticas salariales no son uniformes y que intervenciones de equidad deberían ser diferenciadas por departamento.
Gráfico de interacción clásico:
# Calcular medias y errores estándar por grupo para el gráficosuppressPackageStartupMessages(library(dplyr))medias_se <- datos_cat %>%group_by(genero, departamento) %>%summarise(media =mean(salario),se =sd(salario) /sqrt(n()),.groups ="drop" )# Mostrar los datos calculadoskable(medias_se, caption ="Medias y errores estándar por grupo")
Medias y errores estándar por grupo
genero
departamento
media
se
Femenino
IT
47627.44
463.4703
Femenino
RRHH
43194.15
443.9292
Femenino
Ventas
39882.76
378.5932
Masculino
IT
53793.71
371.1923
Masculino
RRHH
45353.23
425.9146
Masculino
Ventas
42255.23
414.4745
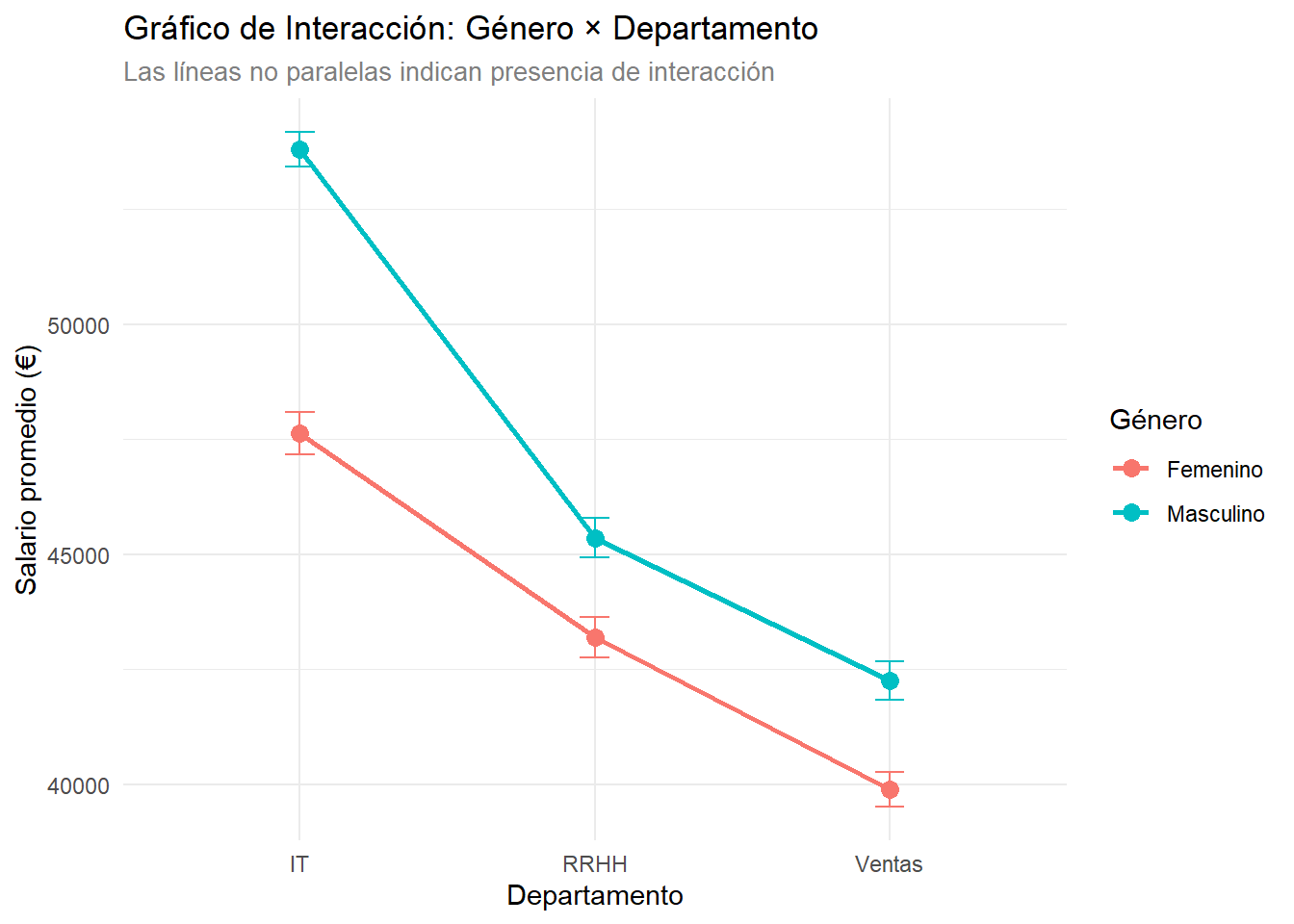
# Gráfico de interacción estilo clásicoggplot(medias_se, aes(x = departamento, y = media, color = genero, group = genero)) +geom_point(size =3) +geom_line(linewidth =1) +geom_errorbar(aes(ymin = media - se, ymax = media + se), width =0.1) +labs(title ="Gráfico de Interacción: Género × Departamento",subtitle ="Las líneas no paralelas indican presencia de interacción",x ="Departamento", y ="Salario promedio (€)", color ="Género") +theme_minimal() +theme(plot.subtitle =element_text(size =10, color ="gray50"))
Interpretación del gráfico: Las líneas no son paralelas, confirmando la presencia de interacción significativa. La brecha salarial de género varía considerablemente: mayor en IT, moderada en RRHH, y menor en Ventas.
Las interacciones mixtas son especialmente útiles para modelar cómo el efecto de una variable continua varía entre grupos categóricos. Esto es fundamental cuando sospechamos que la relación funcional cambia según el contexto definido por la variable categórica.
Formulación matemática:\[Y = \beta_0 + \beta_1 X + \beta_2 D + \beta_3 X \cdot D + \varepsilon\]
Donde D es una variable dummy (0/1) que representa la variable categórica.
Interpretación geométrica: La interacción permite que cada grupo categórico tenga:
Intercepto diferente: \(\beta_0\) (grupo de referencia) vs. \(\beta_0 + \beta_2\) (otro grupo)
Pendiente diferente: \(\beta_1\) (grupo de referencia) vs. \(\beta_1 + \beta_3\) (otro grupo)
TipEjemplo: Interacción experiencia-género en salarios
# Simulación: efecto de experiencia en salario varía según géneroset.seed(789)n <-250experiencia <-runif(n, 0, 20) # años de experienciagenero <-sample(c("Femenino", "Masculino"), n, replace =TRUE)# Efecto diferencial: pendiente de experiencia menor para mujeressalario_base <-35000efecto_experiencia_hombres <-2000# €2000 por año para hombresefecto_experiencia_mujeres <-1200# €1200 por año para mujeres (brecha creciente)efecto_genero_base <-ifelse(genero =="Masculino", 3000, 0)# Crear variable dummy para interaccióndummy_masculino <-ifelse(genero =="Masculino", 1, 0)# Salario con interacciónsalario <- salario_base + efecto_experiencia_mujeres * experiencia +# pendiente base (mujeres) efecto_genero_base * dummy_masculino +# diferencia intercepto (efecto_experiencia_hombres - efecto_experiencia_mujeres) * experiencia * dummy_masculino +# interacciónrnorm(n, 0, 4000)datos_mixta <-data.frame(experiencia, genero, salario, dummy_masculino)# Modelo con interacciónmodelo_mixta <-lm(salario ~ experiencia * genero, data = datos_mixta)summary(modelo_mixta)
Call:
lm(formula = salario ~ experiencia * genero, data = datos_mixta)
Residuals:
Min 1Q Median 3Q Max
-12340.2 -2742.7 162.8 2586.6 9293.8
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 35650.27 765.04 46.599 <2e-16 ***
experiencia 1123.03 69.74 16.103 <2e-16 ***
generoMasculino 2613.33 1038.08 2.517 0.0125 *
experiencia:generoMasculino 905.46 92.44 9.795 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3995 on 246 degrees of freedom
Multiple R-squared: 0.8889, Adjusted R-squared: 0.8876
F-statistic: 656.2 on 3 and 246 DF, p-value: < 2.2e-16
Interpretación detallada de los coeficientes:
# Extraer coeficientes para interpretacióncoef_mixta <-coef(modelo_mixta)# Crear tabla de interpretación por génerotabla_genero <-data.frame( Parámetro =c("Intercepto (salario inicial)", "Pendiente (€ por año experiencia)"),Mujeres =c(paste0("€", format(round(coef_mixta[1], 0), big.mark =",")),paste0("€", round(coef_mixta[2], 0)) ),Hombres =c(paste0("€", format(round(coef_mixta[1] + coef_mixta[3], 0), big.mark =",")),paste0("€", round(coef_mixta[2] + coef_mixta[4], 0)) ),Diferencia =c(paste0("€", format(round(coef_mixta[3], 0), big.mark =",")),paste0("€", round(coef_mixta[4], 0), " adicionales") ))kable(tabla_genero, caption ="Comparación de parámetros del modelo por género")
Comparación de parámetros del modelo por género
Parámetro
Mujeres
Hombres
Diferencia
Intercepto (salario inicial)
€35,650
€38,264
€2,613
Pendiente (€ por año experiencia)
€1123
€2028
€905 adicionales
Implicaciones de la interacción:
El coeficiente de interacción (905) indica que cada año adicional de experiencia aumenta el salario masculino en €905 más que el salario femenino. Esto crea una brecha creciente: inicialmente la diferencia es de €2,613, pero después de 20 años de experiencia, la brecha total alcanza €20,722.
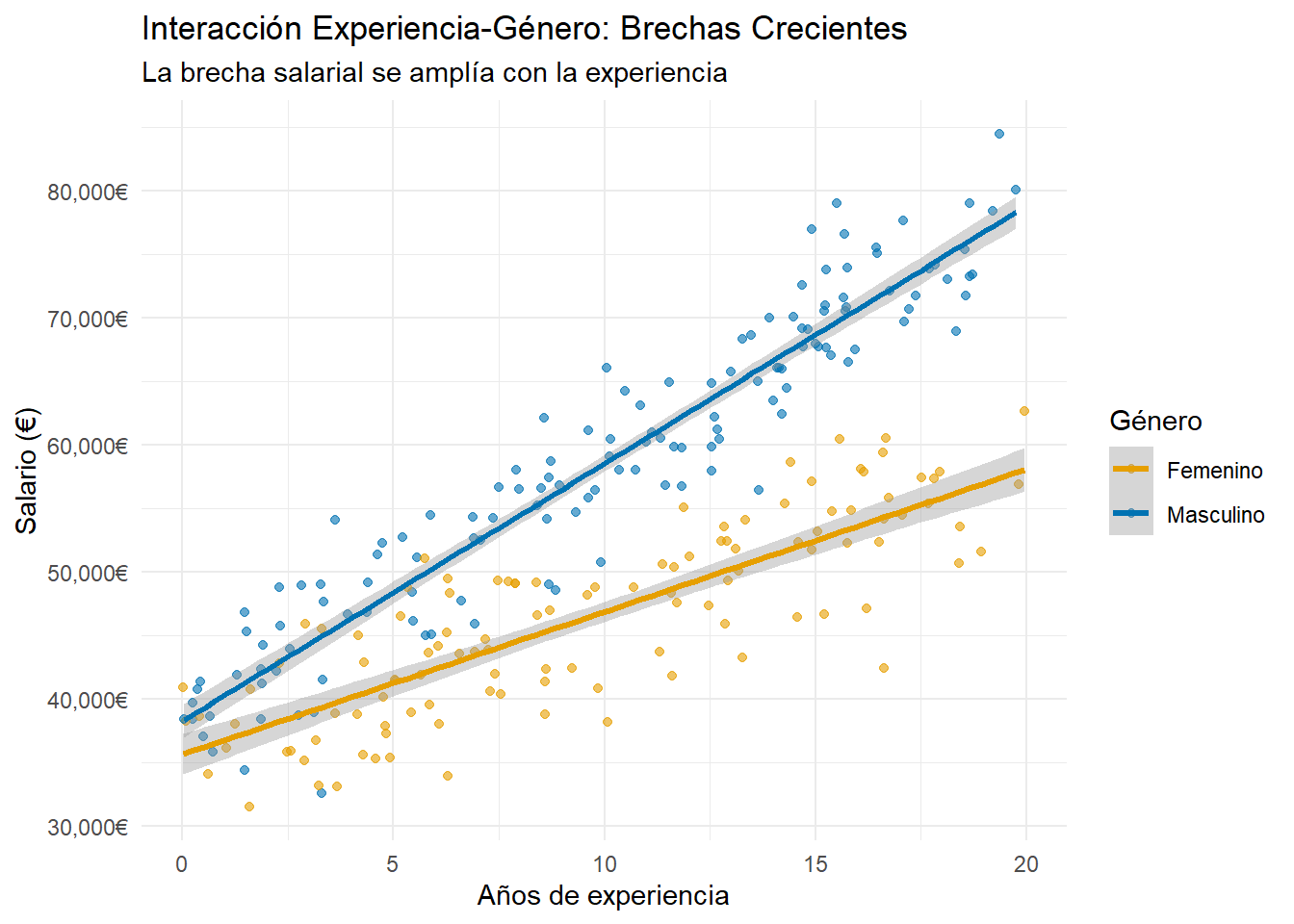
Visualización de la divergencia salarial:
# Visualización de líneas de regresión por grupoggplot(datos_mixta, aes(x = experiencia, y = salario, color = genero)) +geom_point(alpha =0.6) +geom_smooth(method ="lm", formula = y ~ x, se =TRUE, linewidth =1.2) +labs(title ="Interacción Experiencia-Género: Brechas Crecientes",subtitle ="La brecha salarial se amplía con la experiencia",x ="Años de experiencia", y ="Salario (€)", color ="Género") +theme_minimal() +scale_color_manual(values =c("Femenino"="#E69F00", "Masculino"="#0072B2")) +scale_y_continuous(labels = scales::comma_format(suffix ="€"))
Evidencia de brechas crecientes: El tercer gráfico (scatter plot con líneas de regresión) demuestra claramente el patrón de interacción experiencia-género mediante líneas divergentes con pendientes notablemente diferentes.
Interpretación cuantitativa de la divergencia:
Punto de inicio (0 años): Brecha inicial de €2,613 a favor de los hombres
Pendientes diferenciadas: Los hombres ganan €2028 adicionales por año vs. €1123 para las mujeres
Brecha acumulativa: Cada año adicional de experiencia amplía la brecha en €905 adicionales
Implicaciones del patrón de interacción: La divergencia progresiva visible en las líneas revela que:
El retorno a la experiencia es sistemáticamente mayor para hombres que para mujeres
A los 20 años de experiencia, la brecha total alcanza €20,722 (inicial + acumulativa)
Este patrón sugiere barreras estructurales que impiden que las mujeres capitalicen plenamente su experiencia
Significancia social: Esta interacción documenta un fenómeno preocupante donde la inequidad salarial se agrava con el tiempo, indicando que las brechas de género no son meramente diferencias de entrada sino desventajas acumulativas a lo largo de la carrera profesional.
4.6.4 Identificación y detección de interacciones
La detección sistemática de interacciones requiere combinar justificación teórica, exploración visual y validación estadística. No debemos buscar interacciones aleatoriamente, sino guiados por el conocimiento del dominio y patrones observables en los datos.
La justificación teórica previa es fundamental: la teoría del dominio debe sugerir dónde pueden existir interacciones. Por ejemplo, en economía esperamos efectos precio-publicidad o educación-experiencia; en medicina son comunes las interacciones dosis-edad o tratamiento-comorbilidad; en marketing encontramos interacciones producto-canal o temporada-promoción.
La exploración visual sistemática complementa la teoría con evidencia empírica. Para variables continuas utilizamos gráficos de dispersión coloreados por grupos categóricos; para variables categóricas empleamos gráficos de interacción (interaction plots); para interacciones mixtas analizamos líneas de regresión por grupo.
Los tests estadísticos formales proporcionan validación objetiva: el test F para interacciones compara modelos con y sin términos de interacción, el test de significancia individual evalúa coeficientes específicos mediante t-test, y los criterios de información (AIC/BIC) guían la selección entre modelos alternativos.
NotaEstrategia de modelado jerárquico
Principio de jerarquía: Si incluimos una interacción A×B, siempre debemos incluir los efectos principales A y B, incluso si no son significativos individualmente. Esto preserva la interpretabilidad y evita sesgos en los coeficientes de interacción.
Proceso de construcción del modelo:
Modelo base: Solo efectos principales
Modelo con interacciones: Agregar términos de interacción teoricamente justificados
Comparación: Test F para evaluar mejora significativa
Selección: Usar criterios estadísticos y de parsimonia
Validación: Verificar supuestos y estabilidad en datos de prueba
4.6.5 Consideraciones prácticas y limitaciones
Las interacciones incrementan exponencialmente la complejidad interpretativa del modelo. Un modelo con k efectos principales puede tener hasta \(k(k-1)/2\) interacciones de segundo orden, y el número crece exponencialmente con interacciones de orden superior. Esta explosión combinatorial hace que incluso modelos aparentemente simples se vuelvan rápidamente inmanejables desde el punto de vista interpretativo. Como reglas prácticas para la complejidad, recomendamos limitar a máximo 2-3 interacciones de segundo orden en modelos explicativos, evitar interacciones de tercer orden salvo justificación teórica muy sólida, y priorizar interacciones con efectos grandes sobre mera significancia estadística.
AdvertenciaAdvertencia sobre interpretación
Cuidado con la interpretación automática. Las interacciones en escalas transformadas tienen significados diferentes que en escalas originales. Siempre verificar la interpretación en el contexto de la transformación aplicada y considerar la retransformación para comunicación con audiencias no técnicas.
Un problema adicional surge cuando las interacciones crean multicolinealidad severa, especialmente cuando las variables principales están correlacionadas, se incluyen múltiples interacciones con variables comunes, o se usan variables categóricas con muchos niveles. Esta multicolinealidad puede hacer que los coeficientes individuales sean inestables y difíciles de interpretar, incluso cuando el modelo en conjunto funcione bien predictivamente. Las estrategias de mitigación incluyen el centrado de variables continuas para reducir la correlación entre X y X×Z, la selección cuidadosa de interacciones sin incluir todas las combinaciones posibles, y el uso de métodos de regularización como Ridge o Lasso cuando hay múltiples interacciones.
La situación se complica aún más cuando las variables están transformadas (logarítmica, Box-Cox). En estos casos, la interpretación de las interacciones adquiere significados completamente diferentes que en escalas originales. Por ejemplo, en un modelo como \(\log(Y) = \beta_0 + \beta_1 \log(X_1) + \beta_2 X_2 + \beta_3 \log(X_1) \cdot X_2 + \varepsilon\), el coeficiente \(\beta_3\) representa cómo cambia la elasticidad de Y respecto a X₁ cuando X₂ aumenta en una unidad, lo que requiere una interpretación mucho más sofisticada que una interacción en escalas lineales.
ImportantePrincipios para el uso de interacciones
Justificación teórica primero: No buscar interacciones sin base conceptual
Principio de jerarquía: Mantener efectos principales cuando se incluyen interacciones
Parsimonia: Preferir modelos simples que expliquen bien sobre modelos complejos
Validación robusta: Verificar estabilidad en múltiples contextos
Interpretación cuidadosa: Asegurar comprensión completa antes de conclusiones
Comunicación efectiva: Usar visualizaciones para explicar efectos complejos
Las interacciones son herramientas poderosas que pueden revelar patrones importantes ocultos en los efectos principales. Sin embargo, su uso requiere disciplina metodológica, justificación teórica sólida, y validación rigurosa para evitar conclusiones espurias y modelos sobreajustados.
4.7 Ingeniería de características avanzada: combinaciones, ratios y transformaciones
Más allá de las transformaciones individuales e interacciones, la ingeniería de características avanzada implica crear nuevas variables predictivas mediante combinaciones matemáticas, ratios y transformaciones compuestas que capturen relaciones complejas no evidentes en las variables originales (Kuhn y Johnson 2019). Esta aproximación es fundamental cuando las variables individuales contienen información parcial que, al combinarse, revelan patrones predictivos más potentes.
4.7.1 Combinaciones lineales y no lineales
Las combinaciones lineales crean nuevas variables mediante sumas ponderadas de variables existentes, útiles especialmente cuando trabajamos con variables que miden aspectos relacionados del mismo fenómeno pero con diferentes escalas o unidades.
Ejemplos de combinaciones lineales efectivas:
Índices compuestos: Combinan múltiples indicadores en un score único que captura un constructo multidimensional. Por ejemplo, un índice de riesgo cardiovascular podría definirse como índice_salud = 0.4×presión_arterial_normalizada + 0.3×colesterol_normalizada + 0.3×IMC_normalizado. Los pesos (0.4, 0.3, 0.3) reflejan la importancia relativa establecida por evidencia médica, creando una métrica integrada que es más informativa que cualquier indicador individual. Este tipo de índices son especialmente valiosos en dominios donde múltiples factores contribuyen conjuntamente al outcome de interés.
Scores balanceados: Representan equilibrios o trade-offs entre dimensiones competitivas. Un ejemplo típico es balance_trabajo_vida = horas_trabajo / (tiempo_personal + tiempo_familia + tiempo_descanso). Esta métrica captura no solo la intensidad laboral, sino también su contexto relativo dentro del estilo de vida completo. Valores altos indican desbalance hacia el trabajo, mientras que valores cercanos a 1.0 sugieren equilibrio saludable. Los scores balanceados son fundamentales para capturar dinámicas de compensación que no son evidentes en variables absolutas.
Factores sintéticos: Cuando múltiples variables correlacionadas miden aspectos del mismo constructo subyacente, pueden condensarse en un factor común que preserve la información esencial eliminando redundancia. Por ejemplo, si tenemos variables ingresos, educación, y prestigio_ocupacional (todas correlacionadas), podemos crear un factor estatus_socioeconomico que capture la varianza común. Esto es especialmente útil cuando la colinealidad entre predictores compromete la estabilidad del modelo, pero cada variable aporta información valiosa.
Las combinaciones no lineales van más allá de las sumas ponderadas para capturar interacciones multiplicativas, sinergias y compensaciones entre variables mediante productos, cocientes, potencias y funciones más complejas:
Productos de eficiencia: Capturan sinergias multiplicativas donde el rendimiento depende de la combinación simultánea de múltiples factores. Por ejemplo, rendimiento_efectivo = capacidad_instalada × utilización_porcentual × factor_calidad. Esta métrica reconoce que el rendimiento real no es aditivo: tener alta capacidad pero baja utilización, o alta utilización con problemas de calidad, resulta en rendimiento subóptimo. Los productos de eficiencia son esenciales en contextos operacionales donde el desempeño emerge de la coordinación entre recursos.
Ratios de rendimiento ajustado por riesgo: Normalizan beneficios por su costo o riesgo asociado, creando métricas comparables entre contextos diferentes. Un ejemplo financiero sería eficiencia_ajustada = (rendimiento_esperado - tasa_libre_riesgo) / (volatilidad + costos_transaccion). Esta formulación reconoce que los rendimientos absolutos son engañosos sin considerar el riesgo asumido y los costos incurridos. Los ratios ajustados son cruciales para decisiones de optimización donde debemos comparar alternativas con perfiles de riesgo-retorno heterogéneos.
Funciones de utilidad: Capturan percepciones subjetivas o valores no lineales mediante transformaciones que reflejan preferencias reales. Por ejemplo, valor_percibido = √(calidad_producto) × precio⁻⁰·⁵ reconoce que la utilidad del consumidor tiene rendimientos decrecientes tanto en calidad como en ahorro de precio. La raíz cuadrada de la calidad refleja que mejoras incrementales tienen menor impacto en niveles altos, mientras que el exponente negativo del precio captura la sensibilidad decreciente a cambios de precio en productos caros.
4.7.2 Ratios y proporciones como features
Los ratios son especialmente poderosos porque normalizan automáticamente las diferencias de escala y pueden revelar relaciones proporcionales fundamentales que permanecen ocultas en variables absolutas. A diferencia de las medidas absolutas, los ratios capturan relaciones estructurales que son invariantes bajo cambios de escala y contexto, lo que los convierte en herramientas fundamentales para crear features robustos y comparables.
La potencia de los ratios radica en su capacidad para transformar información absoluta en información relativa. Por ejemplo, una empresa con €1M en ventas y €100K en marketing tiene un ratio ventas/marketing de 10, igual que una empresa con €10M en ventas y €1M en marketing. Esta normalización automática permite comparaciones directas y elimina sesgos de tamaño que podrían distorsionar el análisis.
Categorización detallada de ratios efectivos:
Ratios de eficiencia: Miden qué tan efectivamente se convierten los inputs en outputs, revelando productividad y optimización operacional. Ejemplos fundamentales incluyen:
ROI_marketing = (ventas_generadas - gasto_marketing) / gasto_marketing: Captura el retorno neto por euro invertido
conversion_rate = ventas_completadas / visitantes_web: Revela la efectividad del funnel de conversión
Estos ratios son especialmente valiosos porque eliminan el efecto escala y permiten comparar unidades de diferentes tamaños en términos de eficiencia pura.
Ratios de riesgo ajustado: Normalizan retornos o beneficios por la incertidumbre o costo asociado, proporcionando métricas de valor ajustado por riesgo:
sharpe_ratio = (rendimiento_promedio - tasa_libre_riesgo) / volatilidad: Mide retorno por unidad de riesgo asumido
stability_score = beneficio_promedio / desviacion_estandar_beneficios: Indica consistencia en el desempeño
Estos ratios son cruciales en análisis financiero y gestión de riesgos, donde los valores absolutos pueden ser engañosos sin considerar la variabilidad subyacente.
Ratios temporales: Capturan dinámicas y tendencias mediante comparaciones entre períodos, revelando momentum y patrones estacionales:
momentum_growth = crecimiento_último_trimestre / crecimiento_promedio_histórico: Identifica aceleración o desaceleración
Estos ratios son especialmente útiles en análisis de series temporales donde necesitamos distinguir entre variación normal y cambios estructurales significativos.
Ratios de composición: Revelan la estructura interna de agregados mediante proporciones parte-todo, fundamentales para análisis de portafolios y segmentación:
concentracion_cliente = ventas_top3_clientes / ventas_totales: Mide dependencia y riesgo de concentración
diversificacion_producto = 1 - suma(proportion_i²): Índice de Herfindahl para medir dispersión
market_share = ventas_empresa / ventas_mercado_total: Posición relativa competitiva
Los ratios de composición son esenciales para gestión de riesgos y análisis estratégico, revelando vulnerabilidades y fortalezas estructurales.
Ventajas metodológicas profundizadas:
Normalización automática: Los ratios eliminan efectos de escala absoluta, haciendo comparables entidades de diferentes tamaños. Una startup con €10K en ventas y €2K en marketing tiene el mismo ratio ventas/marketing (5.0) que una multinacional con €100M y €20M respectivamente, permitiendo benchmarking directo de eficiencia.
Interpretación intuitiva: Los ratios tienen significados naturales que facilitan la comunicación con stakeholders. Un ratio deuda/patrimonio de 0.3 es inmediatamente comprensible como “30 céntimos de deuda por cada euro de patrimonio”, mientras que valores absolutos requieren más contexto.
Robustez ante outliers: Los ratios suelen ser menos sensibles a valores extremos que las variables absolutas. Si una empresa tiene ventas anómalamente altas pero también marketing proporcionalmente alto, el ratio ventas/marketing permanece estable, mientras que ambas variables individuales serían outliers.
Invarianza bajo transformaciones: Los ratios mantienen sus relaciones bajo cambios de unidades o inflación. El ratio precio/ingresos de una acción es el mismo si se mide en euros o dólares, proporcionando estabilidad interpretativa a lo largo del tiempo y contextos.
Consideraciones para construcción robusta de ratios:
Los ratios requieren cuidado especial en su construcción para evitar interpretaciones erróneas o inestabilidad numérica. Es fundamental evitar denominadores cercanos a cero, considerar transformaciones logarítmicas para ratios con rangos amplios, y validar que el ratio tenga significado conceptual en el dominio de aplicación.
4.7.3 Tratamiento de variables colineales mediante feature engineering
Cuando enfrentamos multicolinealidad entre predictores informativos, la ingeniería de características ofrece alternativas más sofisticadas que simplemente eliminar variables o usar interacciones sin efectos principales. Este escenario es común en la práctica: tenemos múltiples variables que aportan información valiosa individualmente, pero están suficientemente correlacionadas como para crear problemas de estabilidad e interpretación en el modelo.
El enfoque tradicional de “eliminar variables correlacionadas” es problemático porque puede resultar en pérdida significativa de información predictiva. Si variable_A y variable_B tienen correlación r = 0.75, ambas comparten 56% de varianza, pero cada una retiene 44% de información única. Eliminar cualquiera de ellas descarta información potencialmente valiosa que podría mejorar el poder predictivo del modelo.
La ingeniería de características para colinealidad busca condensar la información redundante mientras preserva la información única, creando nuevas variables que capturen la esencia predictiva de las variables originales sin los problemas de multicolinealidad. Esta aproximación es especialmente valiosa cuando la correlación entre variables tiene significado teórico: por ejemplo, diferentes medidas de solvencia financiera que capturan aspectos relacionados pero distintos del riesgo crediticio.
Estrategias avanzadas de condensación de información:
Componentes principales (PCA): Extraen direcciones de máxima varianza común, creando variables ortogonales que preservan la mayor cantidad de información con la menor dimensionalidad:
Ventajas del PCA: Elimina completamente la multicolinealidad, preserva máxima varianza, proporciona interpretación de “factores latentes”. Desventajas: Pérdida de interpretabilidad directa, todos los componentes dependen de todas las variables originales, sensible a outliers.
Ratios informativos: Crean cocientes que preservan la información relativa más relevante, eliminando efectos de escala común:
# Ratios que capturan relaciones estructurales fundamentalesratio_debt_income <- deuda_total / ingresos_anuales # Capacidad de endeudamientoratio_assets_equity <- activos / patrimonio_neto # Apalancamientoratio_liquidity <- activos_liquidos / pasivos_corrientes # Solvencia a corto plazo
Ventajas de los ratios: Mantienen interpretabilidad económica directa, eliminan efectos de escala, capturan relaciones estructurales clave. Aplicabilidad: Especialmente efectivos cuando las variables correlacionadas miden aspectos del mismo fenómeno subyacente (ej. diferentes medidas de tamaño empresarial).
Índices ponderados: Combinan variables usando pesos derivados de conocimiento teórico o empírico, creando métricas compuestas más robustas que sus componentes individuales:
# Índice de solvencia con pesos basados en evidencia empíricaindice_solvencia <-0.4* (ingresos/gastos) +0.3* (activos/deudas) +0.3* score_crediticio_normalizado# Índice de crecimiento balanceadoindice_crecimiento <-0.5* crecimiento_ventas +0.3* crecimiento_beneficios +0.2* crecimiento_empleados
Determinación de pesos: Pueden derivarse de análisis factorial confirmatorio, regresión ridge, conocimiento experto, o optimización empírica. Los pesos deben justificarse teóricamente y validarse en datos independientes.
Diferencias y cambios relativos: Capturan dinámicas temporales y patrones de co-movimiento que revelan información única no presente en niveles absolutos:
# Dinámicas de crecimiento relativocrecimiento_relativo <- (valor_actual - valor_anterior) / valor_anterioraceleracion <- (crecimiento_t - crecimiento_t_1) / crecimiento_t_1# Medidas de estabilidad y volatilidadvolatilidad <-sd(ultimos_12_meses) /mean(ultimos_12_meses)consistencia <-1/ (1+cv(ultimos_periodos)) # Coeficiente de variación invertido
Aplicabilidad temporal: Especialmente útiles para series temporales donde variables están correlacionadas en niveles pero divergen en tasas de cambio, revelando dinámicas diferenciales ocultas en análisis de niveles.
NotaCriterios de selección de estrategia
PCA: Cuando la interpretabilidad no es crítica y maximizar la retención de varianza es prioritario
Ratios: Cuando existe significado teórico claro en las relaciones proporcionales entre variables
Índices ponderados: Cuando hay conocimiento previo sobre la importancia relativa de cada componente
Cambios relativos: Cuando las dinámicas temporales son más informativas que los niveles absolutos
La ingeniería de características es tanto arte como ciencia: requiere creatividad para identificar combinaciones útiles, pero también rigor metodológico para validar que las nuevas variables realmente aportan valor predictivo estable y generalizable.
Box, George EP, y David R Cox. 1964. «An analysis of transformations». Journal of the Royal Statistical Society: Series B (Methodological) 26 (2): 211-43.
Carroll, Raymond J, y David Ruppert. 1988. «Transformation and weighting in regression». Monographs on Statistics and Applied Probability.
Jaccard, James, y Robert Turrisi. 2003. Interaction effects in multiple regression. Sage.
Kuhn, Max, y Kjell Johnson. 2019. Feature engineering and selection: a practical approach for predictive models. CRC Press.
Potdar, Kedar, Taher S Pardawala, y Chinmay D Pai. 2017. «A comparative study of categorical variable encoding techniques for neural network classifiers». International journal of computer applications 175 (4): 7-9.
Yeo, In-Kwon, y Richard A Johnson. 2000. «A new family of power transformations to improve normality or symmetry». Biometrika 87 (4): 954-59.
Zheng, Alice, y Amanda Casari. 2018. Feature engineering for machine learning: principles and techniques for data scientists. O’Reilly Media.