La regresión lineal constituye uno de los pilares fundamentales de la modelización estadística. Es, a menudo, el primer y más importante modelo predictivo que se aprende, no solo por su simplicidad e interpretabilidad, sino porque los conceptos que exploraremos aquí son la base sobre la que se construyen técnicas mucho más avanzadas, como el modelo de regresión lineal múltiple, los modelos lineales generalizados (GLM) o incluso conceptos utilizados en algoritmos de machine learning(Draper 1998; Kutner et al. 2005; James et al. 2021).
En este capítulo, daremos el primer y más crucial paso en nuestro viaje por el modelado predictivo: el estudio del modelo de regresión lineal simple. Para ello, seguiremos el ciclo de vida completo de un proyecto de modelado: comenzaremos con la exploración visual y cuantitativa de los datos, formalizaremos después nuestras observaciones mediante el lenguaje matemático del modelo y sus supuestos, aprenderemos a estimar sus parámetros, realizaremos inferencias sobre ellos y, finalmente, diagnosticaremos la validez de nuestro modelo (Fox y Weisberg 2018; Harrell 2015).
La comprensión profunda que desarrollaremos aquí es esencial, ya que los principios de estimación, inferencia y diagnóstico que aprenderemos son directamente escalables al modelo de regresión lineal múltiple, que exploraremos en el siguiente capítulo.
ImportanteObjetivos de aprendizaje
Al finalizar este capítulo, serás capaz de:
Comprender y aplicar el proceso de modelización estadística para un problema con una única variable predictora.
Identificar y medir la correlación lineal entre dos variables como paso previo al modelado.
Describir la formulación matemática del modelo de regresión lineal simple e interpretar el significado práctico de sus parámetros.
Estimar los coeficientes del modelo mediante el método de mínimos cuadrados ordinarios (MCO) y entender su derivación matemática y propiedades.
Realizar inferencias sobre los parámetros del modelo y evaluar su bondad de ajuste mediante el análisis de la varianza y el coeficiente de determinación R².
Diagnosticar la adecuación del modelo, evaluando visual y analíticamente si se cumplen los supuestos del modelo lineal.
2.1 Exploración inicial: visualización y cuantificación de la relación
Antes de sumergirnos en la teoría de la regresión, debemos hacer lo que todo buen analista hace primero: observar y cuantificar la relación en los datos. Este paso exploratorio es fundamental para formular hipótesis y justificar la elección de un modelo lineal.
2.1.1 Visualización: el gráfico de dispersión
La herramienta más potente para examinar la relación entre dos variables continuas es el gráfico de dispersión (scatterplot). Nos permite intuir visualmente la forma, la dirección y la fuerza de la relación. Una inspección visual es siempre el punto de partida.
2.1.2 Cuantificación de la asociación: covarianza y correlación
Una vez que la visualización sugiere una tendencia, necesitamos métricas para cuantificarla.
2.1.2.1 Covarianza
La covarianza es una medida de la variabilidad conjunta de dos variables aleatorias, \(X\) e \(Y\). Nos indica la dirección de la relación lineal. La covarianza muestral, calculada a partir de nuestras observaciones \((x_i, y_i)\), es:
El principal inconveniente de la covarianza es que su magnitud depende de las unidades de las variables, lo que la hace difícil de interpretar.
2.1.2.2 Coeficiente de correlación de Pearson
Para solucionar el problema de la escala, estandarizamos la covarianza, dividiéndola por el producto de las desviaciones típicas de cada variable. El resultado es el coeficiente de correlación de Pearson (\(r\)):
\[
r = r_{xy} = \frac{s_{xy}}{s_x s_y}
\]
Este coeficiente es adimensional y siempre varía entre -1 y 1, lo que permite una interpretación universal de la fuerza de la asociación lineal.
TipEjemplo práctico: Horas de estudio vs. Calificaciones
Vamos a plantear un problema que nos acompañará durante todo el capítulo: queremos saber si el tiempo de estudio semanal influye en las calificaciones finales.
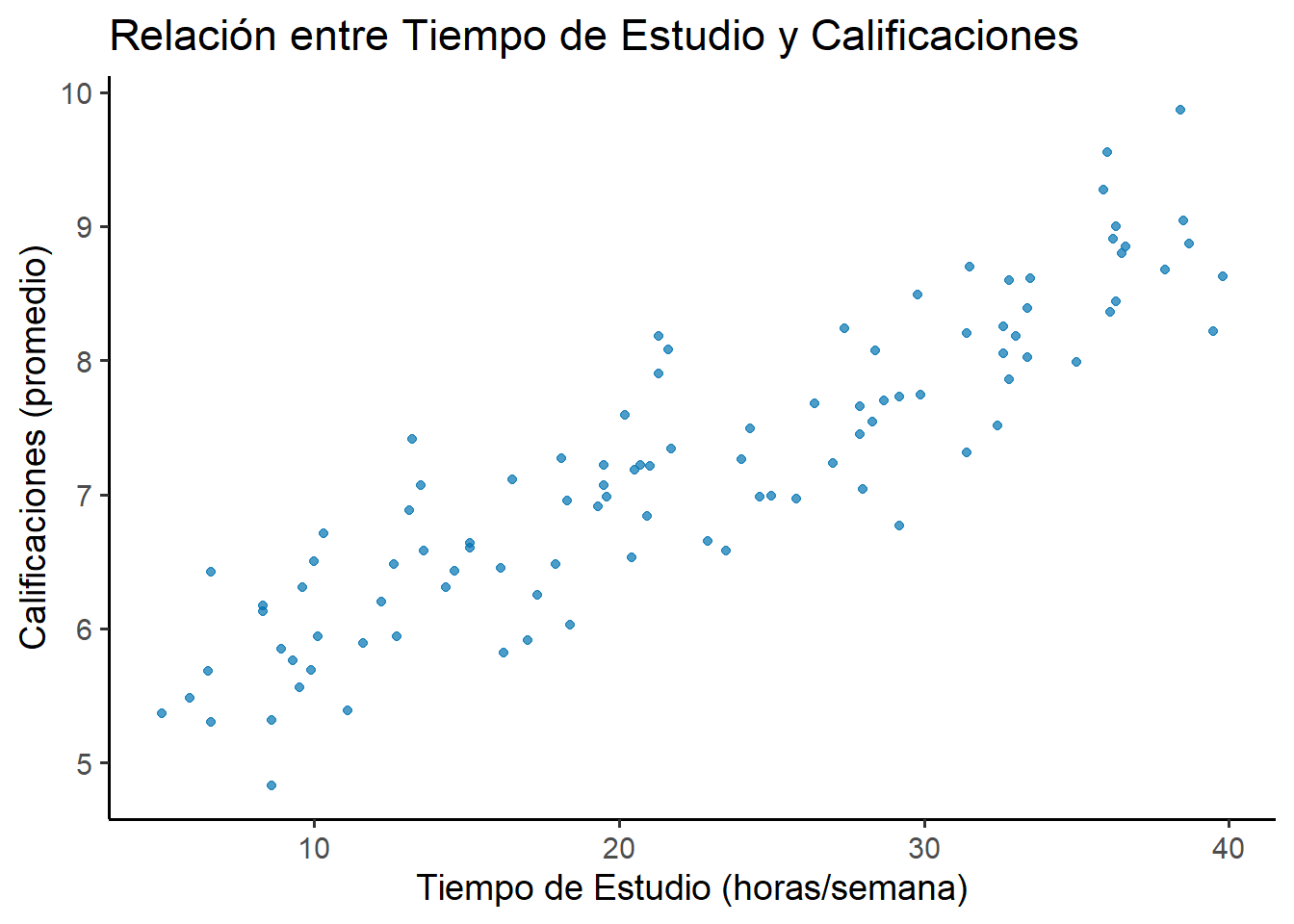
library(ggplot2)set.seed(123) # Para reproducibilidad# Simulación de datosdatos <-data.frame(Tiempo_Estudio =round(runif(100, min =5, max =40), 1))datos$Calificaciones <-round(5+0.1* datos$Tiempo_Estudio +rnorm(100, mean =0, sd =0.5), 2)# Visualizaciónggplot(datos, aes(x = Tiempo_Estudio, y = Calificaciones)) +geom_point(color ="#0072B2", alpha =0.7) +labs(title ="Relación entre Tiempo de Estudio y Calificaciones",x ="Tiempo de Estudio (horas/semana)",y ="Calificaciones (promedio)" ) +theme_classic(base_size =14)# Cuantificación (los objetos se guardan para usarlos en el texto)covarianza <-cov(datos$Tiempo_Estudio, datos$Calificaciones)correlacion <-cor(datos$Tiempo_Estudio, datos$Calificaciones)
Figura 2.1: Relación entre tiempo de estudio y calificaciones.
El gráfico muestra una clara tendencia lineal positiva. La covarianza toma un valor de 9.82, y el coeficiente de correlación de Pearson es de 0.9. Ambos valores confirman que la asociación lineal es, además de positiva, muy fuerte. Esta evidencia visual y numérica nos da una base sólida para proponer un modelo de regresión lineal.
Advertencia¡Correlación no implica causalidad!
El haber encontrado una fuerte correlación positiva entre el tiempo de estudio y las calificaciones (0.9) no nos autoriza a concluir que una cosa causa la otra. La regresión lineal puede demostrar que las variables se mueven juntas y nos permite predecir una a partir de la otra, pero no explica el porqué de la relación.
Podría existir una tercera variable oculta (p. ej., el interés del alumno en la materia) que influya tanto en las horas de estudio como en las calificaciones. Establecer causalidad requiere un diseño experimental riguroso (asignando aleatoriamente a los estudiantes a diferentes tiempos de estudio), no solo un análisis observacional.
2.2 Formulación teórica del modelo
Una vez que la exploración sugiere una relación lineal, el siguiente paso es formalizarla matemáticamente. Aquí es donde definimos la estructura teórica del modelo y los supuestos bajo los cuales operará.
2.2.1 El modelo poblacional y sus componentes
El modelo poblacional postula que la relación verdadera entre la variable respuesta \(Y\) y la predictora \(X\) sigue una línea recta, aunque contaminada por cierta aleatoriedad. Para cualquier individuo \(i\) de la población, esta relación se describe como:
\[
Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i
\]
En esta ecuación, \(\beta_0\) y \(\beta_1\) son los parámetros poblacionales (el intercepto y la pendiente verdaderos pero desconocidos), y \(\varepsilon_i\) es el error aleatorio, un componente fundamental que captura todas las fuentes de variabilidad que el modelo no puede explicar por sí solo. Específicamente, este término incluye:
Variables omitidas: Factores que también afectan a las calificaciones (como la calidad del sueño, la motivación del estudiante o su conocimiento previo) y que no están en el modelo.
Error de medida: Pequeñas imprecisiones al medir las variables (p. ej., un estudiante podría reportar 20 horas de estudio cuando en realidad fueron 19.5).
Aleatoriedad inherente: La variabilidad puramente estocástica o impredecible en el comportamiento humano.
Como nunca observamos la población entera, nuestro trabajo consiste en usar una muestra para estimar el modelo muestral:
Aquí, los “gorros” (\(\hat{\cdot}\)) denotan estimaciones calculadas a partir de la muestra. La diferencia entre el valor real y el predicho, \(e_i = y_i - \hat{y}_i\), se conoce como residuo.
2.2.2 Los supuestos del modelo lineal clásico (Gauss-Markov)
Para que el puente entre nuestro modelo muestral y la realidad poblacional sea sólido, debemos asumir que los errores teóricos \(\varepsilon_i\) se comportan de una manera predecible y ordenada. Estos supuestos, conocidos como condiciones de Gauss-Markov (Kutner et al. 2005; Weisberg 2005), son fundamentales para las propiedades óptimas de los estimadores de mínimos cuadrados.
Linealidad: La relación entre \(X\) y el valor esperado de \(Y\) es, en promedio, una línea recta: \(E[Y_i | X_i] = \beta_0 + \beta_1 X_i\).
Independencia de los errores: El error de una observación no está correlacionado con el error de ninguna otra: \(\text{Cov}(\varepsilon_i, \varepsilon_j) = 0\) para \(i \neq j\).
Homocedasticidad: La varianza del error es constante (\(\sigma^2\)) para todos los valores de \(X\): \(Var(\varepsilon_i | X_i) = \sigma^2\). Esto significa que la dispersión de los datos alrededor de la línea de regresión es la misma a lo largo de todos los valores de la variable predictora. La violación de este supuesto se conoce como heterocedasticidad, donde la dispersión de los errores cambia (p. ej., aumenta a medida que \(X\) crece).
Cuando el objetivo no es sólo estimar la recta, sino inferir con ella, entonces se asume una hipótesis más: la normalidad de la variable respuesta, o lo que es lo mismo, del error aleatorio:
Normalidad de los errores: Para la inferencia, se asume que los errores siguen una distribución Normal con media cero y varianza \(\sigma^2\): \(\varepsilon_i \sim N(0, \sigma^2)\).
Estos supuestos son esenciales para garantizar la validez de las estimaciones y conclusiones derivadas del modelo.
2.3 Estimación de los parámetros
Necesitamos un método para encontrar la “mejor” recta de ajuste. El Método de Mínimos Cuadrados Ordinarios (MCO/OLS) nos proporciona este criterio.
2.3.1 El criterio de mínimos cuadrados
MCO busca la recta que minimice la Suma de los Cuadrados del Error (SSE), es decir, la suma de las distancias verticales al cuadrado entre los puntos observados y la recta de regresión:
Para encontrar los valores de \(\beta_0\) y \(\beta_1\) que minimizan esta función, recurrimos al cálculo. Tratamos la SSE como una función de dos variables y calculamos sus derivadas parciales, igualándolas a cero para encontrar el mínimo.
2.3.2.1 Interpretación práctica de los coeficientes
Una vez estimados, los coeficientes tienen una interpretación muy concreta y útil:
Pendiente (\(\hat{\beta}_1\)): Representa el cambio promedio estimado en la variable respuesta \(Y\) por cada aumento de una unidad en la variable predictora \(X\). En nuestro ejemplo, sería el número de puntos que se espera que aumente la calificación final por cada hora adicional de estudio semanal.
Intercepto (\(\hat{\beta}_0\)): Es el valor promedio estimado de la variable respuesta \(Y\) cuando la variable predictora \(X\) es igual a cero. La interpretación del intercepto solo tiene sentido práctico si \(X=0\) es un valor plausible y se encuentra dentro del rango de nuestros datos. De lo contrario (como en nuestro ejemplo, donde nadie estudia 0 horas), a menudo se considera simplemente un ancla matemática para la recta de regresión.
NotaMinimización de SSE
La obtención de los estimadores de mínimos cuadrados para la regresión lineal simple se basa en minimizar la suma de los cuadrados de los residuos (\(SSE\)). Este método, desarrollado por Legendre y Gauss a principios del siglo XIX (Galton 1886; Weisberg 2005), es fundamental en la estadística moderna. Aquí está el proceso paso a paso:
Para minimizar \(SSE\), derivamos parcialmente con respecto a \(\beta_0\) y \(\beta_1\) y resolvemos el sistema de ecuaciones.
Expresamos \(\beta_1\): \[
\beta_1 = \frac{\sum_{i=1}^n x_i y_i - \frac{\sum_{i=1}^n x_i \sum_{i=1}^n y_i}{n}}{\sum_{i=1}^n x_i^2 - \frac{(\sum_{i=1}^n x_i)^2}{n}}.
\] Esta es la fórmula para \(\beta_1\), que puede reescribirse como: \[
\beta_1 = \frac{\text{Cov}(x, y)}{\text{Var}(x)},
\] donde \(\text{Cov}(x, y)\) y \(\text{Var}(x)\) son la covarianza y la varianza muestral de \(x\) y \(y\).
Finalmente, sustituimos \(\beta_1\) en la ecuación (3) para obtener \(\beta_0\): \[
\beta_0 = \bar{y} - \beta_1 \bar{x},
\] donde \(\bar{x}\) y \(\bar{y}\) son las medias de \(x\) y \(y\).
Bajo los supuestos del modelo, el Teorema de Gauss-Markov demuestra que estos estimadores son los Mejores Estimadores Lineales Insesgados (MELI / BLUE).
2.4 Inferencia y bondad de ajuste
Una vez hemos estimado los parámetros del modelo, nuestro trabajo apenas ha comenzado. Ahora debemos pasar de la descripción a la inferencia. Necesitamos un conjunto de herramientas que nos permitan responder a preguntas cruciales: ¿Son nuestros coeficientes estimados, \(\hat{\beta}_0\) y \(\hat{\beta}_1\), meras casualidades de nuestra muestra o reflejan una relación real en la población? ¿Qué tan bueno es nuestro modelo para explicar la variabilidad de la variable respuesta? Esta sección se dedica a responder estas preguntas.
2.4.1 Propiedades de los estimadores de MCO
Antes de realizar inferencias, es fundamental entender las propiedades teóricas de los estimadores que hemos calculado.
Insesgadez: Los estimadores de MCO son insesgados. Esto significa que si pudiéramos repetir nuestro muestreo muchísimas veces y calcular los estimadores en cada muestra, el promedio de todas nuestras estimaciones de \(\hat{\beta}_0\) y \(\hat{\beta}_1\) convergería a los verdaderos valores poblacionales \(\beta_0\) y \(\beta_1\). Matemáticamente: \[
E[\hat{\beta}_0] = \beta_0 \quad \text{y} \quad E[\hat{\beta}_1] = \beta_1
\]
Varianza de los estimadores: Las fórmulas para la varianza de nuestros estimadores cuantifican su precisión. Una varianza pequeña implica que el estimador es más estable a través de diferentes muestras. \[
Var(\hat{\beta}_1) = \frac{\sigma^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2} = \frac{\sigma^2}{S_{xx}}
\]\[
Var(\hat{\beta}_0) = \sigma^2 \left[ \frac{1}{n} + \frac{\bar{x}^2}{S_{xx}} \right]
\] Donde \(\sigma^2\) es la varianza (desconocida) del término de error \(\varepsilon\).
Teorema de Gauss-Markov: Este es uno de los resultados más importantes de la teoría de la regresión. Establece que, bajo los supuestos de linealidad, independencia y homocedasticidad (no se requiere normalidad), los estimadores de MCO son los Mejores Estimadores Lineales Insesgados (MELI, o BLUE en inglés). Esto significa que, de entre toda la clase de estimadores que son lineales e insesgados, los de MCO son los que tienen la menor varianza posible.
NotaPropiedades adicionales para las predicciones y para los residuos
La suma de los residuos es cero: \[
\sum_{i=1}^n e_i=\sum_{i=1}^n(y_i-\hat{y_i})=0
\]
La suma de los valores observados es igual a la suma de los valores ajustados: \[
\sum_{i=1}^n y_i=\sum_{i=1}^n \hat{y_i}
\]
La suma de los residuos ponderados por los regresores es cero: \[
\sum_{i=1}^n x_ie_i=0
\]
La suma de los residuos ponderados por las predicciones es cero: \[
\sum_{i=1}^n \hat{y_i}e_i=0
\]
La recta de regresión contiene el punto \((\bar{x},\bar{y})\):\[\hat{\beta_0} + \hat{\beta_1}\bar{x} = \bar{y}\]
TipEjemplo
Para los datos de calificaciones y tiempo de estudio, estos son los estimadores de los parámetros del modelo de regresión:
# 1. Ajustamos el modelo linealmodelo_estudio <-lm(Calificaciones ~ Tiempo_Estudio, data = datos)# 2. Obtenemos el resumen completo del modelosummary(modelo_estudio)
Call:
lm(formula = Calificaciones ~ Tiempo_Estudio, data = datos)
Residuals:
Min 1Q Median 3Q Max
-1.11465 -0.30262 -0.00942 0.29509 1.10533
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.00118 0.11977 41.76 <2e-16 ***
Tiempo_Estudio 0.09875 0.00488 20.23 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4842 on 98 degrees of freedom
Multiple R-squared: 0.8069, Adjusted R-squared: 0.8049
F-statistic: 409.5 on 1 and 98 DF, p-value: < 2.2e-16
2.4.2 Estimación de la varianza del error
Las fórmulas de la varianza de los estimadores dependen de \(\sigma^2\), la varianza del error poblacional, que es desconocida. Por lo tanto, necesitamos estimarla a partir de nuestros datos. Un estimador insesgado de \(\sigma^2\) es la Media Cuadrática del Error (MSE):
Dividimos por \(n-2\), los grados de libertad del error, porque hemos “gastado” dos grados de libertad de nuestros datos para estimar los dos parámetros, \(\beta_0\) y \(\beta_1\). La raíz cuadrada de la MSE, \(\hat{\sigma}\), se conoce como el error estándar de los residuos y es una medida de la dispersión promedio de los puntos alrededor de la recta de regresión.
2.4.2.1 El error estándar de los residuos y el RMSE
La raíz cuadrada de la MSE, \(\hat{\sigma}\), se conoce formalmente como el error estándar de los residuos (Residual Standard Error). Este valor es nuestra estimación de la desviación estándar del error poblacional, \(\sigma\), y es una medida de la dispersión promedio de los puntos alrededor de la recta de regresión.
\[
\hat{\sigma} = \sqrt{\text{MSE}}
\]
En el campo del modelado predictivo y el machine learning, esta misma cantidad se conoce como la Raíz del Error Cuadrático Medio o RMSE (Root Mean Squared Error). Aunque la fórmula es idéntica, la interpretación del RMSE se centra en la evaluación del rendimiento predictivo del modelo. El RMSE nos dice, en promedio, cuál es la magnitud del error de predicción de nuestro modelo, y tiene la ventaja de estar en las mismas unidades que la variable respuesta \(Y\). Por ejemplo, si estamos prediciendo precios de viviendas en euros, un RMSE de 5000 significa que nuestras predicciones se desvían, en promedio, unos 5000 € de los precios reales.
2.4.3 Análisis de la Varianza (ANOVA) para la significancia de la regresión
Una vez hemos estimado los coeficientes, necesitamos una prueba formal para determinar si el modelo en su conjunto es útil. Es decir, ¿la variable predictora \(X\) explica una porción de la variabilidad de la variable respuesta \(Y\) que sea estadísticamente significativa, o la relación que observamos podría deberse simplemente al azar? El Análisis de la Varianza (ANOVA) nos proporciona la herramienta para responder a esta pregunta a través del contraste F de significancia global.
Las hipótesis de este contraste son:
\(H_0: \beta_1 = 0\): La hipótesis nula postula que no existe una relación lineal entre \(X\) e \(Y\). El modelo no tiene poder explicativo y no es mejor que usar simplemente la media, \(\bar{y}\), como predicción para cualquier valor de \(x\).
\(H_1: \beta_1 \neq 0\): La hipótesis alternativa sostiene que sí existe una relación lineal significativa.
PrecauciónRepaso
Es conveniente repasar el tema de Análisis de la Varianza estudiado en la asignatura de Inferencia, ya que los conceptos son directamente aplicables aquí.
La idea fundamental del ANOVA es comparar la variabilidad que nuestro modelo explica con la variabilidad que no puede explicar (el error residual). Para ello, se descompone la variabilidad total de nuestras observaciones (\(y_i\)) en dos partes ortogonales.
La Suma Total de Cuadrados (SST) mide la variabilidad total de los datos alrededor de su media. Es nuestra referencia base de la dispersión total que hay que explicar. \[
\text{SST} = \sum_{i=1}^{n} (y_i - \bar{y})^2
\]
Esta variabilidad se descompone en:
Suma de Cuadrados de la Regresión (SSR): Mide la parte de la variabilidad total que es explicada por nuestro modelo. Cuantifica cuánto se desvían las predicciones del modelo (\(\hat{y}_i\)) de la media general (\(\bar{y}\)). \[
\text{SSR} = \sum_{i=1}^{n} (\hat{y}_i - \bar{y})^2
\]
Suma de Cuadrados del Error (SSE): Mide la variabilidad residual, es decir, la parte que el modelo no puede capturar. Cuantifica la dispersión de los puntos reales (\(y_i\)) alrededor de la recta de regresión (\(\hat{y}_i\)). \[
\text{SSE} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
\]
La descomposición fundamental de la varianza es, por tanto: \(\text{SST} = \text{SSR} + \text{SSE}\).
Para poder comparar estas sumas de cuadrados de forma justa, las estandarizamos dividiéndolas por sus respectivos grados de libertad, obteniendo así las Medias Cuadráticas (MS):
Finalmente, el estadístico F se construye como el cociente entre la variabilidad explicada por el modelo y la variabilidad no explicada:
\[
F = \frac{\text{MSR}}{\text{MSE}}
\]
Intuitivamente, el estadístico F actúa como una ratio de señal a ruido. La MSR (la “señal”) representa la variabilidad que nuestro modelo captura sistemáticamente, mientras que la MSE (el “ruido”) representa la variabilidad aleatoria o residual. Un valor de F grande nos dice que la señal es mucho más fuerte que el ruido, lo que apoya la hipótesis de que la relación que hemos modelado es real y no fruto del azar.
Toda esta información se organiza de forma estándar en la tabla ANOVA:
Fuente
\(df\)
\(SS\)
\(MS = SS/df\)
Estadístico \(F\)
Regresión
1
\(SSR\)
\(MSR\)
\(F = MSR/MSE\)
Error
\(n-2\)
\(SSE\)
\(MSE\)
Total
\(n-1\)
\(SST\)
Bajo la hipótesis nula (\(H_0: \beta_1 = 0\)), el estadístico \(F\) sigue una distribución \(F\) con 1 y \(n-2\) grados de libertad. Si el p-valor asociado a nuestro estadístico F es suficientemente pequeño (\(p < \alpha\)), rechazamos \(H_0\) y concluimos que nuestro modelo tiene un poder explicativo estadísticamente significativo.
2.4.4 Bondad del ajuste: coeficiente de determinación
El coeficiente de determinación (\(R^2\)) es una medida clave que cuantifica qué proporción de la variabilidad total observada en la muestra (\(y_i\)) es explicada por la relación lineal con \(X\) a través del modelo. Su fórmula se deriva de la descomposición de la varianza:
Donde las sumas de cuadrados se calculan a partir de los datos muestrales:
\(\text{SST} = \sum_{i=1}^n (y_i - \bar{y})^2\): Suma Total de Cuadrados, mide la variabilidad total de las observaciones.
\(\text{SSR} = \sum_{i=1}^n (\hat{y}_i - \bar{y})^2\): Suma de Cuadrados de la Regresión, mide la variabilidad explicada por el modelo.
\(\text{SSE} = \sum_{i=1}^n (y_i - \hat{y}_i)^2\): Suma de Cuadrados del Error, mide la variabilidad no explicada (residual).
Un \(R^2\) cercano a 1 indica que el modelo ajusta bien los datos, mientras que un \(R^2\) cercano a 0 indica un ajuste pobre.
NotaRelación entre R² y el coeficiente de correlación
En el caso específico del modelo de regresión lineal simple, existe una relación directa y simple: el coeficiente de determinación \(R^2\) es literalmente el cuadrado del coeficiente de correlación de Pearson (\(r\)) entre \(X\) e \(Y\).
\[ R^2 = (r_{xy})^2 \]
Esto refuerza la idea de que ambos miden la fuerza de la asociación lineal, aunque \(R^2\) lo hace desde la perspectiva de la varianza explicada por el modelo.
PrecauciónInterpretación de R²
El coeficiente de determinación, \(R^2\), es una métrica muy popular, pero su interpretación requiere cautela. Un valor alto no garantiza un buen modelo, y un valor bajo no siempre implica un modelo inútil. Es fundamental tener en cuenta las siguientes observaciones:
\(R^2\) no mide la linealidad de la relación. Un modelo puede tener un \(R^2\) muy alto incluso si la relación subyacente entre las variables \(X\) e \(Y\) no es lineal. Por ello, un \(R^2\) elevado nunca debe sustituir a un análisis gráfico de los residuos para verificar el supuesto de linealidad.
\(R^2\) es sensible al rango de la variable predictora \(X\). Si el modelo de regresión es adecuado, la magnitud de \(R^2\) aumentará si aumenta la dispersión de las observaciones \(x_i\) (es decir, si \(S_{xx}\) crece). Esto se debe a que un mayor rango en \(X\) tiende a aumentar la Suma Total de Cuadrados (SST), lo que puede inflar el valor de \(R^2\) sin que la precisión del modelo (medida por la MSE) haya mejorado.
Un rango restringido en\(X\) puede producir un \(R^2\) artificialmente bajo. Como consecuencia del punto anterior, si los datos se han recogido en un rango muy estrecho de la variable \(X\), el \(R^2\) puede ser muy pequeño, aunque exista una relación fuerte y significativa entre las variables. Esto podría llevar a la conclusión errónea de que el predictor no es útil.
2.4.5 Inferencia sobre los coeficientes
Además de la prueba F global, podemos realizar inferencias sobre cada parámetro individualmente. Para ello, necesitamos el supuesto de normalidad de los errores.
2.4.5.1 Distribución de los estimadores
Bajo el supuesto de normalidad, se puede demostrar que los estimadores también siguen una distribución Normal: \[
\hat{\beta}_1 \sim N\left(\beta_1, \frac{\sigma^2}{S_{xx}}\right) \quad \quad \quad \hat{\beta}_0 \sim N\left(\beta_0, \sigma^2 \left[ \frac{1}{n} + \frac{\bar{x}^2}{S_{xx}} \right]\right)
\] Al estandarizar y reemplazar la desconocida \(\sigma^2\) por su estimador \(\hat{\sigma}^2 = \text{MSE}\), obtenemos un estadístico que sigue una distribución t-Student con \(n-2\) grados de libertad: \[
t = \frac{\hat{\beta}_1 - \beta_1}{\text{SE}(\hat{\beta}_1)} \sim t_{n-2}\] donde \(\text{SE}(\hat{\beta}_1) = \sqrt{\frac{\text{MSE}}{S_{xx}}}\) es el error estándar del estimador \(\hat{\beta}_1\).
2.4.5.2 Contraste de hipótesis para la pendiente
El contraste más común es el de la significancia de la pendiente: * \(H_0: \beta_1 = 0\) * \(H_1: \beta_1 \neq 0\)
Bajo \(H_0\), el estadístico de contraste es: \[
t_0 = \frac{\hat{\beta}_1}{\text{SE}(\hat{\beta}_1)}\]
Rechazamos \(H_0\) si \(|t_0| > t_{\alpha/2, n-2}\) o, equivalentemente, si el p-valor asociado es menor que \(\alpha\).
NotaRelación entre el contraste F y el contraste t
En el contexto de la regresión lineal simple (y solo en este caso), el contraste F para la significancia global del modelo es matemáticamente equivalente al contraste t para la significancia del coeficiente \(\beta_1\). Se puede demostrar que \(F = t^2\), y el p-valor de ambos contrastes será idéntico.
2.4.5.3 Intervalo de confianza para la pendiente
A partir de la distribución t, podemos construir un intervalo de confianza al \(100(1-\alpha)\%\) para el verdadero valor de la pendiente \(\beta_1\): \[
\hat{\beta}_1 \pm t_{\alpha/2, n-2} \cdot \text{SE}(\hat{\beta}_1)
\] Este intervalo nos da un rango de valores plausibles para el efecto de \(X\) sobre \(Y\). Si el intervalo no contiene el cero, es equivalente a rechazar la hipótesis nula \(H_0: \beta_1 = 0\).
ImportantePara recordar
En los programas estadísticos se suele proporcionar el p-valor del contraste. Puedes repasar el significado de p-valor proporcionado en la asignatura de Inferencia.
TipEjemplo: Interpretación del summary
La función summary() en R nos proporciona toda esta información.
summary(modelo_estudio)
Call:
lm(formula = Calificaciones ~ Tiempo_Estudio, data = datos)
Residuals:
Min 1Q Median 3Q Max
-1.11465 -0.30262 -0.00942 0.29509 1.10533
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.00118 0.11977 41.76 <2e-16 ***
Tiempo_Estudio 0.09875 0.00488 20.23 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4842 on 98 degrees of freedom
Multiple R-squared: 0.8069, Adjusted R-squared: 0.8049
F-statistic: 409.5 on 1 and 98 DF, p-value: < 2.2e-16
Interpretación:
Coefficients: El p-valor para Tiempo_Estudio (<0.001) es muy pequeño, por lo que rechazamos \(H_0\) y concluimos que la variable es un predictor significativo.
R-squared: El valor de \(R^2\) (0.81) nos indica que el 81% de la variabilidad en las calificaciones es explicada por el tiempo de estudio.
F-statistic: El p-valor del estadístico F
confirma que el modelo en su conjunto es estadísticamente significativo.
2.5 Predicción de nuevas observaciones
Una vez que hemos ajustado y validado un modelo de regresión, uno de sus propósitos más importantes es utilizarlo para hacer predicciones. Sin embargo, es fundamental distinguir entre dos tipos de predicción:
Estimar la respuesta media para un valor dado de \(X\). Por ejemplo: “¿Cuál es la calificación promedio que esperamos para todos los estudiantes que estudian 25 horas semanales?”.
Predecir una respuesta individual para un valor dado de \(X\). Por ejemplo: “Si un estudiante concreto estudia 25 horas semanales, ¿entre qué valores esperamos que se encuentre su calificación?”.
Estos dos objetivos, aunque parecidos, responden a preguntas distintas y manejan diferentes fuentes de incertidumbre, lo que da lugar a dos tipos de intervalos.
2.5.1 Intervalo de confianza para la respuesta media
Este intervalo estima el valor esperado de \(Y\) para un valor concreto del regresor, \(x_0\). Su objetivo es acotar dónde se encuentra la línea de regresión poblacional verdadera para ese punto \(x_0\). La estimación puntual es \(\hat{y}_0 = \hat{\beta}_0 + \hat{\beta}_1 x_0\).
El intervalo de confianza al \(100(1-\alpha)\%\) para la respuesta media \(E[Y|X=x_0]\) viene dado por:
La anchura de este intervalo depende de dos fuentes de error: la incertidumbre en la estimación de la recta y la distancia del punto \(x_0\) a la media \(\bar{x}\). El intervalo es más estrecho cerca del centro de los datos y más ancho en los extremos.
2.5.2 Intervalo de predicción para una respuesta individual
Este intervalo es el que debemos usar cuando queremos predecir el valor para una única observación futura, no para la media. Como indicas, este intervalo debe tener en cuenta dos fuentes de variabilidad:
La incertidumbre sobre la localización de la verdadera recta de regresión (la misma que en el intervalo de confianza).
La variabilidad inherente de una observación individual alrededor de la recta de regresión (el error aleatorio \(\varepsilon_i\), cuya varianza estimamos con la MSE).
Por esta razón, el intervalo de predicción siempre será más ancho que el intervalo de confianza para la respuesta media. El intervalo de predicción al \(100(1-\alpha)\%\) para una observación futura \(y_0\) en el punto \(x_0\) es:
La única diferencia matemática es el “+1” dentro de la raíz cuadrada, que representa la varianza \(\sigma^2\) del error de una sola observación.
2.5.2.1 Predicción para la media de m observaciones futuras
Si se desea un intervalo de predicción para la media de m futuras observaciones en un valor \(x_0\), la fórmula se modifica ligeramente. Este intervalo será más estrecho que el de una sola observación pero más ancho que el de la respuesta media:
Vamos a calcular y visualizar los intervalos para nuestro modelo de estudio. Usaremos la función predict() de R, que calcula estos intervalos de forma automática.
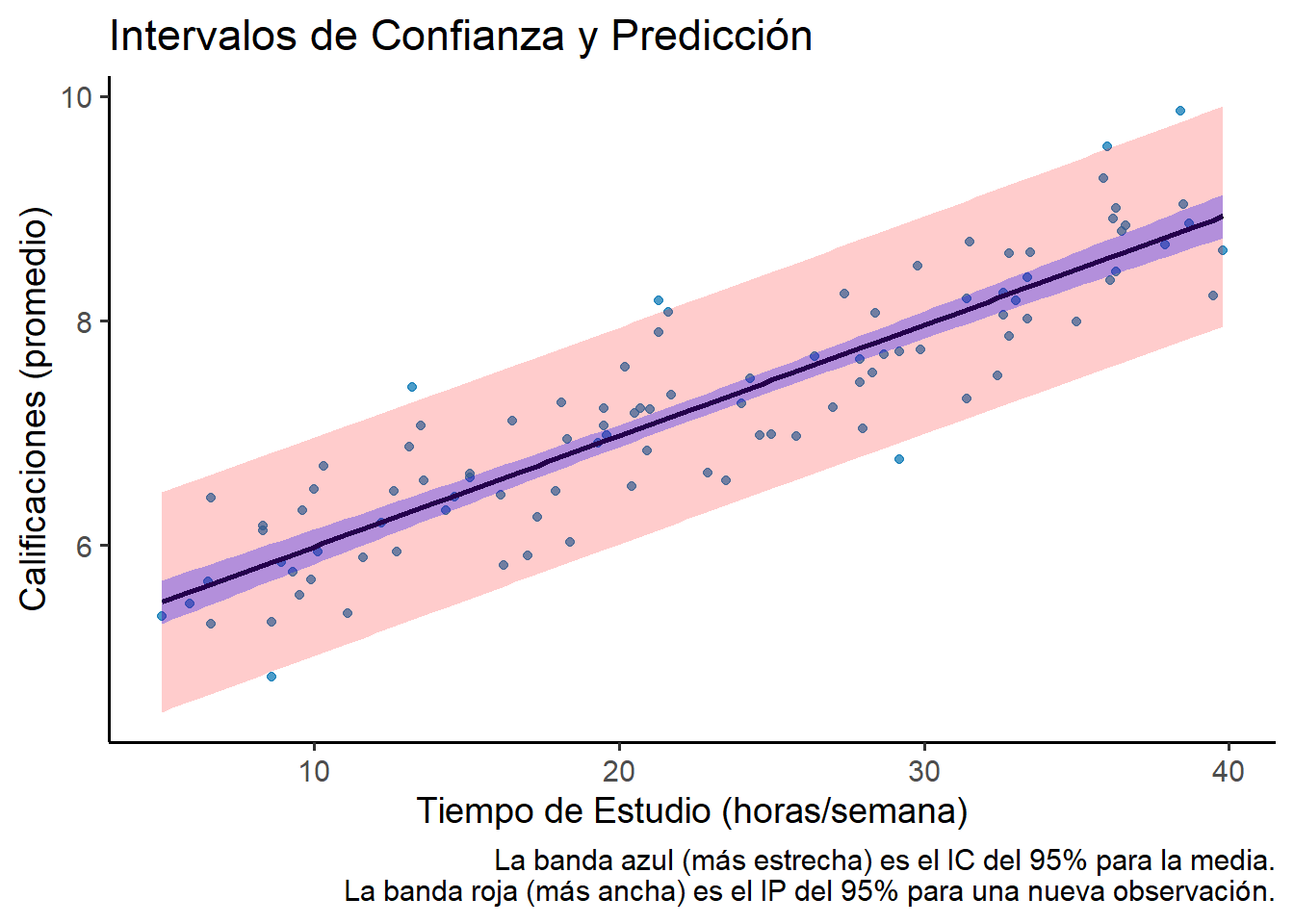
# 1. Crear una secuencia de nuevos valores de X para predecirnuevos_datos <-data.frame(Tiempo_Estudio =seq(min(datos$Tiempo_Estudio), max(datos$Tiempo_Estudio), length.out =100))# 2. Calcular el intervalo de confianza para la RESPUESTA MEDIAconf_interval <-predict( modelo_estudio, newdata = nuevos_datos, interval ="confidence", level =0.95)# 3. Calcular el intervalo de predicción para una OBSERVACIÓN INDIVIDUALpred_interval <-predict( modelo_estudio, newdata = nuevos_datos, interval ="prediction", level =0.95)# 4. Unir todo para graficar con ggplot2plot_data <-cbind(nuevos_datos, as.data.frame(conf_interval), pred_pred =as.data.frame(pred_interval))colnames(plot_data) <-c("Tiempo_Estudio", "fit_conf", "lwr_conf", "upr_conf", "fit_pred", "lwr_pred", "upr_pred")# 5. Visualizaciónggplot() +# Capa 1: Puntos originales del dataframe 'datos'geom_point(data = datos, aes(x = Tiempo_Estudio, y = Calificaciones), color ="#0072B2", alpha =0.7) +# Capa 2: Línea de regresión del dataframe 'plot_data'geom_line(data = plot_data, aes(x = Tiempo_Estudio, y = fit_conf), color ="black", linewidth =1) +# Capa 3: Banda de predicción (roja) del dataframe 'plot_data'geom_ribbon(data = plot_data, aes(x = Tiempo_Estudio, ymin = lwr_pred, ymax = upr_pred), fill ="red", alpha =0.2) +# Capa 4: Banda de confianza (azul) del dataframe 'plot_data'geom_ribbon(data = plot_data, aes(x = Tiempo_Estudio, ymin = lwr_conf, ymax = upr_conf), fill ="blue", alpha =0.3) +# Etiquetas y temalabs(title ="Intervalos de Confianza y Predicción",x ="Tiempo de Estudio (horas/semana)",y ="Calificaciones (promedio)",caption ="La banda azul (más estrecha) es el IC del 95% para la media.\nLa banda roja (más ancha) es el IP del 95% para una nueva observación." ) +theme_classic(base_size =14)
Figura 2.2: Comparación visual del intervalo de confianza (azul, más estrecho) y el intervalo de predicción (rojo, más ancho).
El gráfico muestra claramente que la incertidumbre al predecir una calificación individual es mucho mayor que la incertidumbre al estimar la calificación promedio. Ambas bandas se ensanchan al alejarse del centro de los datos.
Si quisiéramos una predicción para un estudiante que estudia 25 horas:
dato_nuevo <-data.frame(Tiempo_Estudio =25)# Guardamos la predicción para la media en un objetopred_media <-predict(modelo_estudio, newdata = dato_nuevo, interval ="confidence")# Guardamos la predicción para un individuo en un objetopred_indiv <-predict(modelo_estudio, newdata = dato_nuevo, interval ="prediction")
Interpretación:
Con un 95% de confianza, la calificación promedio de los estudiantes que estudian 25 horas está entre 7.37 y 7.57.
Con un 95% de confianza, la calificación de un estudiante concreto que estudia 25 horas estará entre 6.5 y 8.44.
2.6 Diagnóstico del Modelo
Una vez que hemos ajustado un modelo y evaluado su significancia, el trabajo no ha terminado. Un paso crucial, a menudo subestimado, es el diagnóstico del modelo(Fox y Weisberg 2018; Harrell 2015). Este proceso consiste en verificar si se cumplen los supuestos del modelo de regresión lineal clásico. La fiabilidad de nuestras inferencias (los p-valores de los contrastes t y F, y los intervalos de confianza) depende directamente de la validez de estos supuestos.
El diagnóstico se realiza principalmente a través del análisis de los residuos del modelo (\(e_i = y_i - \hat{y}_i\)). Los residuos son nuestra mejor aproximación empírica de los errores teóricos no observables (\(\varepsilon_i\)). A continuación, se detalla cómo verificar cada uno de los supuestos clave.
2.6.1 Linealidad
Este supuesto establece que la relación entre la variable predictora \(X\) y el valor esperado de la variable respuesta \(Y\) es, en promedio, una línea recta: \(E[Y | X] = \beta_0 + \beta_1 X\).
Métodos de diagnóstico:
Diagnóstico visual: El gráfico de residuos (\(e_i\)) frente a los valores ajustados por el modelo (\(\hat{y}_i\)) es la herramienta fundamental. La lógica es sencilla pero potente: si el modelo lineal es adecuado, los errores que comete (los residuos) deberían ser completamente aleatorios, sin guardar relación alguna con la magnitud de las predicciones.
Test de Ramsey RESET: Este test estadístico detecta violaciones de la forma funcional mediante la inclusión de términos no lineales (\(\hat{y}^2, \hat{y}^3, ...\)) en el modelo.
H₀: La forma funcional es correcta (lineal)
H₁: La forma funcional es incorrecta (no lineal)
Estadístico: Sigue una distribución F bajo H₀
Interpretación: p-valor bajo indica violación de linealidad
En un escenario ideal, el gráfico debería parecer una nube de puntos distribuida horizontalmente y sin estructura aparente, centrada en la línea del cero. Esto nos indica que los errores son, en promedio, nulos para todos los niveles de predicción, cumpliendo así el supuesto de linealidad. La línea roja que R superpone en este gráfico, que suaviza la tendencia de los puntos, debería ser prácticamente plana y pegada al cero, confirmando la ausencia de patrones.
TipEjemplo de un modelo válido
Para nuestro modelo_estudio, podemos generar específicamente el primer gráfico de diagnóstico, que es el de Residuos vs. Valores Ajustados.
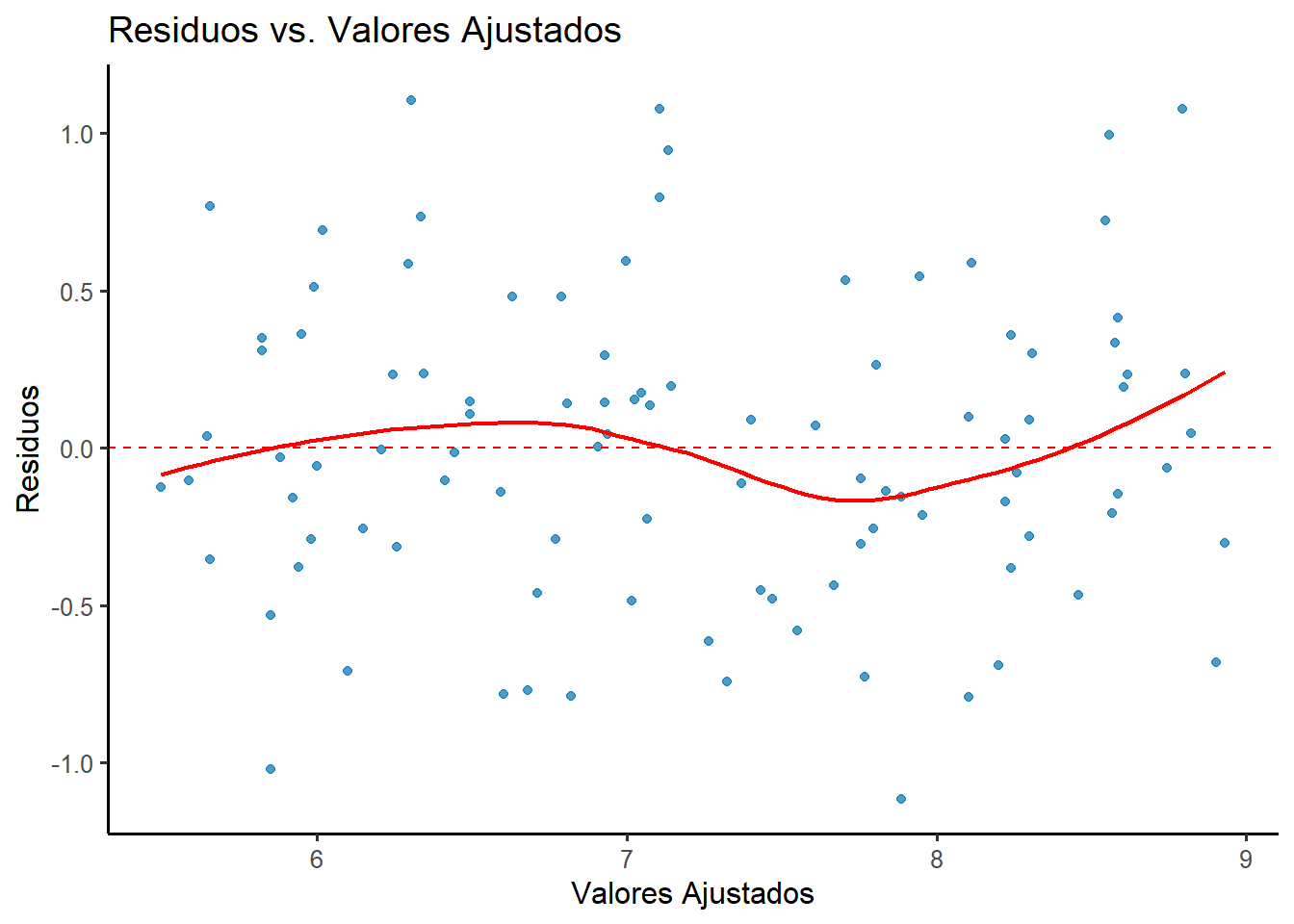
# Crear un dataframe con los datos para ggplot2library(ggplot2)library(broom)# Extraer residuos y valores ajustadosdatos_diagnostico <-data.frame(residuos =residuals(modelo_estudio),valores_ajustados =fitted(modelo_estudio))# Gráfico de Residuos vs. Valores Ajustados con ggplot2ggplot(datos_diagnostico, aes(x = valores_ajustados, y = residuos)) +geom_point(color ="#0072B2", alpha =0.7) +geom_hline(yintercept =0, color ="red", linetype ="dashed") +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Residuos vs. Valores Ajustados",x ="Valores Ajustados",y ="Residuos" ) +theme_classic(base_size =12)
Figura 2.3: Gráfico de Residuos vs. Valores Ajustados para el modelo de estudio. No se observan patrones.
Como se puede observar, los puntos se distribuyen de forma aleatoria alrededor de la línea horizontal en cero. La línea roja, que suaviza la tendencia de los residuos, es prácticamente plana. Esto es un claro indicativo de que el supuesto de linealidad se cumple en nuestro modelo.
Por el contrario, la aparición de un patrón sistemático en los residuos es la señal de alarma de que algo anda mal. En lo que respecta al supuesto de linealidad, la evidencia más clara de una violación es una tendencia curvilínea (como una “U” o una parábola). Este patrón nos dice que el modelo es estructuralmente incapaz de capturar la forma de los datos y, por lo tanto, comete errores predecibles. Por ejemplo, puede subestimar la respuesta en los extremos (generando residuos positivos) y sobreestimarla en el centro (residuos negativos), lo que invalida el modelo lineal.
TipContraejemplo: Violación del supuesto de linealidad
Ahora, vamos a simular a propósito unos datos que siguen una relación cuadrática (curva) y ajustaremos incorrectamente un modelo lineal para ver cómo se manifiesta el problema en el gráfico de diagnóstico.
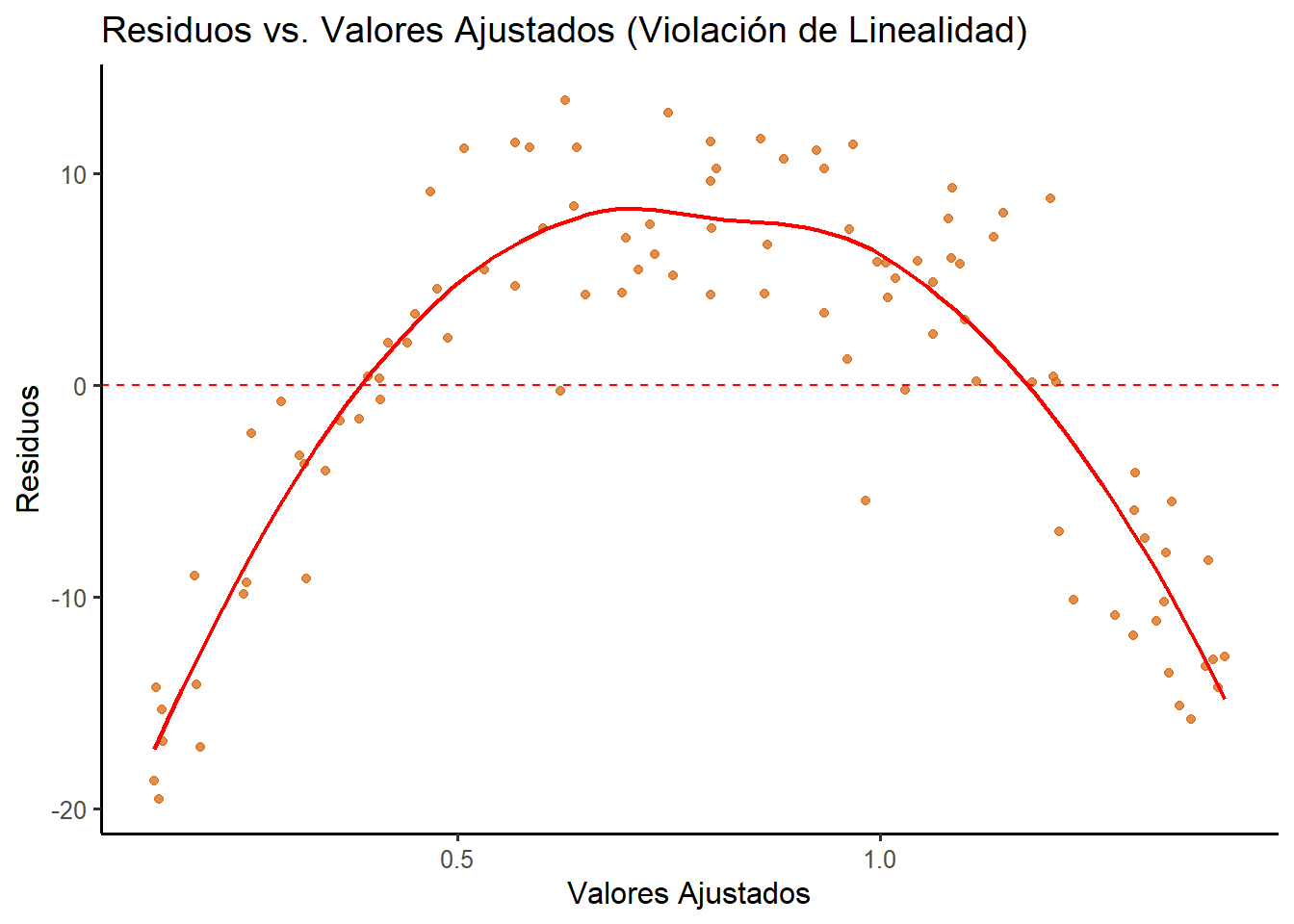
# 1. Simulación de datos no linealesset.seed(42) # Nueva semilla para este ejemplox_no_lineal <-runif(100, 0, 10)# La relación verdadera es cuadrática (y = 10 - (x-5)^2) más un errory_no_lineal <-10- (x_no_lineal -5)^2+rnorm(100, 0, 4)datos_no_lineal <-data.frame(x = x_no_lineal, y = y_no_lineal)# 2. Ajuste de un modelo lineal (incorrecto)modelo_no_lineal <-lm(y ~ x, data = datos_no_lineal)# 3. Gráfico de Residuos vs. Valores Ajustados con ggplot2datos_diag_no_lineal <-data.frame(residuos =residuals(modelo_no_lineal),valores_ajustados =fitted(modelo_no_lineal))ggplot(datos_diag_no_lineal, aes(x = valores_ajustados, y = residuos)) +geom_point(color ="#D55E00", alpha =0.7) +geom_hline(yintercept =0, color ="red", linetype ="dashed") +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Residuos vs. Valores Ajustados (Violación de Linealidad)",x ="Valores Ajustados",y ="Residuos" ) +theme_classic(base_size =12)
Figura 2.4: Patrón curvo evidente en los residuos, violando el supuesto de linealidad.
El gráfico de diagnóstico es inequívoco. A diferencia del ejemplo anterior, donde los puntos formaban una nube aleatoria, aquí los residuos dibujan un patrón parabólico perfecto (una “U” invertida). La línea roja de tendencia, en lugar de ser plana, sigue fielmente esta curva.
Test de Ramsey RESET para Linealidad
Además del diagnóstico visual, podemos usar el test de Ramsey RESET (Regression Equation Specification Error Test) para detectar violaciones de linealidad:
suppressPackageStartupMessages(library(lmtest))# Test RESET para el modelo correcto (horas de estudio)reset_resultado <-resettest(modelo_estudio, power =2:3, type ="fitted")print(reset_resultado)
El test de Ramsey RESET confirma nuestro diagnóstico visual:
Para el modelo correcto: p-valor = 0.3535 → No rechazamos H₀ (forma funcional correcta)
Para el modelo no lineal: p-valor = 0 → Rechazamos H₀ (forma funcional incorrecta)
2.6.2 Homocedasticidad
El supuesto de homocedasticidad establece que la varianza de los errores del modelo debe ser constante para todos los niveles de la variable predictora. Es decir, la dispersión de los datos alrededor de la línea de regresión es la misma en todo su recorrido (\(Var(\varepsilon_i | X_i) = \sigma^2\)). La violación de este supuesto se conoce como heterocedasticidad, y es un problema común en el modelado.
Métodos de diagnóstico:
Diagnóstico visual: El gráfico Scale-Location muestra la raíz cuadrada de los residuos estandarizados absolutos frente a los valores ajustados. Una línea horizontal indica homocedasticidad.
Test de Breusch-Pagan: Test clásico para detectar heterocedasticidad.
H₀: Homocedasticidad (varianza constante)
H₁: Heterocedasticidad
Estadístico: LM ~ χ² bajo H₀
Test de White: Versión más robusta que no asume una forma específica de heterocedasticidad.
H₀: Homocedasticidad
H₁: Heterocedasticidad (forma general)
Ventaja: No requiere especificar la forma funcional de la heterocedasticidad
¿Por qué es tan importante? Si un modelo es heteroscedástico, los errores estándar de los coeficientes (\(\beta_0, \beta_1\)) estarán calculados de forma incorrecta. Como consecuencia, los intervalos de confianza y los contrastes de hipótesis (p-valores) no serán fiables, pudiendo llevarnos a conclusiones erróneas sobre la significancia de nuestras variables.
NotaSobre los residuos estandarizados
Los residuos simples (\(e_i = y_i - \hat{y}_i\)) no son directamente comparables entre sí porque tienen diferentes varianzas dependiendo de su apalancamiento (leverage). Por eso, en los gráficos de diagnóstico se utilizan residuos estandarizados o, mejor aún, residuos estudentizados, que ponen todos los residuos en una escala común. Esto facilita la identificación de patrones y valores atípicos. La explicación detallada de estos conceptos se encuentra en la sección de identificación de observaciones influyentes.
La heteroscedasticidad se detecta principalmente buscando patrones en la dispersión de los residuos.
Gráfico de Residuos vs. Valores Ajustados: Como en la prueba de linealidad, este gráfico es nuestra primera herramienta. Aquí no buscamos patrones en la media de los residuos (que debe ser cero), sino en su dispersión. La señal de alarma inequívoca de heteroscedasticidad es una forma de embudo o megáfono, donde la dispersión de los residuos aumenta o disminuye a medida que cambian los valores ajustados.
Gráfico Scale-Location: Este gráfico está diseñado específicamente para detectar heteroscedasticidad. Muestra la raíz cuadrada de los residuos estandarizados en el eje Y (sqrt(|Standardized residuals|)) frente a los valores ajustados en el eje X. Al usar la raíz cuadrada, se suaviza la distribución de los residuos, haciendo los patrones de varianza más fáciles de ver. Si la varianza es constante (homocedasticidad), deberíamos ver una nube de puntos aleatoria con una línea de tendencia roja aproximadamente plana. Una pendiente en esta línea roja indica que la varianza cambia con el nivel de la respuesta.
Prueba de Breusch-Pagan: Es el contraste de hipótesis formal. Su lógica es ingeniosa: realiza una regresión auxiliar donde intenta predecir los residuos al cuadrado a partir de las variables predictoras originales. Si las variables predictoras ayudan a explicar la magnitud de los residuos al cuadrado, significa que la varianza del error depende de los predictores, y por tanto, hay heteroscedasticidad.
Hipótesis Nula (\(H_0\)): El modelo es homocedástico.
Decisión: Un p-valor pequeño (p. ej., < 0.05) es evidencia en contra de la homocedasticidad.
TipEjemplo de un modelo válido
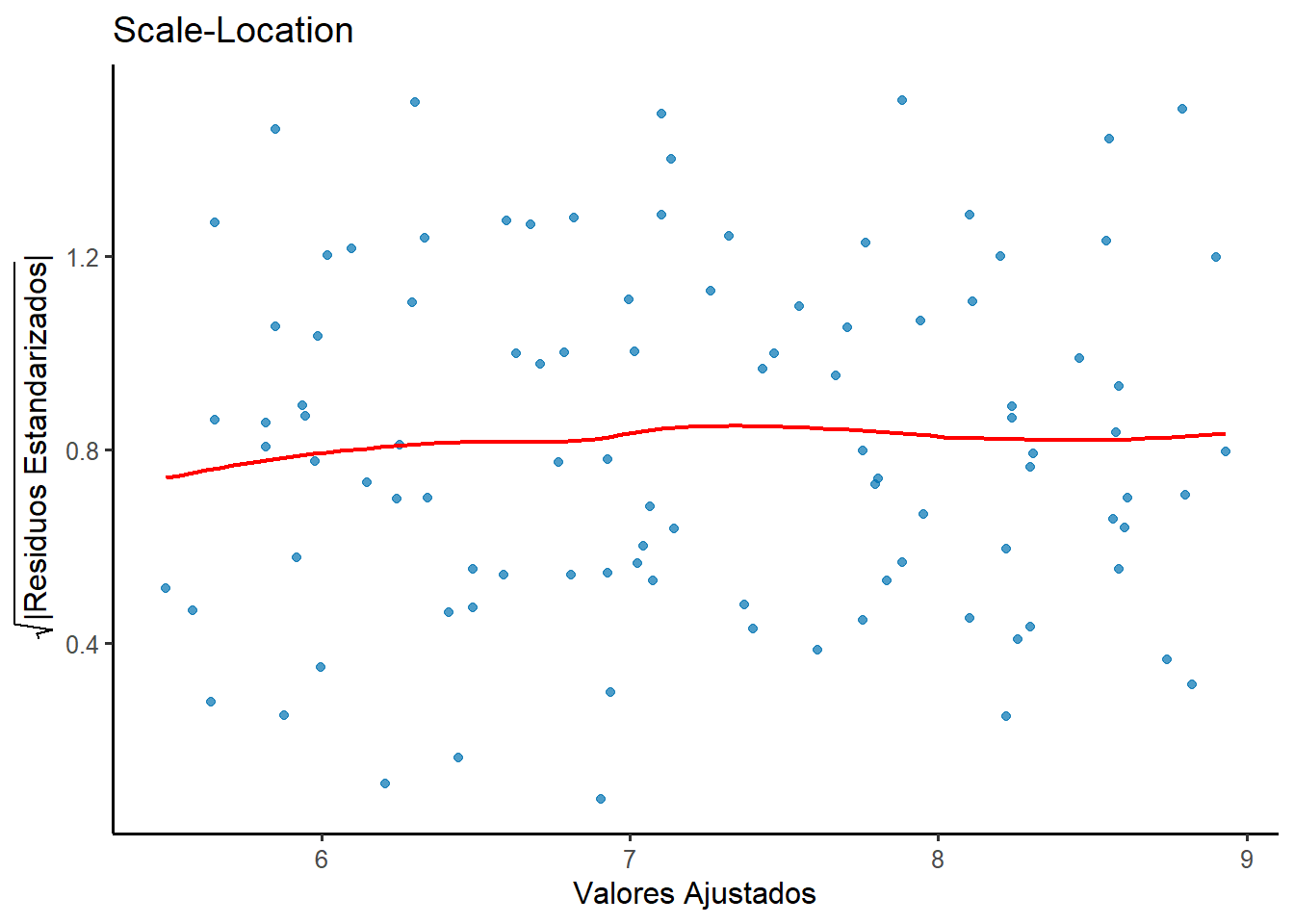
Analicemos nuestro modelo_estudio. Nos centraremos en el gráfico Scale-Location (which = 3) y en la prueba de Breusch-Pagan.
# Crear datos para el gráfico Scale-Locationdatos_scale_loc <-data.frame(valores_ajustados =fitted(modelo_estudio),residuos_std_sqrt =sqrt(abs(rstandard(modelo_estudio))))# Gráfico Scale-Location con ggplot2ggplot(datos_scale_loc, aes(x = valores_ajustados, y = residuos_std_sqrt)) +geom_point(color ="#0072B2", alpha =0.7) +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Scale-Location",x ="Valores Ajustados",y =expression(sqrt("|Residuos Estandarizados|")) ) +theme_classic(base_size =12)# Prueba de Breusch-PagansuppressPackageStartupMessages(library(lmtest))bp_resultado <-bptest(modelo_estudio)print(bp_resultado)
studentized Breusch-Pagan test
data: modelo_estudio
BP = 0.019638, df = 1, p-value = 0.8886
# Prueba de White (versión robusta)white_resultado <-bptest(modelo_estudio, ~fitted(modelo_estudio) +I(fitted(modelo_estudio)^2))print(white_resultado)
studentized Breusch-Pagan test
data: modelo_estudio
BP = 0.12238, df = 2, p-value = 0.9406
Figura 2.5: Gráfico Scale-Location para el modelo de estudio. La línea de tendencia es casi plana.
El diagnóstico es positivo. En el gráfico Scale-Location, la línea roja es casi horizontal, lo que indica que la varianza de los residuos es estable a lo largo de los valores ajustados. Esto se confirma con ambas pruebas:
Breusch-Pagan: p-valor = 0.8886 → No rechazamos H₀ (homocedasticidad)
White: p-valor = 0.9406 → No rechazamos H₀ (varianza constante) Nuestro modelo cumple el supuesto.
TipContraejemplo: Violación del supuesto de homocedasticidad
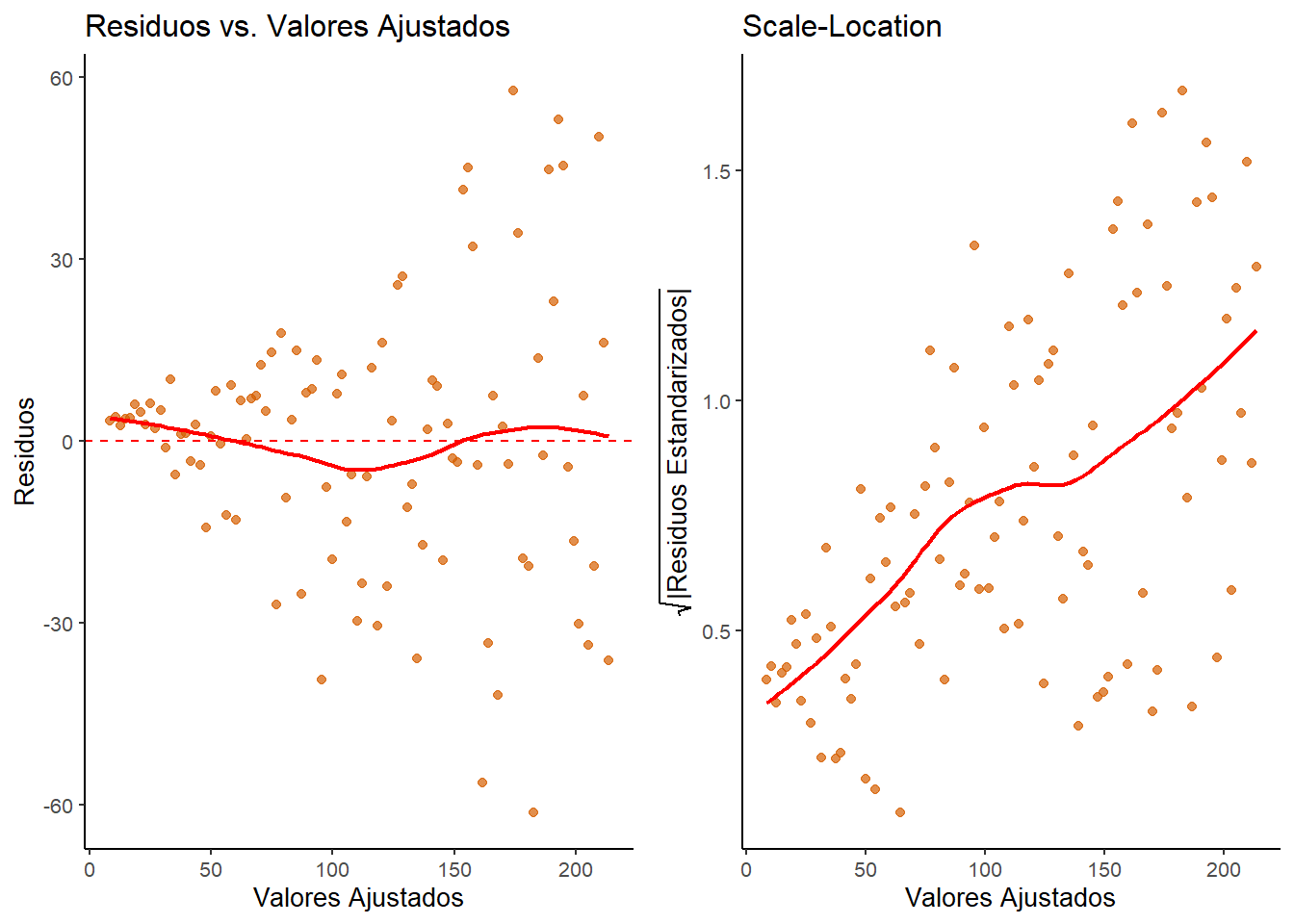
Ahora, simularemos datos donde el error aumenta a medida que x crece, un caso clásico de heteroscedasticidad.
# 1. Simulación de datos heteroscedásticosset.seed(101)x_hetero <-1:100y_hetero <-10+2* x_hetero +rnorm(100, mean =0, sd =0.4* x_hetero)datos_hetero <-data.frame(x = x_hetero, y = y_hetero)modelo_hetero <-lm(y ~ x, data = datos_hetero)# 2. Preparar datos para los gráficosdatos_diag_hetero <-data.frame(residuos =residuals(modelo_hetero),valores_ajustados =fitted(modelo_hetero),residuos_std_sqrt =sqrt(abs(rstandard(modelo_hetero))))# 3. Gráfico de Residuos vs. Valores Ajustadosp1 <-ggplot(datos_diag_hetero, aes(x = valores_ajustados, y = residuos)) +geom_point(color ="#D55E00", alpha =0.7) +geom_hline(yintercept =0, color ="red", linetype ="dashed") +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Residuos vs. Valores Ajustados",x ="Valores Ajustados",y ="Residuos" ) +theme_classic(base_size =10)# 4. Gráfico Scale-Locationp2 <-ggplot(datos_diag_hetero, aes(x = valores_ajustados, y = residuos_std_sqrt)) +geom_point(color ="#D55E00", alpha =0.7) +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Scale-Location",x ="Valores Ajustados",y =expression(sqrt("|Residuos Estandarizados|")) ) +theme_classic(base_size =10)# 5. Mostrar ambos gráficos lado a ladolibrary(gridExtra)grid.arrange(p1, p2, ncol =2)# 6. Prueba de Breusch-PagansuppressPackageStartupMessages(library(lmtest))test_values <-bptest(modelo_hetero)
Figura 2.6: Diagnóstico de heteroscedasticidad. Izquierda: Gráfico de Residuos vs. Ajustados (patrón de embudo). Derecha: Gráfico Scale-Location (tendencia ascendente).
Los resultados son un libro de texto sobre la heteroscedasticidad.
El gráfico de Residuos vs. Valores Ajustados (izquierda) tiene una forma de embudo inconfundible: la dispersión de los puntos aumenta drásticamente de izquierda a derecha.
El gráfico Scale-Location (derecha) confirma el problema, mostrando una línea roja con una clara pendiente ascendente.
La prueba de Breusch-Pagan arroja un p-valor 7.43e-07, dándonos una fuerte evidencia estadística para rechazar la hipótesis nula de homocedasticidad.
Este modelo viola claramente el supuesto, y las inferencias basadas en él (como el p-valor del coeficiente de x) no serían fiables.
2.6.3 Normalidad de los residuos
Este supuesto postula que los residuos del modelo (\(\varepsilon_i\)) siguen una distribución normal: \(\varepsilon_i \sim N(0, \sigma^2)\). Es especialmente importante para la validez de los intervalos de confianza y los contrastes de hipótesis cuando el tamaño de la muestra es pequeño.
Métodos de diagnóstico:
Diagnóstico visual:
Gráfico Q-Q: Los puntos deben seguir la línea diagonal si hay normalidad
Histograma: Debe mostrar forma campaniforme y simétrica
Test de Shapiro-Wilk: Test más potente para muestras pequeñas y medianas (n < 50).
H₀: Los residuos siguen distribución normal
H₁: Los residuos no siguen distribución normal
Limitación: Muy sensible en muestras grandes
Test de Jarque-Bera: Basado en medidas de asimetría y curtosis.
H₀: Los residuos son normales (asimetría = 0, curtosis = 3)
H₁: Los residuos no son normales
Ventaja: Menos sensible al tamaño muestral que Shapiro-Wilk
Para evaluar la normalidad disponemos de estas herramientas visuales y analíticas:
Gráfico Normal Q-Q (Normal Q-Q Plot): Compara los cuantiles de los residuos estandarizados con los cuantiles de una distribución normal teórica. Los puntos deben caer muy cerca de la línea diagonal de 45 grados.
Histograma de los Residuos: Un simple histograma de los residuos debe mostrar una forma aproximada de campana de Gauss.
Prueba de Shapiro-Wilk: Es uno de los contrastes más potentes para la normalidad.
Hipótesis Nula (\(H_0\)): Los residuos provienen de una distribución normal.
Decisión: Un p-valor pequeño (< 0.05) sugiere rechazar \(H_0\).
TipEjemplo de normalidad válida
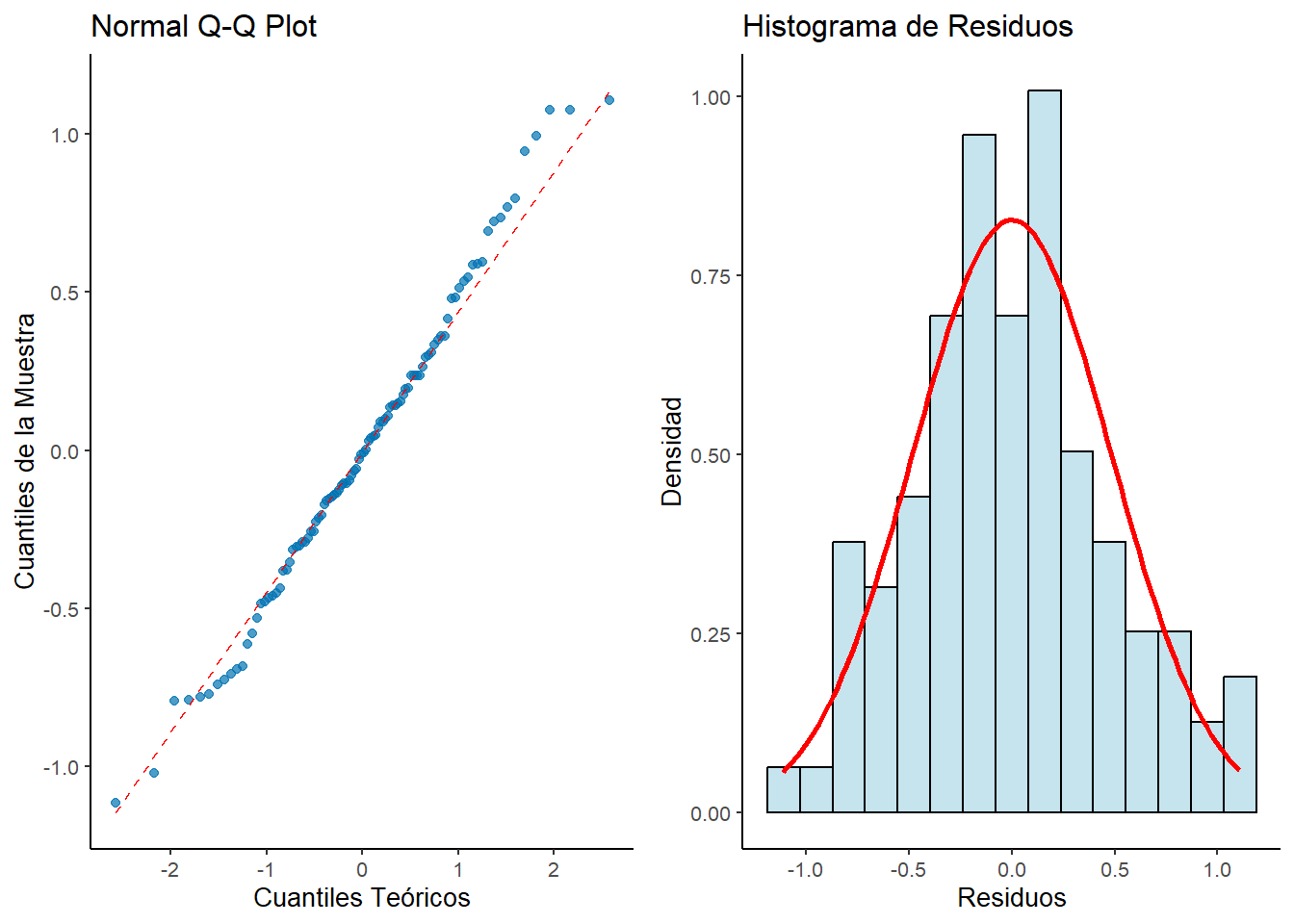
Para nuestro modelo_estudio, examinamos la normalidad mediante el gráfico Q-Q y la prueba de Shapiro-Wilk.
# Crear datos para los gráficosresiduos <-residuals(modelo_estudio)# 1. Gráfico Q-Q con ggplot2datos_qq <-data.frame(residuos = residuos)p1 <-ggplot(datos_qq, aes(sample = residuos)) +geom_qq(color ="#0072B2", alpha =0.7) +geom_qq_line(color ="red", linetype ="dashed") +labs(title ="Normal Q-Q Plot",x ="Cuantiles Teóricos",y ="Cuantiles de la Muestra" ) +theme_classic(base_size =10)# 2. Histograma con ggplot2datos_hist <-data.frame(residuos = residuos)p2 <-ggplot(datos_hist, aes(x = residuos)) +geom_histogram(aes(y =after_stat(density)), bins =15, fill ="lightblue", color ="black", alpha =0.7) +stat_function(fun = dnorm, args =list(mean =mean(residuos), sd =sd(residuos)),color ="red", linewidth =1) +labs(title ="Histograma de Residuos",x ="Residuos",y ="Densidad" ) +theme_classic(base_size =10)# 3. Mostrar ambos gráficos lado a ladolibrary(gridExtra)grid.arrange(p1, p2, ncol =2)# Prueba de Shapiro-WilksuppressPackageStartupMessages(library(lmtest))shapiro_resultado <-shapiro.test(residuals(modelo_estudio))print(shapiro_resultado)
Shapiro-Wilk normality test
data: residuals(modelo_estudio)
W = 0.99008, p-value = 0.671
# Prueba de Jarque-BerasuppressPackageStartupMessages(library(tseries))jb_resultado <-jarque.bera.test(residuals(modelo_estudio))print(jb_resultado)
Jarque Bera Test
data: residuals(modelo_estudio)
X-squared = 0.68515, df = 2, p-value = 0.7099
Figura 2.7: Diagnóstico de normalidad del modelo de estudio. Izquierda: Q-Q Plot. Derecha: Histograma de residuos.
El diagnóstico es excelente. En el gráfico Q-Q, los puntos se alinean muy bien con la línea diagonal, indicando normalidad. El histograma muestra una distribución aproximadamente simétrica que se ajusta bien a la curva normal teórica (línea roja). Ambas pruebas estadísticas confirman la normalidad:
Shapiro-Wilk: p-valor = 0.671 → No rechazamos H₀ (normalidad)
Jarque-Bera: p-valor = 0.7099 → No rechazamos H₀ (normalidad)
TipContraejemplo: Violación del supuesto de normalidad
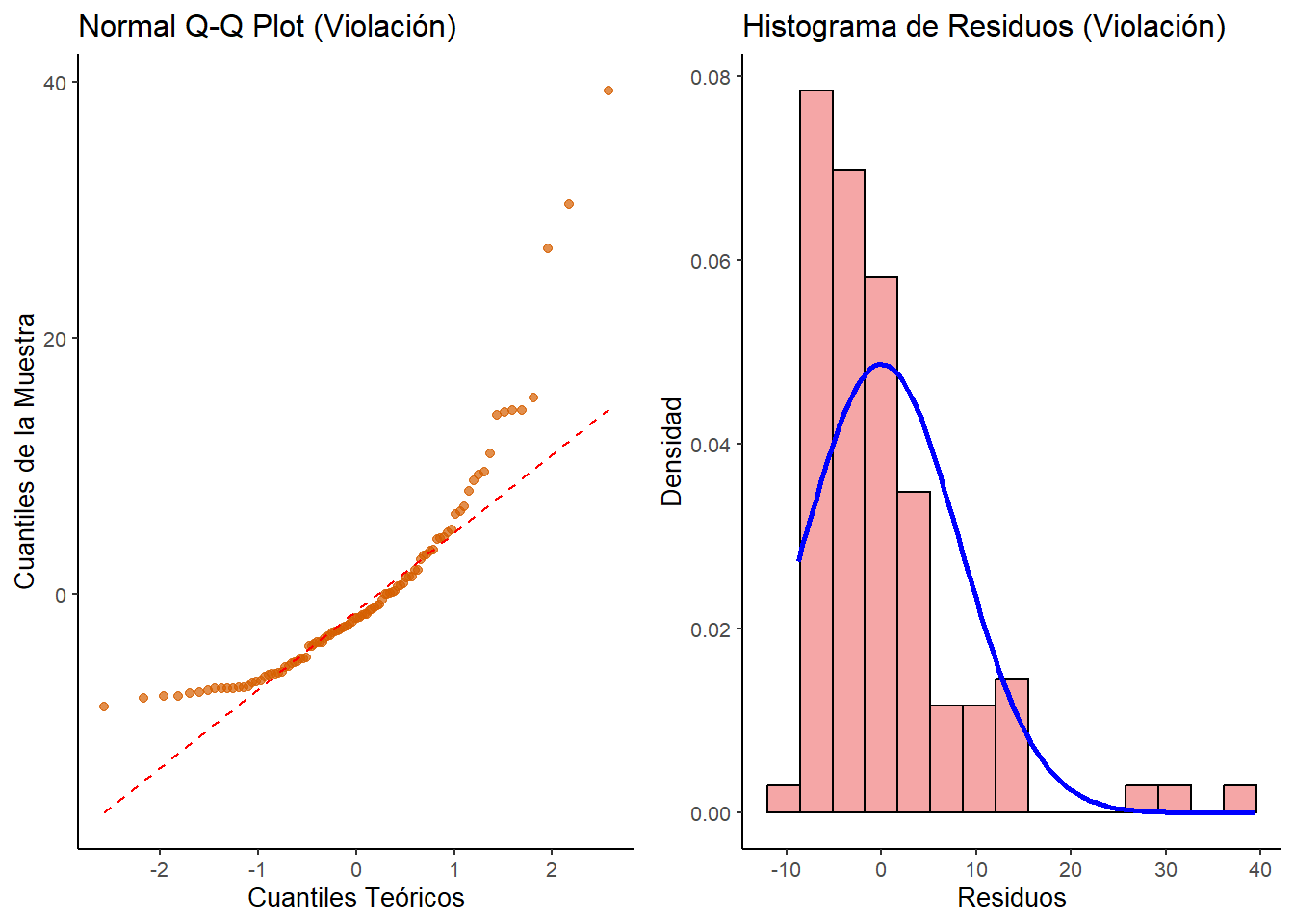
Ahora simularemos datos donde los residuos siguen una distribución asimétrica (distribución exponencial) para mostrar una violación clara del supuesto de normalidad.
# 1. Simulación de datos con errores no normales (exponenciales)set.seed(456)x_no_normal <-1:100# Errores exponenciales (muy asimétricos) centrados en 0errores_exp <-rexp(100, rate =1) -1# Restamos 1 para centrar en 0y_no_normal <-5+2* x_no_normal + errores_exp *10datos_no_normal <-data.frame(x = x_no_normal, y = y_no_normal)modelo_no_normal <-lm(y ~ x, data = datos_no_normal)# 2. Crear datos para los gráficosresiduos_no_normal <-residuals(modelo_no_normal)# 3. Gráfico Q-Q con ggplot2datos_qq_mal <-data.frame(residuos = residuos_no_normal)p1_mal <-ggplot(datos_qq_mal, aes(sample = residuos)) +geom_qq(color ="#D55E00", alpha =0.7) +geom_qq_line(color ="red", linetype ="dashed") +labs(title ="Normal Q-Q Plot (Violación)",x ="Cuantiles Teóricos",y ="Cuantiles de la Muestra" ) +theme_classic(base_size =10)# 4. Histograma con ggplot2datos_hist_mal <-data.frame(residuos = residuos_no_normal)p2_mal <-ggplot(datos_hist_mal, aes(x = residuos)) +geom_histogram(aes(y =after_stat(density)), bins =15, fill ="lightcoral", color ="black", alpha =0.7) +stat_function(fun = dnorm, args =list(mean =mean(residuos_no_normal), sd =sd(residuos_no_normal)),color ="blue", linewidth =1) +labs(title ="Histograma de Residuos (Violación)",x ="Residuos",y ="Densidad" ) +theme_classic(base_size =10)# 5. Mostrar ambos gráficos lado a ladogrid.arrange(p1_mal, p2_mal, ncol =2)# Prueba de Shapiro-Wilkshapiro_resultado <-shapiro.test(residuals(modelo_no_normal))
Figura 2.8: Violación del supuesto de normalidad. Izquierda: Q-Q Plot con clara desviación. Derecha: Histograma asimétricamente distribuido.
La violación es evidente. En el gráfico Q-Q, los puntos se desvían sistemáticamente de la línea diagonal, especialmente en los extremos, formando una curva característica de distribuciones asimétricas. El histograma muestra una clara asimetría hacia la derecha que no se ajusta a la curva normal teórica (línea azul). La prueba de Shapiro-Wilk arroja un p-valor muy pequeño (1.78e-10), rechazando fuertemente la hipótesis nula de normalidad.
2.6.4 Independencia de los residuos
Este supuesto afirma que el error de una observación no está correlacionado con el de ninguna otra: \(Cov(\varepsilon_i, \varepsilon_j) = 0\) para \(i \neq j\). La violación, conocida como autocorrelación, es común en datos de series temporales.
Métodos de diagnóstico:
Diagnóstico visual: Gráfico de residuos vs orden de observación. No debe mostrar patrones temporales o secuenciales.
Test de Durbin-Watson: Test clásico para autocorrelación de primer orden.
Interpretación: Valores cerca de 2 → no autocorrelación; cerca de 0 → autocorrelación positiva; cerca de 4 → autocorrelación negativa
Test de Breusch-Godfrey (LM): Generalización del Durbin-Watson para órdenes superiores y regresores retardados.
H₀: No hay autocorrelación serial hasta el orden especificado
H₁: Hay autocorrelación serial
Ventaja: Más general y potente que Durbin-Watson
El estadístico de Durbin-Watson varía entre 0 y 4. Un valor cercano a 2 sugiere no autocorrelación. Valores cercanos a 0 indican autocorrelación positiva, y cercanos a 4, autocorrelación negativa.
TipEjemplo de independencia válida
Para nuestro modelo_estudio, evaluamos la independencia mediante el gráfico de residuos vs orden y la prueba de Durbin-Watson.
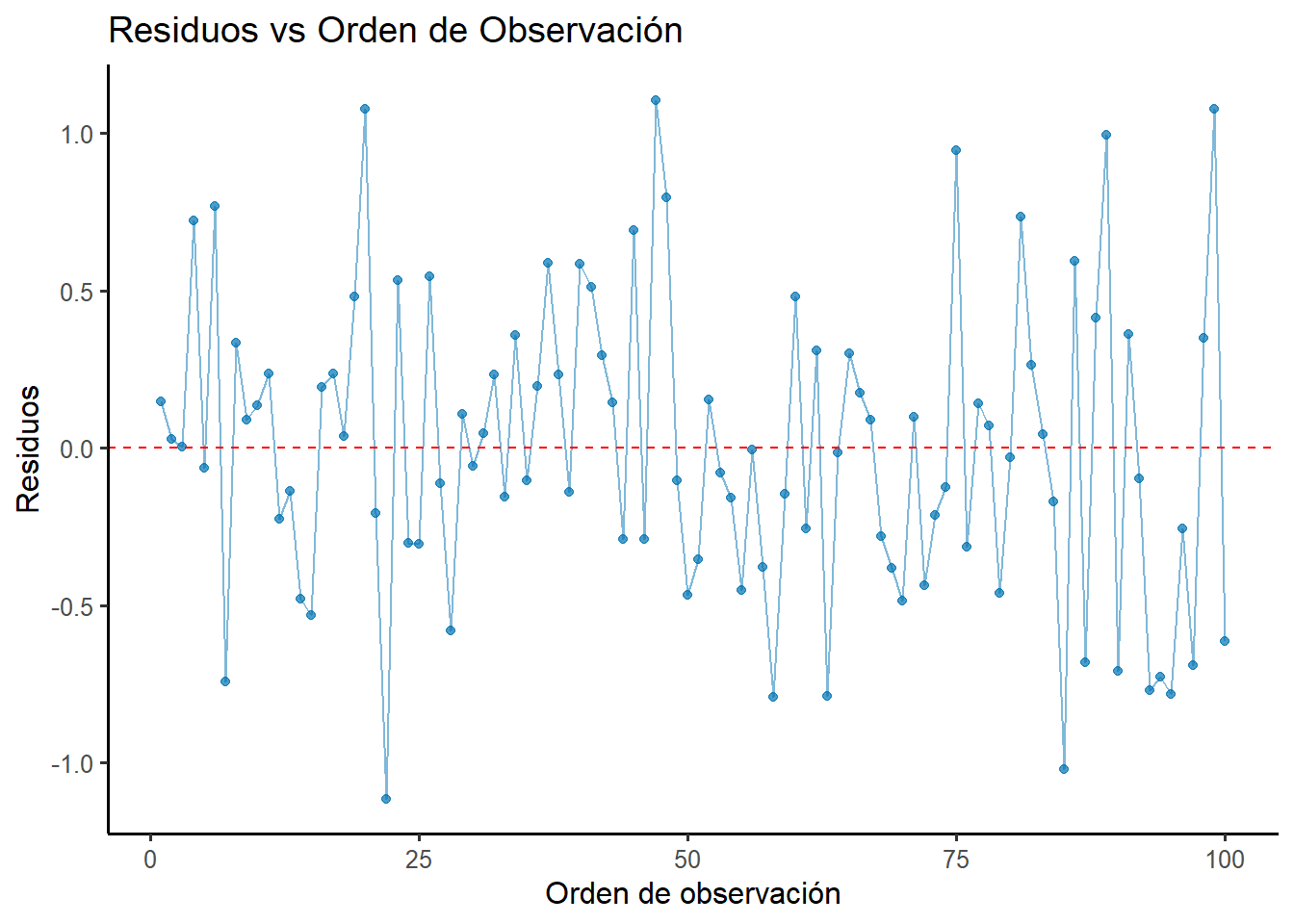
# Gráfico de residuos vs orden de observación con ggplot2datos_orden <-data.frame(orden =1:length(residuals(modelo_estudio)),residuos =residuals(modelo_estudio))ggplot(datos_orden, aes(x = orden, y = residuos)) +geom_point(color ="#0072B2", alpha =0.7) +geom_line(color ="#0072B2", alpha =0.5) +geom_hline(yintercept =0, color ="red", linetype ="dashed") +labs(title ="Residuos vs Orden de Observación",x ="Orden de observación",y ="Residuos" ) +theme_classic(base_size =12)# Prueba de Durbin-WatsonsuppressPackageStartupMessages(library(lmtest))dw_resultado_valido <-dwtest(modelo_estudio)print(dw_resultado_valido)
Durbin-Watson test
data: modelo_estudio
DW = 2.0565, p-value = 0.6104
alternative hypothesis: true autocorrelation is greater than 0
# Prueba de Breusch-Godfrey (más general)bg_resultado <-bgtest(modelo_estudio, order =2)print(bg_resultado)
Breusch-Godfrey test for serial correlation of order up to 2
data: modelo_estudio
LM test = 0.14002, df = 2, p-value = 0.9324
Figura 2.9: Diagnóstico de independencia del modelo de estudio. Los residuos no muestran patrones temporales.
El diagnóstico es satisfactorio. El gráfico de residuos vs orden no muestra ningún patrón sistemático o tendencia temporal. Ambas pruebas estadísticas confirman la independencia:
Durbin-Watson: DW =2.056, p-valor = 0.6104 → No hay autocorrelación de orden 1
Breusch-Godfrey: LM =0.14, p-valor = 0.9324 → No hay autocorrelación de orden 2 fluctúan aleatoriamente alrededor del cero.
La prueba de Durbin-Watson arroja un estadístico de 2.056 (cercano a 2) y un p-valor de 0.61, confirmando que no hay evidencia de autocorrelación. El supuesto de independencia se cumple.
TipContraejemplo: Violación del supuesto de independencia
Simularemos datos con autocorrelación positiva, donde cada residuo está correlacionado con el anterior, violando el supuesto de independencia.
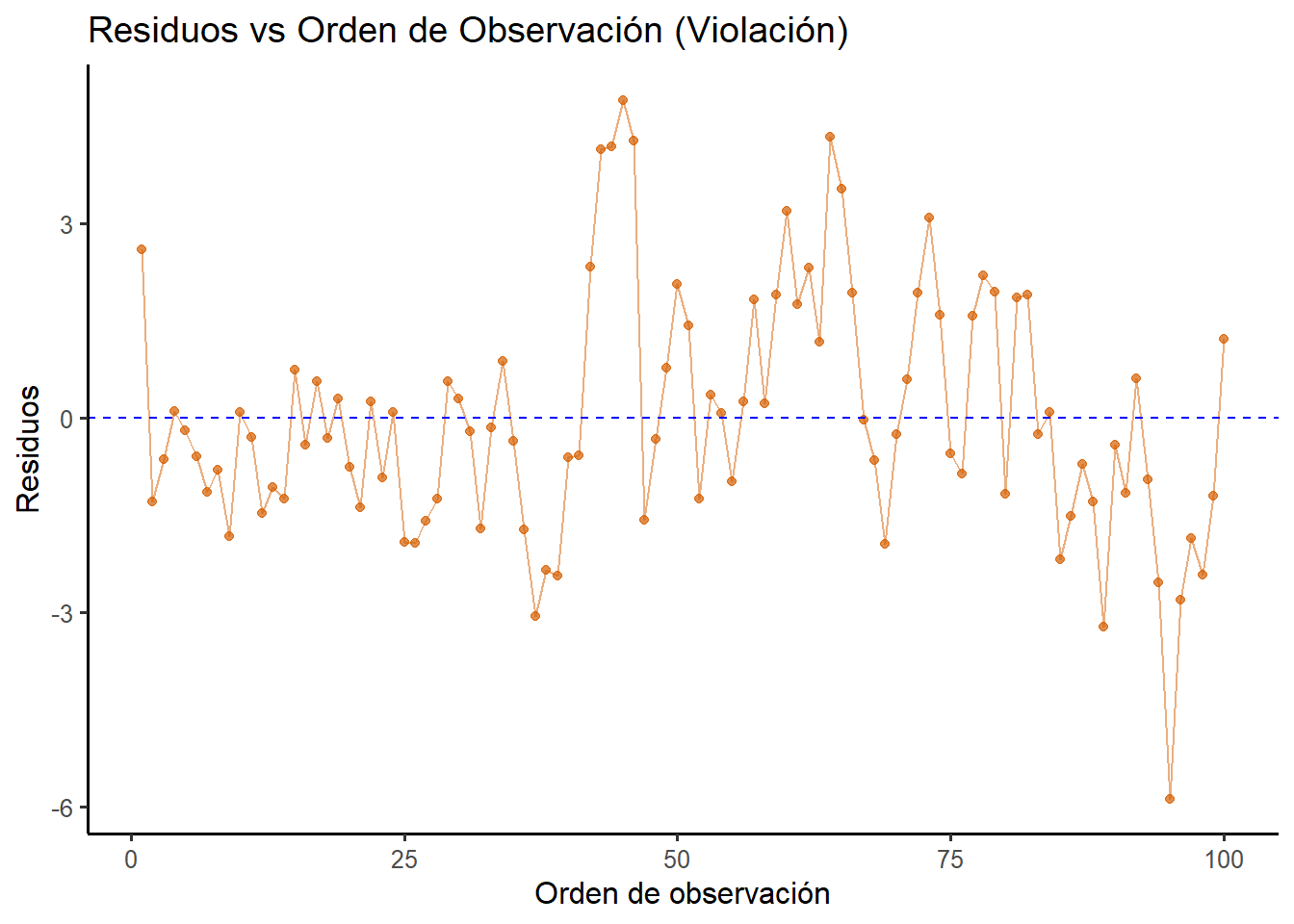
# 1. Simulación de datos con autocorrelaciónset.seed(789)n <-100x_autocorr <-1:n# Generamos errores autocorrelacionados (AR1 con phi = 0.7)errores_autocorr <-numeric(n)errores_autocorr[1] <-rnorm(1)for(i in2:n) { errores_autocorr[i] <-0.7* errores_autocorr[i-1] +rnorm(1, sd =0.5)}y_autocorr <-10+1.5* x_autocorr + errores_autocorr *3datos_autocorr <-data.frame(x = x_autocorr, y = y_autocorr)modelo_autocorr <-lm(y ~ x, data = datos_autocorr)# 2. Gráfico de residuos vs orden con ggplot2datos_orden_autocorr <-data.frame(orden =1:length(residuals(modelo_autocorr)),residuos =residuals(modelo_autocorr))ggplot(datos_orden_autocorr, aes(x = orden, y = residuos)) +geom_point(color ="#D55E00", alpha =0.7) +geom_line(color ="#D55E00", alpha =0.5) +geom_hline(yintercept =0, color ="blue", linetype ="dashed") +labs(title ="Residuos vs Orden de Observación (Violación)",x ="Orden de observación",y ="Residuos" ) +theme_classic(base_size =12)# 3. Prueba de Durbin-Watsondw_resultado <-dwtest(modelo_autocorr)
Figura 2.10: Violación del supuesto de independencia. Los residuos muestran un patrón de autocorrelación positiva.
La violación es clara. El gráfico de residuos vs orden muestra un patrón ondulante característico: los residuos tienden a mantenerse del mismo signo durante varias observaciones consecutivas (rachas de valores positivos seguidas de rachas de valores negativos). Esto indica autocorrelación positiva. La prueba de Durbin-Watson confirma esto con un estadístico muy por debajo de 2 (DW = 0.74) y un p-valor muy pequeño (5.01e-11), rechazando fuertemente la hipótesis nula de independencia.
2.6.5 Media nula de los residuos
Un requisito fundamental del modelo es que la media de los residuos debe ser exactamente cero: \(E[e_i] = 0\). Esta propiedad se deriva matemáticamente del método de mínimos cuadrados y su verificación sirve como una comprobación de que nuestros cálculos son correctos.
2.6.6 Identificación de observaciones influyentes y atípicas
Algunos puntos pueden tener una influencia desproporcionada en el modelo. Es crucial identificarlos usando diferentes métricas que evalúan aspectos complementarios de la influencia (Kutner et al. 2005; Fox y Weisberg 2018). Las métricas desarrolladas por Cook, Belsley, Kuh y Welsch proporcionan herramientas robustas para este diagnóstico.
NotaFundamento teórico: de los residuos simples a los estudentizados
Antes de analizar las métricas de influencia, debemos entender por qué no todos los residuos simples (\(e_i = y_i - \hat{y}_i\)) son comparables entre sí. El problema fundamental es que no tienen la misma varianza, incluso bajo homocedasticidad.
La varianza teórica del residuo \(e_i\) depende del apalancamiento (leverage) de la observación: \[
\text{Var}(e_i) = \sigma^2(1 - h_{ii})
\]
donde el apalancamiento \(h_{ii}\) se define como: \[
h_{ii} = \frac{1}{n} + \frac{(x_i - \bar{x})^2}{\sum_{j=1}^{n}(x_j - \bar{x})^2}
\]
Las observaciones con valores de \(X\) más alejados de la media tendrán mayor apalancamiento y, paradójicamente, residuos con menor varianza. Por esto, un residuo pequeño en una observación de alto leverage puede ser más preocupante que un residuo grande en el centro de los datos.
Los residuos estandarizados solucionan parcialmente este problema: \[
r_i^* = \frac{e_i}{\sqrt{\text{MSE}(1 - h_{ii})}}
\]
Pero los residuos estudentizados van un paso más allá, eliminando el sesgo de autoinfluencia: \[
r_i = \frac{e_i}{\sqrt{\text{MSE}_{(-i)}(1 - h_{ii})}}
\]
donde \(\text{MSE}_{(-i)}\) excluye la observación \(i\) del ajuste. Esto evita que un outlier “contamine” su propia evaluación y proporciona una distribución teórica exacta (t de Student con \(n-k-2\) grados de libertad).
¿Por qué son superiores los residuos estudentizados? Por tres razones clave: (1) eliminan el sesgo de autoinfluencia al excluir cada observación de su propia evaluación, (2) evitan la contaminación que un outlier produce en la MSE global, y (3) siguen una distribución conocida (t de Student) que permite umbrales estadísticamente precisos. En la práctica:\(|r_i| > 2\) indica posibles outliers (≈5% en normalidad) y \(|r_i| > 3\) outliers muy probables (<1%).
Las métricas fundamentales de influencia para identificar observaciones problemáticas son:
Apalancamiento (Leverage,\(h_{ii}\)): Mide cuán atípico es el valor de la variable predictora \(X_i\) de una observación. Un apalancamiento alto significa que el punto tiene el potencial de ser muy influyente. En regresión simple, se calcula como: \[ h_{ii} = \frac{1}{n} + \frac{(x_i - \bar{x})^2}{\sum_{j=1}^{n}(x_j - \bar{x})^2} \] Una regla común es considerar un apalancamiento alto si \(h_{ii} > \frac{2(k+1)}{n}\), donde \(k\) es el número de predictores (1 en regresión simple).
Distancia de Cook (\(D_i\)): Mide la influencia global de una observación, combinando su apalancamiento y su residuo. Representa cuánto cambian los coeficientes del modelo si la i-ésima observación es eliminada. \[ D_i = \frac{r_i^2}{k+1} \cdot \frac{h_{ii}}{1-h_{ii}} \] Se considera que un punto es influyente si su distancia de Cook es grande, por ejemplo, si \(D_i > 1\) o \(D_i > 4/(n-k-1)\).
DFFITS: Mide cuánto cambia la predicción \(\hat{y}_i\) cuando se elimina la i-ésima observación. Es una medida estandarizada que combina el residuo estudentizado y el apalancamiento. \[ \text{DFFITS}_i = r_i \sqrt{\frac{h_{ii}}{1-h_{ii}}} \] Un punto se considera influyente si \(|\text{DFFITS}_i| > 2\sqrt{(k+1)/n}\), donde \(k\) es el número de predictores.
TipEjemplo: Cálculo y análisis de DFFITS
DFFITS es especialmente útil para evaluar cómo cada observación afecta a su propia predicción. Analicemos esta medida con nuestro modelo_estudio.
# Calcular DFFITS y sus componentesdffits_vals <-dffits(modelo_estudio)residuos_stud <-rstudent(modelo_estudio) # Residuos estudentizadosleverage_vals <-hatvalues(modelo_estudio)# Crear dataframe para análisisdatos_dffits <-data.frame(observacion =1:length(dffits_vals),dffits = dffits_vals,residuo_stud = residuos_stud,leverage = leverage_vals)# Umbral de DFFITSn <-nrow(datos)k <-1# número de predictoresdffits_threshold <-2*sqrt((k +1) / n)# Gráfico de DFFITSggplot(datos_dffits, aes(x = observacion, y = dffits)) +geom_point(color ="#0072B2", alpha =0.7) +geom_hline(yintercept =0, color ="gray", linetype ="dashed") +geom_hline(yintercept =c(-dffits_threshold, dffits_threshold), color ="red", linetype ="dashed", alpha =0.7) +labs(title ="DFFITS por Observación",x ="Número de Observación",y ="DFFITS",caption =paste("Líneas rojas: umbrales ±", round(dffits_threshold, 3)) ) +theme_classic(base_size =12)# Análisis cuantitativoinfluential_dffits <-which(abs(dffits_vals) > dffits_threshold)top_indices <-order(abs(dffits_vals), decreasing =TRUE)[1:5]
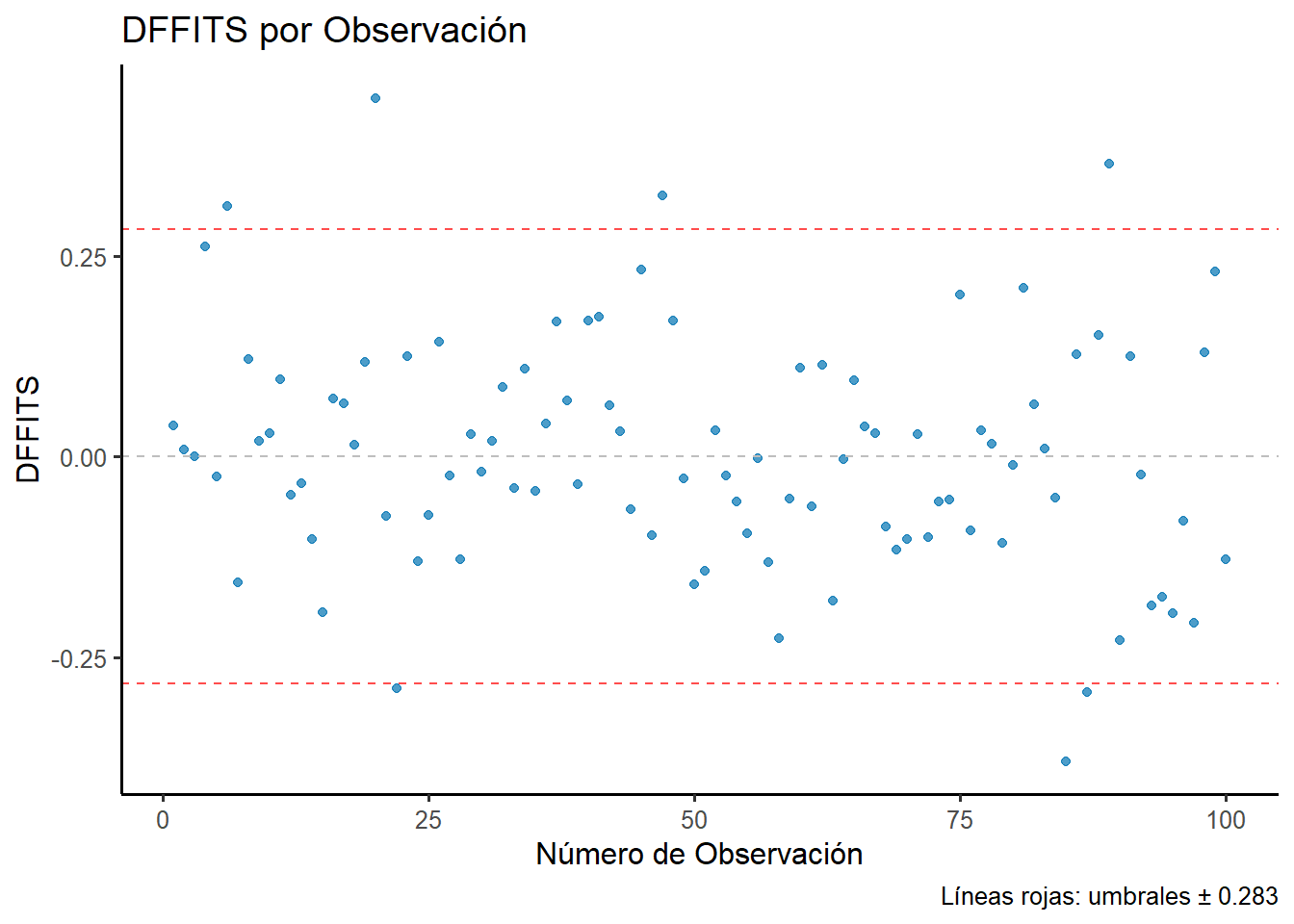
Figura 2.11: Análisis de DFFITS para identificar observaciones que afectan significativamente a sus propias predicciones.
Análisis de resultados:
El umbral de influencia para DFFITS es 0.283. En nuestro modelo, 7 observaciones superan este umbral: las observaciones 6, 20, 22, 47, 85, 87, 89, lo que las clasifica como influyentes según este criterio.
Las cinco observaciones con mayor |DFFITS| son las observaciones 20, 85, 89, 47, 6, con valores de 0.446, -0.38, 0.364, 0.325, 0.312 respectivamente. Lo más notable es que todas estas cinco observaciones (20, 85, 89, 47, 6) superan el umbral de DFFITS, confirmando su carácter influyente.
Interpretación clave: La observación 20 es el caso más destacado: tiene un DFFITS de 0.446, superando el umbral de 0.283. Esta combinación de residuo y apalancamiento resulta en un DFFITS significativo que indica cambios sustanciales en su predicción.
Conclusión práctica: Tenemos 7 observaciones influyentes según DFFITS (6, 20, 22, 47, 85, 87, 89) que merecen investigación adicional. Estas observaciones cambian significativamente sus propias predicciones cuando son eliminadas del modelo, sugiriendo que podrían representar casos especiales o errores de medición que deberían ser examinados más detalladamente.
El gráfico Residuals vs. Leverage es la herramienta visual más importante para el diagnóstico de influencia, ya que combina en un solo gráfico el apalancamiento (eje X) y los residuos estudentizados (eje Y), permitiendo identificar simultáneamente observaciones con alto leverage y outliers. Además, incluye curvas que delimitan regiones de alta Distancia de Cook, facilitando la identificación visual de los puntos más problemáticos.
TipEjemplo: Gráfico Residuals vs. Leverage
Vamos a analizar el gráfico más importante para el diagnóstico de influencia usando nuestro modelo_estudio.
# Crear datos para el gráfico Residuals vs. Leverageleverage_vals <-hatvalues(modelo_estudio)residuos_stud <-rstudent(modelo_estudio) # Residuos estudentizadoscook_dist <-cooks.distance(modelo_estudio)datos_leverage <-data.frame(leverage = leverage_vals,residuos_stud = residuos_stud,cook = cook_dist,observacion =1:length(leverage_vals))# Calcular umbralesn <-nrow(datos)k <-1leverage_threshold <-2* (k +1) / ncook_threshold <-4/ (n - k -1)# Función para crear curvas de Cookcook_curve <-function(leverage, cook_value, k) {sqrt(cook_value * (k +1) * (1- leverage) / leverage)}# Crear curvas de Cook para diferentes valoreslev_seq <-seq(0.001, max(leverage_vals) *1.1, length.out =100)cook_05 <-data.frame(leverage = lev_seq,pos =cook_curve(lev_seq, 0.5, k),neg =-cook_curve(lev_seq, 0.5, k))cook_1 <-data.frame(leverage = lev_seq,pos =cook_curve(lev_seq, 1, k),neg =-cook_curve(lev_seq, 1, k))# Gráfico Residuals vs. Leverage con ggplot2ggplot(datos_leverage, aes(x = leverage, y = residuos_stud)) +# Curvas de Cookgeom_line(data = cook_05, aes(x = leverage, y = pos), color ="red", linetype ="dashed", alpha =0.6, inherit.aes =FALSE) +geom_line(data = cook_05, aes(x = leverage, y = neg), color ="red", linetype ="dashed", alpha =0.6, inherit.aes =FALSE) +geom_line(data = cook_1, aes(x = leverage, y = pos), color ="red", linetype ="solid", alpha =0.8, inherit.aes =FALSE) +geom_line(data = cook_1, aes(x = leverage, y = neg), color ="red", linetype ="solid", alpha =0.8, inherit.aes =FALSE) +# Puntos de datosgeom_point(color ="#0072B2", alpha =0.7, size =2) +# Líneas de referenciageom_hline(yintercept =0, color ="gray", linetype ="dashed") +geom_hline(yintercept =c(-2, 2), color ="orange", linetype ="dotted", alpha =0.7) +geom_vline(xintercept = leverage_threshold, color ="purple", linetype ="dotted", alpha =0.7) +# Etiquetaslabs(title ="Residuals vs. Leverage",x ="Leverage",y ="Residuos Estudentizados",caption ="Curvas rojas: Cook 0.5 (discontinua) y 1.0 (continua) | Líneas naranjas: ±2 | Línea morada: umbral leverage" ) +theme_classic(base_size =12)# Identificar observaciones problemáticashigh_leverage <-which(leverage_vals > leverage_threshold)outliers_stud <-which(abs(residuos_stud) >2)high_cook <-which(cook_dist > cook_threshold)
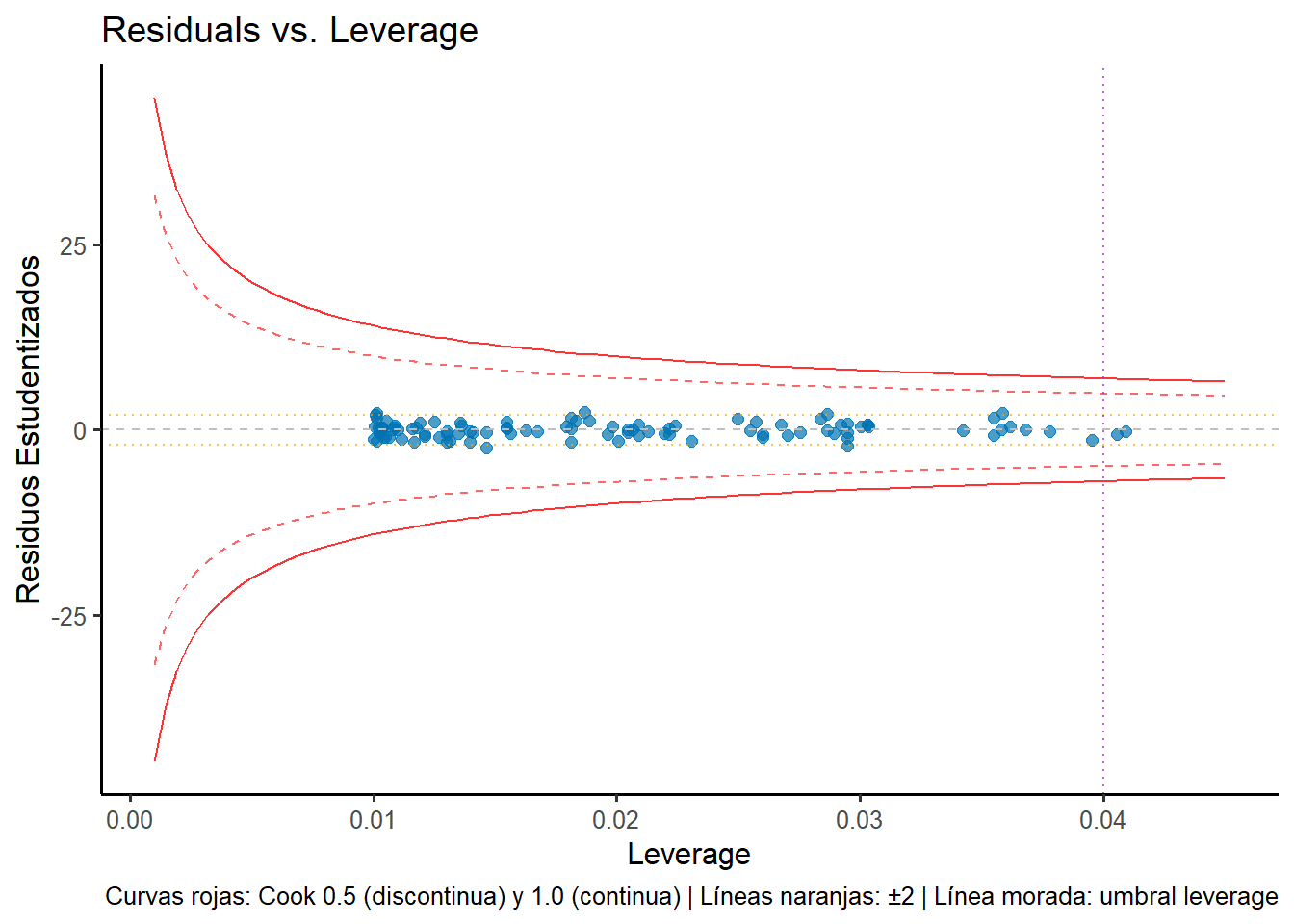
Figura 2.12: Gráfico Residuals vs. Leverage para identificar observaciones influyentes.
Análisis del gráfico:
El gráfico revela varios puntos importantes. Tenemos 6 outliers (residuos estudentizados > 2): las observaciones 20, 22, 47, 85, 89, 99. Además, 2 observaciones superan el umbral de leverage (> 0.04): las observaciones 24, 74.
Interpretación por regiones:
Zona derecha (alto leverage): Las observaciones 24, 74 superan el umbral de leverage, lo que significa que tienen valores de X atípicos y alto potencial influyente
Zona izquierda superior/inferior: Los 6 outliers (20, 22, 47, 85, 89, 99) están distribuidos aquí, con leverage bajo-moderado pero residuos grandes
Esquinas críticas: Afortunadamente vacías (alto leverage + outlier sería muy problemático)
Distancia de Cook: Las curvas rojas muestran que aunque ningún punto supera Cook = 1.0 (línea continua), varios puntos se acercan a la curva de Cook = 0.5 (línea discontinua), indicando influencia moderada. Las observaciones con alto leverage están en esta zona de influencia moderada.
Conclusión práctica: El modelo presenta una situación favorable: aunque tenemos outliers (observaciones 20, 22, 47, 85, 89, 99) que son atípicos en Y, y observaciones de alto leverage (observaciones 24, 74) que son atípicos en X, crucialmente no hay solapamiento entre ambos grupos. Esto significa que no tenemos la situación más problemática (alto leverage + outlier). Aun así, ambos grupos merecen investigación.
2.6.6.1 Interpretación práctica de las medidas de influencia
Cada medida nos proporciona información complementaria sobre diferentes aspectos de la influencia:
Leverage (Apalancamiento): Identifica observaciones con valores “raros” en las variables predictoras. Alto leverage no es necesariamente problemático, pero indica potencial para ser influyente.
Distancia de Cook: Es la medida más general de influencia. Valores altos indican que eliminar esa observación cambiaría substancialmente los coeficientes del modelo.
DFFITS: Se enfoca específicamente en cómo cambia la predicción de cada punto cuando se elimina esa observación. Es especialmente útil para evaluar el impacto en las predicciones.
En la práctica, una observación es especialmente preocupante si es problemática según múltiples criterios a la vez.
TipDiagnóstico completo del modelo de estudio
A continuación, realizamos todas las verificaciones de diagnóstico para nuestro modelo_estudio:
# Preparar todos los datos necesarios para los gráficosresiduos_completo <-residuals(modelo_estudio)valores_ajustados_completo <-fitted(modelo_estudio)residuos_std <-rstandard(modelo_estudio)leverage_vals <-hatvalues(modelo_estudio)# 1. Gráfico Residuos vs. Valores Ajustadosp1_completo <-ggplot(data.frame(x = valores_ajustados_completo, y = residuos_completo), aes(x = x, y = y)) +geom_point(color ="#0072B2", alpha =0.7) +geom_hline(yintercept =0, color ="red", linetype ="dashed") +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Residuos vs. Valores Ajustados", x ="Valores Ajustados", y ="Residuos") +theme_classic(base_size =10)# 2. Gráfico Q-Q Normaldatos_qq_completo <-data.frame(residuos = residuos_std)p2_completo <-ggplot(datos_qq_completo, aes(sample = residuos)) +geom_qq(color ="#0072B2", alpha =0.7) +geom_qq_line(color ="red", linetype ="dashed") +labs(title ="Normal Q-Q Plot", x ="Cuantiles Teóricos", y ="Cuantiles de la Muestra") +theme_classic(base_size =10)# 3. Gráfico Scale-Locationp3_completo <-ggplot(data.frame(x = valores_ajustados_completo, y =sqrt(abs(residuos_std))), aes(x = x, y = y)) +geom_point(color ="#0072B2", alpha =0.7) +geom_smooth(method ="loess", se =FALSE, color ="red", linewidth =0.8, formula = y ~ x) +labs(title ="Scale-Location", x ="Valores Ajustados", y =expression(sqrt("|Residuos Estandarizados|"))) +theme_classic(base_size =10)# 4. Gráfico Residuos vs. Leverage (con curvas de Cook)p4_completo <-ggplot(datos_leverage, aes(x = leverage, y = residuos_stud)) +# Curvas de Cookgeom_line(data = cook_05, aes(x = leverage, y = pos), color ="red", linetype ="dashed", alpha =0.6, inherit.aes =FALSE) +geom_line(data = cook_05, aes(x = leverage, y = neg), color ="red", linetype ="dashed", alpha =0.6, inherit.aes =FALSE) +geom_line(data = cook_1, aes(x = leverage, y = pos), color ="red", linetype ="solid", alpha =0.8, inherit.aes =FALSE) +geom_line(data = cook_1, aes(x = leverage, y = neg), color ="red", linetype ="solid", alpha =0.8, inherit.aes =FALSE) +# Puntos de datosgeom_point(color ="#0072B2", alpha =0.7, size =1.5) +# Líneas de referenciageom_hline(yintercept =0, color ="gray", linetype ="dashed") +geom_hline(yintercept =c(-2, 2), color ="orange", linetype ="dotted", alpha =0.7) +geom_vline(xintercept = leverage_threshold, color ="purple", linetype ="dotted", alpha =0.7) +labs(title ="Residuals vs. Leverage", x ="Leverage", y ="Residuos Estudentizados") +theme_classic(base_size =10)# 5. Histograma de residuosp5_completo <-ggplot(data.frame(residuos = residuos_completo), aes(x = residuos)) +geom_histogram(aes(y =after_stat(density)), bins =15, fill ="lightblue", color ="black", alpha =0.7) +stat_function(fun = dnorm, args =list(mean =mean(residuos_completo), sd =sd(residuos_completo)),color ="red", linewidth =1) +labs(title ="Histograma de Residuos", x ="Residuos", y ="Densidad") +theme_classic(base_size =10)# 6. Residuos vs. Ordenp6_completo <-ggplot(data.frame(orden =1:length(residuos_completo), residuos = residuos_completo), aes(x = orden, y = residuos)) +geom_point(color ="#0072B2", alpha =0.7) +geom_line(color ="#0072B2", alpha =0.5) +geom_hline(yintercept =0, color ="red", linetype ="dashed") +labs(title ="Residuos vs. Orden", x ="Orden de observación", y ="Residuos") +theme_classic(base_size =10)# Mostrar todos los gráficos en una rejilla 2x3library(gridExtra)grid.arrange(p1_completo, p2_completo, p3_completo, p4_completo, p5_completo, p6_completo, ncol =3)
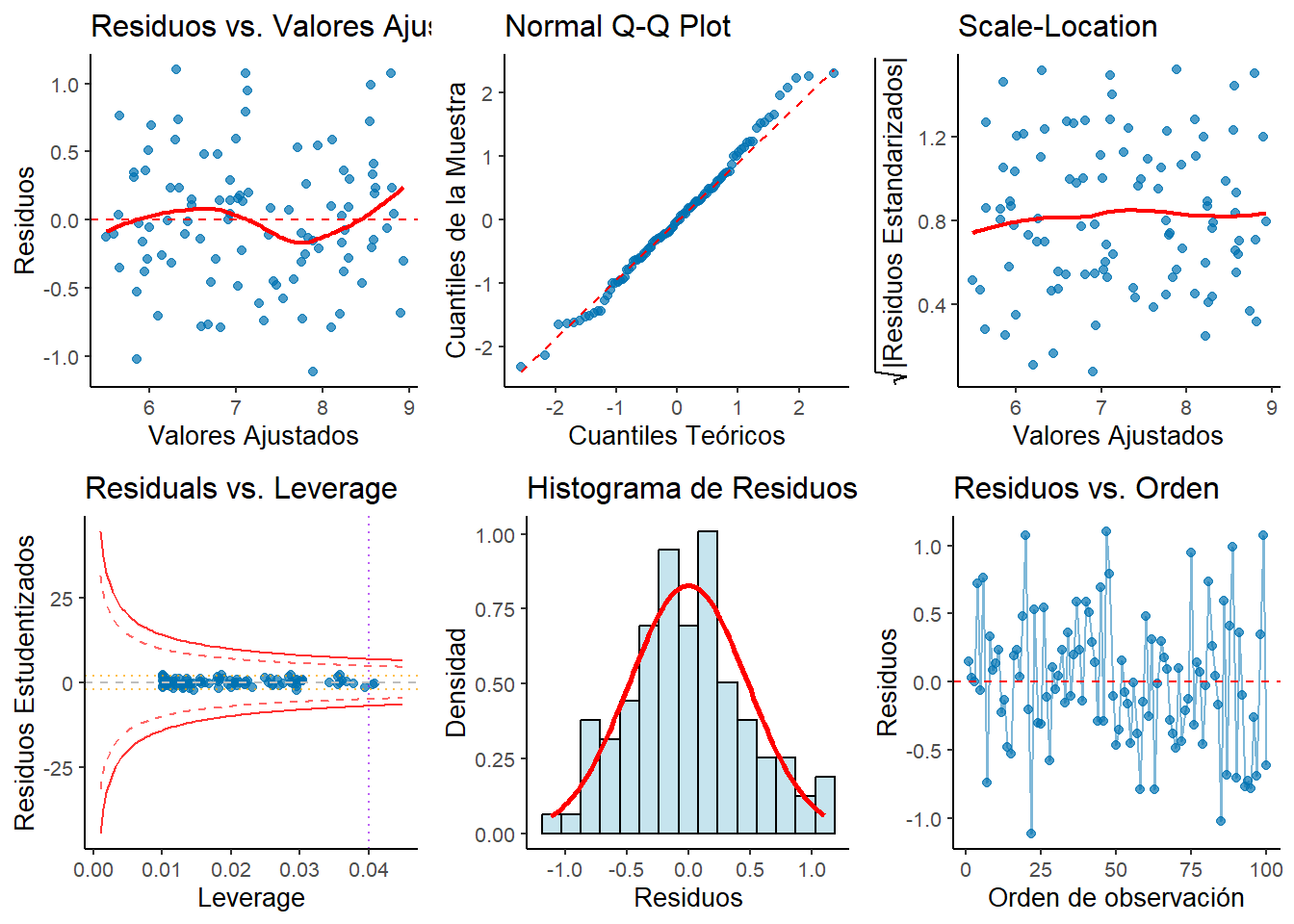
Figura 2.13: Gráficos de diagnóstico completo del modelo de regresión.
Conclusión del diagnóstico:
Nuestro modelo de estudio pasa exitosamente todas las verificaciones:
✅ Linealidad: Los gráficos de residuos vs valores ajustados no muestran patrones sistemáticos, confirmando que la relación lineal es apropiada.
✅ Homocedasticidad: La prueba de Breusch-Pagan arroja un p-valor de 0.8886, que es mayor a 0.05, por lo que no hay evidencia de heterocedasticidad. La varianza de los errores es constante.
✅ Normalidad: La prueba de Shapiro-Wilk presenta un p-valor de 0.671, superior a 0.05, confirmando que los residuos siguen una distribución normal. Esto se corrobora visualmente en el Q-Q plot.
✅ Independencia: El estadístico de Durbin-Watson es 2.056 con un p-valor de 0.61, indicando ausencia de autocorrelación en los residuos.
✅ Media nula: La media de los residuos es 0, prácticamente cero como se esperaría en un modelo bien especificado.
Se identificaron las siguientes observaciones que requieren atención:
• Alto apalancamiento (> 0.04 ): 24, 74
• Influyentes según Cook (> 0.041 ): 6, 20, 47, 85, 87, 89
• Influyentes según DFFITS (> 0.283 ): 6, 20, 22, 47, 85, 87, 89
• Posibles outliers (|residuo std| > 2): 20, 22, 47, 85, 89, 99
Estas observaciones deberían ser investigadas más detalladamente antes de proceder con las inferencias finales.
Esto confirma que nuestras inferencias estadísticas (p-valores, intervalos de confianza) son válidas y confiables (James et al. 2021; Harrell 2015).
Draper, NR. 1998. Applied regression analysis. McGraw-Hill. Inc.
Fox, John, y Sanford Weisberg. 2018. An R companion to applied regression. Sage publications.
Galton, Francis. 1886. «Regression towards mediocrity in hereditary stature». The Journal of the Anthropological Institute of Great Britain and Ireland 15: 246-63.
Harrell, Frank E., Jr. 2015. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. Second. Springer.
James, Gareth, Daniela Witten, Trevor Hastie, y Robert Tibshirani. 2021. An Introduction to Statistical Learning with Applications in R. Second. Springer.
Kutner, Michael H, Christopher J Nachtsheim, John Neter, y William Li. 2005. Applied linear statistical models. McGraw-hill.
Weisberg, S. 2005. «Applied linear regression». Wiley.