Hasta ahora hemos estuadiado la regresión lineal como una herramienta poderosa para modelar la relación entre una variable dependiente continua y un conjunto de variables independientes. Sin embargo, en muchos contextos del mundo real, las suposiciones de la regresión lineal tradicional no son adecuadas. ¿Qué sucede si la variable dependiente es binaria, como en un diagnóstico médico (enfermo/sano)? ¿O si estás modelando el número de accidentes en una intersección o la cantidad de compras realizadas por un cliente?
Para abordar estos desafíos, se utilizan los llamados Modelos Lineales Generalizados (GLM). Esta clase de modelos amplía la regresión lineal al permitir que la variable dependiente tenga distribuciones diferentes a la normal, como la binomial o la de Poisson. Además, los GLM utilizan funciones de enlace que transforman la relación entre la variable dependiente y los predictores, permitiendo una mayor flexibilidad en el modelado.
Algunos de los modelos más comunes dentro de los GLM son:
Regresión Logística: Ideal para variables dependientes binarias (sí/no, éxito/fracaso).
Regresión de Poisson: Utilizada para modelar datos de conteo (número de eventos).
Regresión Binomial Negativa: Una extensión de la regresión de Poisson para datos de conteo con sobredispersión.
Modelos de Gamma y Inverso Gaussiano: Utilizados para modelar variables continuas positivas y sesgadas, como tiempos de espera o costos.
En este tema, exploraremos cómo utilizar estos modelos para resolver problemas del mundo real, interpretar sus resultados y evaluar su ajuste.
6.1 Introducción a los GLM
6.1.1 ¿Qué son los modelos lineales generalizados?
Los Modelos Lineales Generalizados (GLM) son una extensión de los modelos de regresión lineal que permiten manejar una mayor variedad de tipos de datos y relaciones entre variables (Nelder y Wedderburn 1972). Mientras que la regresión lineal tradicional asume que la variable dependiente es continua y sigue una distribución normal, los GLM permiten trabajar con variables dependientes que:
Son binarias (como éxito/fracaso o sí/no).
Representan conteos de eventos (número de llamadas, accidentes, etc.).
Son continuas positivas y no siguen una distribución normal (como tiempos o costos).
Los GLM proporcionan una estructura flexible para modelar la relación entre una o más variables independientes y una variable dependiente que sigue alguna distribución de la familia exponencial (binomial, Poisson, gamma, entre otras).
6.1.2 Componentes de un modelo lineal generalizado
Un GLM se define por tres componentes clave:
Componente Aleatorio:
Este componente describe la distribución de la variable dependiente. En la regresión lineal, la variable dependiente sigue una distribución normal. En los GLM, puede seguir otras distribuciones de la familia exponencial, como:
Distribución Binomial: Para variables categóricas binarias (0/1, éxito/fracaso).
Distribución de Poisson: Para datos de conteo (número de eventos).
Distribución Gamma: Para variables continuas y positivas (como costos o tiempos).
Componente Sistemático:
Este componente describe cómo las variables independientes se combinan linealmente en el modelo. Se define como:
Donde \(\eta\) es el predictor lineal y \(\boldsymbol{\beta}\) representa los coeficientes del modelo.
Función de Enlace:
La función de enlace conecta el componente sistemático con la media de la variable dependiente. Mientras que en la regresión lineal la relación es directa (\(y = \eta\)), en los GLM se utiliza una función de enlace \(g(\mu)\) para transformar la media \(\mu\) y ajustar diferentes tipos de datos.
\[
g(\mu) = \eta
\]
Ejemplos de funciones de enlace:
Logística (Logit): Para la regresión logística, que modela la probabilidad de un evento. \[
g(\mu) = \log\left(\frac{\mu}{1 - \mu}\right)
\]
Logarítmica: Para la regresión de Poisson, que modela tasas de eventos. \[
g(\mu) = \log(\mu)
\]
Identidad: Para la regresión lineal estándar. \[
g(\mu) = \mu
\]
NotaAplicaciones
Los GLM se utilizan en una amplia variedad de disciplinas para resolver problemas del mundo real:
Regresión Logística (para variables binarias):
Medicina: Predicción de la presencia o ausencia de una enfermedad basada en factores de riesgo.
Marketing: Determinación de la probabilidad de que un cliente compre un producto.
Finanzas: Evaluación de la probabilidad de incumplimiento de pago de un préstamo.
Regresión de Poisson (para datos de conteo):
Transporte: Modelado del número de accidentes en una carretera en un período de tiempo.
Ecología: Conteo de especies en un área determinada.
Telecomunicaciones: Número de llamadas recibidas por un centro de atención.
Regresión Binomial Negativa (para conteos con sobredispersión):
Salud Pública: Modelado del número de visitas al médico o incidentes de una enfermedad en una población.
Seguros: Estimación de los costos de reclamos de seguros.
Ingeniería: Modelado de tiempos de falla en procesos industriales.
6.1.3 Diferencias clave entre la regresión lineal y los GLM
Característica
Regresión Lineal
Modelos Lineales Generalizados (GLM)
Distribución de la variable dependiente
Normal
Familia exponencial (binomial, Poisson, gamma, etc.)
Tipo de variable dependiente
Continua
Binaria, de conteo, continua positiva
Relación entre las variables
Lineal directa
Relación transformada mediante una función de enlace
Función de Enlace
Identidad (\(g(\mu) = \mu\))
Logit, logarítmica, inversa, etc.
Las ventajas principales de los GLM son:
Flexibilidad: Los GLM permiten modelar diferentes tipos de variables dependientes, lo que amplía significativamente el rango de problemas que se pueden abordar.
Interpretación Coherente: Aunque se utilizan funciones de enlace, los coeficientes de los GLM pueden interpretarse de manera similar a los modelos lineales, proporcionando información sobre el impacto de cada variable independiente.
Evaluación Estadística Robusta: Los GLM permiten la realización de pruebas de hipótesis, la construcción de intervalos de confianza y la evaluación de la bondad del ajuste mediante medidas ya conocidas como el AIC o el BIC.
Los Modelos Lineales Generalizados amplían el alcance de la regresión lineal clásica, proporcionando herramientas para modelar una amplia variedad de tipos de datos, desde variables binarias hasta datos de conteo y variables continuas no normales. A través del uso de funciones de enlace y distribuciones flexibles, los GLM permiten resolver problemas complejos del mundo real en campos tan diversos como la medicina, el marketing, la ingeniería y las ciencias sociales.
En las próximas secciones, exploraremos en detalle cómo aplicar estos modelos específicos, como la regresión logística y la regresión de Poisson, y cómo interpretar sus resultados en diferentes contextos.
6.2 Estimación de parámetros en GLM
La estimación de parámetros en los Modelos Lineales Generalizados representa un aspecto fundamental que diferencia estos modelos de la regresión lineal clásica. Mientras que en la regresión lineal utilizamos mínimos cuadrados ordinarios para obtener estimadores con propiedades óptimas, en los GLM necesitamos métodos más sofisticados debido a la naturaleza no normal de las distribuciones involucradas y las funciones de enlace no lineales.
La estimación en GLM se basa en el principio de máxima verosimilitud, que proporciona un marco teórico unificado para todos los modelos de la familia exponencial. Este enfoque no solo garantiza propiedades estadísticas deseables de los estimadores, sino que también permite el desarrollo de algoritmos computacionales eficientes para encontrar las soluciones.
En esta sección exploraremos los fundamentos teóricos de la estimación por máxima verosimilitud, el algoritmo iterativo IRLS (Iteratively Reweighted Least Squares) que implementan los software estadísticos, y los problemas prácticos que pueden surgir durante el proceso de estimación. Comprender estos aspectos es crucial para interpretar correctamente los resultados y diagnosticar posibles problemas en el ajuste de los modelos.
6.2.1 Método de máxima verosimilitud
A diferencia de la regresión lineal que utiliza el método de mínimos cuadrados, los GLM emplean el método de máxima verosimilitud para estimar los parámetros del modelo. Este cambio metodológico es necesario debido a que las distribuciones de la familia exponencial no siempre tienen una relación lineal directa con los predictores, y además porque la varianza de la variable respuesta depende de su media, violando el supuesto de homocedasticidad que requieren los mínimos cuadrados.
El principio de máxima verosimilitud consiste en encontrar los valores de los parámetros \(\boldsymbol{\beta}\) que hacen más probable observar los datos que tenemos. Para una muestra de \(n\) observaciones independientes \(y_1, y_2, \ldots, y_n\), la función de verosimilitud se define como la probabilidad conjunta de observar estos datos dado un conjunto de parámetros:
donde \(f(y_i; \theta_i, \phi)\) es la función de densidad (o masa) de probabilidad de la observación \(i\). En la práctica, es más conveniente trabajar con el logaritmo de esta función, conocida como log-verosimilitud:
La ventaja de usar el logaritmo es que convierte productos en sumas, simplificando considerablemente los cálculos matemáticos y numéricos.
La clave para entender los GLM radica en reconocer que todas las distribuciones que podemos usar (binomial, Poisson, gamma, etc.) pertenecen a la familia exponencial. Estas distribuciones pueden expresarse en una forma matemática unificada:
donde \(\theta\) es el parámetro natural o canónico que está relacionado directamente con la media de la distribución, \(\phi\) es el parámetro de dispersión que controla la variabilidad, y \(b(\theta)\), \(a(\phi)\) y \(c(y, \phi)\) son funciones específicas de cada distribución que determinan sus propiedades particulares.
Esta forma unificada tiene propiedades matemáticas muy convenientes que hacen que los GLM sean tanto elegantes teóricamente como computacionalmente eficientes. La esperanza de \(Y\) se obtiene como \(E(Y) = \mu = b'(\theta)\) (la derivada de \(b\) respecto a \(\theta\)), y la varianza como \(\text{Var}(Y) = a(\phi) b''(\theta) = a(\phi) V(\mu)\), donde \(V(\mu)\) es la función de varianza que caracteriza cómo la varianza depende de la media en cada tipo de distribución.
NotaLa Familia Exponencial: Un Vistazo General
La elegancia de los GLM reside en que muchas distribuciones aparentemente distintas comparten una estructura matemática común. Esto permite una teoría unificada. Aquí están los miembros más importantes:
Distribución
Uso Típico
Función de Varianza \(V(\mu)\)
Enlace Canónico \(g(\mu)\)
Normal
Datos continuos simétricos
\(1\)
Identidad: \(\mu\)
Binomial
Proporciones, datos binarios (éxito/fracaso)
\(\mu(1-\mu)\)
Logit: \(\log(\frac{\mu}{1-\mu})\)
Poisson
Conteos de eventos
\(\mu\)
Log: \(\log(\mu)\)
Gamma
Datos continuos positivos y asimétricos (tiempos, costos)
\(\mu^2\)
Inverso: \(1/\mu\)
Inversa Gaussiana
Tiempos hasta un evento, datos muy asimétricos
\(\mu^3\)
Inverso al cuadrado: \(1/\mu^2\)
La función de varianza \(V(\mu)\) es la “firma” de cada distribución, ya que define la relación teórica entre la media y la varianza de la respuesta. El enlace canónico es la función de enlace que surge de forma natural de la estructura matemática de la distribución, aunque en la práctica se pueden usar otros enlaces.
Esta relación entre media y varianza es fundamental para entender las diferencias entre los diversos GLM. En la regresión lineal clásica, la varianza es constante (\(V(\mu) = 1\)), pero en otros GLM la función de varianza toma formas específicas:
Distribución binomial: \(V(\mu) = \mu(1-\mu)\) - la varianza es máxima cuando \(\mu = 0.5\) y mínima en los extremos.
Distribución de Poisson: \(V(\mu) = \mu\) - la varianza aumenta linealmente con la media.
Distribución gamma: \(V(\mu) = \mu^2\) - la varianza aumenta cuadráticamente con la media.
Estas funciones de varianza no solo determinan la heterocedasticidad inherente de cada distribución, sino que también influyen directamente en los pesos del algoritmo IRLS y en la precisión de las estimaciones. Por ejemplo, en regresión logística, las observaciones con probabilidades cercanas a 0.5 tienen mayor varianza y, por tanto, menor peso en la estimación, mientras que en regresión de Poisson, las observaciones con conteos más altos contribuyen con mayor peso al ajuste del modelo.
6.2.1.1 Algoritmo de Newton-Raphson (IRLS)
Para encontrar los valores de \(\boldsymbol{\beta}\) que maximizan la log-verosimilitud, los GLM utilizan un algoritmo iterativo conocido como Iteratively Reweighted Least Squares (IRLS), que es una implementación especializada del método de Newton-Raphson. La necesidad de un algoritmo iterativo surge porque, a diferencia de la regresión lineal donde existe una solución analítica cerrada, en los GLM las ecuaciones de verosimilitud no tienen solución directa debido a la presencia de funciones no lineales.
El algoritmo IRLS se basa en la idea de que podemos aproximar la función de enlace y la varianza de la distribución en torno a un valor central (la media) y luego aplicar mínimos cuadrados de manera iterativa para ajustar los parámetros del modelo. Los pasos básicos del algoritmo son:
Inicialización: Establecer valores iniciales para los parámetros \(\boldsymbol{\beta}^{(0)}\).
Iteración \(t\):
Calcular el predictor lineal: \(\eta_i^{(t)} = \mathbf{x}_i^T \boldsymbol{\beta}^{(t)}\).
Calcular la media estimada: \(\mu_i^{(t)} = g^{-1}(\eta_i^{(t)})\).
Calcular los pesos: \(w_i^{(t)} = \frac{1}{\text{Var}(\mu_i^{(t)})} \left(\frac{d\mu_i}{d\eta_i}\right)^2\).
Convergencia: Repetir el proceso hasta que la diferencia entre iteraciones sucesivas sea menor que un umbral predefinido.
TipEjemplo: Convergencia del algoritmo IRLS
# Ejemplo de seguimiento de la convergencia en regresión logísticalibrary(MASS)data(Pima.tr)# Función para mostrar el proceso iterativomostrar_convergencia <-function() {# Ajustar modelo con seguimiento de iteraciones modelo <-glm(type ~ glu + bmi, data = Pima.tr, family = binomial,control =glm.control(trace =TRUE, maxit =10))cat("Número de iteraciones necesarias:", modelo$iter, "\n")cat("¿Convergió?", modelo$converged, "\n")cat("Log-likelihood final:", logLik(modelo), "\n")return(modelo)}# Ejecutar y mostrar convergenciamodelo_ejemplo <-mostrar_convergencia()
6.2.1.2 Propiedades de los estimadores de máxima verosimilitud
Los estimadores de máxima verosimilitud en GLM poseen propiedades estadísticas muy atractivas que los convierten en la elección preferida para la estimación de parámetros. Estas propiedades son asintóticas, lo que significa que se cumplen cuando el tamaño de la muestra tiende a infinito, pero en la práctica proporcionan una excelente aproximación para muestras moderadamente grandes.
1. Consistencia:\[\hat{\boldsymbol{\beta}} \xrightarrow{p} \boldsymbol{\beta} \text{ cuando } n \to \infty\]
La consistencia garantiza que a medida que aumentamos el tamaño de la muestra, nuestros estimadores se acercan cada vez más al valor verdadero de los parámetros. Esto significa que con suficientes datos, los estimadores de máxima verosimilitud convergerán al valor real de \(\boldsymbol{\beta}\), eliminando el sesgo de estimación. Esta propiedad es fundamental porque nos asegura que no estamos introduciendo errores sistemáticos en nuestras estimaciones.
La normalidad asintótica establece que la distribución de los estimadores, apropiadamente escalada, se aproxima a una distribución normal multivariada cuando el tamaño de la muestra es grande. Esta propiedad es crucial porque:
Permite construir intervalos de confianza para los parámetros usando la distribución normal
Facilita la realización de pruebas de hipótesis sobre los coeficientes
Proporciona la base teórica para los estadísticos de Wald utilizados en las pruebas de significancia
La matriz de covarianza asintótica \(\mathbf{I}^{-1}(\boldsymbol{\beta})\) nos permite calcular los errores estándar de nuestras estimaciones, que son esenciales para la inferencia estadística.
3. Eficiencia:
Los estimadores MV alcanzan la cota de Cramér-Rao, siendo asintóticamente eficientes. Esto significa que:
Entre todos los estimadores insesgados posibles, los de máxima verosimilitud tienen la menor varianza asintótica
No existe otro método de estimación que, bajo las mismas condiciones, produzca estimadores con menor incertidumbre
Utilizan la información disponible en los datos de manera óptima
En términos prácticos, esta eficiencia se traduce en intervalos de confianza más estrechos y pruebas de hipótesis más poderosas comparado con otros métodos de estimación.
6.2.1.3 Matriz de información y errores estándar
La implementación práctica de estas propiedades teóricas requiere el cálculo de la matriz de información, que cuantifica la cantidad de información que contienen los datos sobre los parámetros del modelo.
La matriz de información de Fisher se define teóricamente como:
Esta matriz representa las segundas derivadas de la log-verosimilitud evaluadas en nuestras estimaciones. Intuitivamente, mide qué tan “puntiaguda” es la función de verosimilitud alrededor del máximo: una función más puntiaguda indica mayor información y, por tanto, menor incertidumbre en la estimación.
Para los GLM, el algoritmo IRLS proporciona una aproximación computacionalmente eficiente:
donde \(\mathbf{W}\) es la matriz diagonal de pesos calculada en la última iteración del algoritmo. Esta aproximación es exacta para la distribución normal y muy buena para otras distribuciones de la familia exponencial.
Los errores estándar de los coeficientes individuales se obtienen como las raíces cuadradas de los elementos diagonales de la matriz de covarianza:
Intervalos de confianza:\(\hat{\beta}_j \pm z_{\alpha/2} \cdot \text{SE}(\hat{\beta}_j)\)
Estadísticos de prueba:\(z_j = \frac{\hat{\beta}_j}{\text{SE}(\hat{\beta}_j)}\)
Evaluación de la precisión de nuestras estimaciones
Es importante recordar que estos errores estándar son válidos bajo los supuestos del modelo GLM y que violaciones serias de estos supuestos (como sobredispersión en modelos de Poisson) pueden hacer que sean inadecuados.
6.3 Bondad de ajuste en GLMs
Los Modelos Lineales Generalizados requieren métodos específicos para evaluar la calidad del ajuste que van más allá de las métricas tradicionales de la regresión lineal. Mientras que en la regresión lineal clásica utilizamos el coeficiente de determinación (\(R^2\)) y la suma de cuadrados residuales como medidas principales de bondad de ajuste, en los GLMs estas métricas no son apropiadas debido a las diferentes distribuciones subyacentes y las funciones de enlace no lineales.
La evaluación de la bondad de ajuste en GLMs se basa fundamentalmente en conceptos de verosimilitud y deviance, que proporcionan una base teórica sólida para comparar modelos y evaluar su calidad de ajuste. Esta aproximacion basada en la verosimilitud es coherente con el método de estimación utilizado en estos modelos.
6.3.1 La deviance como medida de bondad de ajuste
La deviance (o desviación) es la medida principal de bondad de ajuste en los Modelos Lineales Generalizados. Conceptualmente, representa una generalización de la suma de cuadrados residuales de la regresión lineal para distribuciones no normales, pero su interpretación y cálculo son fundamentalmente diferentes.
La deviance se basa en el principio de máxima verosimilitud y mide qué tan bien el modelo propuesto se ajusta a los datos comparado con el mejor ajuste posible. Para entender este concepto, es importante distinguir entre dos tipos de modelos:
Modelo Saturado: Un modelo hipotético que tiene tantos parámetros como observaciones, por lo que puede predecir perfectamente cada valor observado. Este modelo representa el “ajuste perfecto” teórico.
Modelo Propuesto: El modelo que estamos evaluando, con un número limitado de parámetros basado en nuestras variables predictoras.
La deviance mide la diferencia en log-verosimilitud entre estos dos modelos:
\(\ell(y_i; y_i)\) = Log-verosimilitud del modelo saturado para la observación \(i\).
\(\ell(y_i; \hat{\mu}_i)\) = Log-verosimilitud del modelo propuesto para la observación \(i\).
El factor 2 se incluye para que la deviance siga aproximadamente una distribución chi-cuadrado bajo ciertas condiciones.
Interpretación práctica:
Deviance = 0: Modelo perfecto que ajusta exactamente todos los datos observados
Deviance baja: Buen ajuste del modelo a los datos
Deviance alta: Mal ajuste del modelo, sugiere que el modelo no captura adecuadamente los patrones en los datos
Comparación relativa: La deviance es más útil para comparar modelos que para evaluación absoluta. Un modelo con menor deviance indica mejor ajuste, pero el valor absoluto depende del tamaño de la muestra y la naturaleza de los datos.
Deviance residual vs. deviance nula:
Deviance nula: Deviance del modelo que solo incluye el intercepto (sin predictores)
Deviance residual: Deviance del modelo con todos los predictores incluidos
La diferencia entre ambas indica cuánto mejora el modelo al incluir las variables predictoras
6.3.2 Test de la razón de verosimilitudes
El test de la razón de verosimilitudes es la herramienta principal para comparar modelos anidados en GLMs y para evaluar la significancia global del modelo. Se basa en el principio de que si un modelo más complejo no mejora significativamente el ajuste, debemos preferir el modelo más simple por parsimonia.
Cuando comparamos dos modelos anidados (donde uno es un caso especial del otro), la diferencia en sus deviances sigue aproximadamente una distribución chi-cuadrado:
donde \(df\) es la diferencia en grados de libertad (número de parámetros) entre los modelos.
Interpretación del test:
Hipótesis nula (\(H_0\)): El modelo reducido es adecuado (los parámetros adicionales no son necesarios)
Hipótesis alternativa (\(H_1\)): El modelo completo es significativamente mejor
Decisión: Si \(p\)-valor < \(\alpha\) (típicamente 0.05), rechazamos \(H_0\) y preferimos el modelo completo
Aplicaciones principales:
Significancia global del modelo: Comparar el modelo completo con el modelo nulo (solo intercepto) para determinar si las variables predictoras aportan información significativa.
Selección de variables: Evaluar si la inclusión o exclusión de variables específicas mejora significativamente el ajuste del modelo.
Comparación de especificaciones: Decidir entre diferentes formas funcionales o distribuciones para el mismo conjunto de datos.
TipEjemplo: Comparando Modelos con el Test de Razón de Verosimilitudes
Supongamos que queremos determinar si añadir la variable disp (cilindrada) a un modelo de regresión logística que ya contiene wt (peso) mejora significativamente la predicción de si un coche tiene transmisión automática (am).
# Usaremos el dataset mtcarsdata(mtcars)# Modelo Reducido: solo contiene 'wt'modelo_reducido <-glm(am ~ wt, data = mtcars, family = binomial)# Modelo Completo: contiene 'wt' y 'disp'modelo_completo <-glm(am ~ wt + disp, data = mtcars, family = binomial)# Realizamos el Test de Razón de Verosimilitudes (LRT)# En R, esto se hace con la función anova() especificando el testlrt_resultado <-anova(modelo_reducido, modelo_completo, test ="LRT")# Mostramos los resultadosprint(lrt_resultado)
Analysis of Deviance Table
Model 1: am ~ wt
Model 2: am ~ wt + disp
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 30 19.176
2 29 17.785 1 1.3913 0.2382
Interpretación del resultado:
El test compara la Deviance de ambos modelos. La hipótesis nula (\(H\_0\)) es que el modelo reducido es suficiente (es decir, \(\\beta\_{disp} = 0\)).
La diferencia en deviance es de 1.391 con 1 grado de libertad (el parámetro adicional).
El p-valor asociado es 0.238.
Dado que el p-valor es mayor que 0.05, no rechazamos la hipótesis nula. Esto significa que, una vez que tenemos en cuenta el peso del coche (wt), añadir la cilindrada (disp) no aporta una mejora estadísticamente significativa al modelo. Nos quedaríamos con el modelo reducido por el principio de parsimonia.
6.4 Diagnosis de GLMs
La diagnosis de GLMs implica evaluar los supuestos del modelo y detectar problemas potenciales que puedan afectar la validez de las inferencias. A diferencia de la regresión lineal, donde los residuos ordinarios proporcionan información diagnóstica directa, los GLMs requieren herramientas especializadas debido a la heterocedasticidad inherente y las diferentes distribuciones subyacentes.
En lugar de una simple lista de comprobación, abordaremos el diagnóstico respondiendo a tres preguntas clave que un analista se haría, utilizando diferentes tipos de residuos para obtener las respuestas.
6.4.1 Tipos de Residuos en GLMs
La elección del tipo de residuo apropiado es crucial. Los residuos “crudos” (\(y_i - \hat{\mu}_i\)) no son homocedásticos, por lo que se utilizan versiones estandarizadas. Los más importantes son:
Residuos Pearson: Estandarizan el residuo crudo dividiendo por la desviación estándar predicha por el modelo. Son un análogo directo a los residuos estandarizados en regresión lineal. \[
r_i = \frac{y_i - \hat{\mu}_i}{\sqrt{V(\hat{\mu}_i)}}
\]
Residuos Estudentizados: Son una mejora de los residuos Pearson que también tienen en cuenta el leverage (\(h_i\)) de cada observación. Son más fiables para la detección de outliers. \[
r_{S_i} = \frac{y_i - \hat{\mu}_i}{\sqrt{V(\hat{\mu}_i)(1-h_i)}}
\]
Residuos deviance: Son los más recomendados para la inspección visual en gráficos diagnósticos. Su construcción, basada en la contribución de cada punto a la deviance total, les confiere propiedades muy deseables: su distribución se aproxima mejor a la normalidad y su varianza es más estable que la de otros residuos. \[
d_i = \text{sign}(y_i - \hat{\mu}_i) \sqrt{2[l_i(y_i) - l_i(\hat{\mu}_i)]}
\]
6.4.2 ¿La forma del modelo es correcta? (Linealidad y Enlace)
Esta primera pregunta evalúa si la estructura básica del modelo, \(g(\mu) = X\beta\), es adecuada para los datos. Para ello, utilizamos varias herramientas de diagnóstico:
El gráfico de residuos vs. valores ajustados es la herramienta fundamental. Se grafican los residuos (idealmente, deviance) contra los valores predichos en la escala del predictor lineal (\(\hat{\eta}_i\)). Si la forma del modelo es correcta, no deberíamos ver ningún patrón sistemático. Una tendencia curvilínea es una señal clara de que la forma funcional o la función de enlace son incorrectas.
Los gráficos de residuos parciales son esenciales para evaluar si la función de enlace es apropiada para cada predictor individualmente. Un patrón no lineal en este gráfico sugiere que la relación de esa variable específica con la respuesta no es la que asume el modelo.
El test de especificación de enlace (como el Linktest de Pregibon) ofrece una prueba formal. La idea es ajustar un segundo modelo que incluye el predictor lineal al cuadrado (\(\hat{\eta}^2\)) como una variable adicional. Si este término cuadrático resulta significativo, es una fuerte evidencia de que la función de enlace está mal especificada.
Si estos diagnósticos revelan problemas, las estrategias de corrección incluyen aplicar transformaciones a los predictores (ej. logaritmo, términos polinómicos), incluir términos de interacción para capturar relaciones no aditivas, o directamente cambiar la función de enlace a una que se ajuste mejor a los datos.
6.4.3 ¿La distribución que elegimos es la correcta? (Varianza y Normalidad)
Esta pregunta evalúa si la elección de la familia de distribución (Poisson, Binomial, etc.) fue acertada, lo que implica verificar la relación entre la media y la varianza, así como la forma general de los errores.
Un primer aspecto clave al verificar la distribución es la sobredispersión. Imagina que tu modelo es como una regla estricta sobre el comportamiento de los datos. El modelo de Poisson, por ejemplo, impone que la varianza de los conteos debe ser igual a su media (\(Var(Y) = \mu\)). La sobredispersión ocurre cuando tus datos reales son más “desordenados” o variables de lo que esta regla permite.
Para detectar este problema de forma objetiva, calculamos el Estadístico de dispersión (\(\hat{\phi}\)), que compara la varianza observada (a través de los residuos Pearson) con la esperada: \[\hat{\phi} = \frac{X^2_{\text{Pearson}}}{n-p} = \frac{\sum r_i^2}{n-p}\] La interpretación es directa:
Si \(\hat{\phi} \approx 1\): ¡Perfecto! La dispersión de los datos es la que el modelo esperaba.
Si \(\hat{\phi} > 1\): Tienes sobredispersión. El modelo está subestimando la variabilidad real de los datos, lo que invalida las inferencias (errores estándar, p-valores).
La estrategia para corregirlo no es forzar los datos, sino cambiar a un modelo más flexible. El caso clásico es pasar del modelo de Poisson al modelo Binomial Negativo. Este último funciona porque su fórmula para la varianza incluye un parámetro de dispersión adicional (\(\alpha\)) que le permite modelar esa variabilidad extra que el modelo de Poisson no puede capturar: \[Var(Y) = \mu + \alpha\mu^2\]
Este término adicional se ajusta a la variabilidad de los datos, proporcionando estimaciones y errores estándar mucho más fiables.
Un segundo aspecto es la forma general de la distribución, que se evalúa con el Gráfico Q-Q de residuos deviance. Aunque los errores de un GLM no son estrictamente normales, los residuos deviance sí deberían tener una distribución aproximadamente normal si el modelo está bien especificado. Desviaciones sistemáticas de la línea diagonal en el gráfico Q-Q pueden indicar que la distribución asumida para los datos es incorrecta.
6.4.4 ¿Hay observaciones que distorsionan el modelo? (Atípicos e Influyentes)
Finalmente, buscamos identificar puntos individuales que tienen una influencia desproporcionada en el modelo. Las herramientas matemáticas para ello son generalizaciones de las vistas en regresión lineal:
Leverage generalizado (\(h_i\)): Mide el potencial de una observación para ser influyente debido a su posición en el espacio de los predictores. \[
h_i = w_i \mathbf{x}_i^T (\mathbf{X}^T \mathbf{W} \mathbf{X})^{-1} \mathbf{x}_i
\] donde \(w_i\) y \(\mathbf{W}\) son el peso y la matriz de pesos de la última iteración del algoritmo IRLS.
Distancia de Cook para GLMs (\(D_i\)): Mide la influencia global de una observación en todos los coeficientes. Utiliza el residuo Pearson (\(r_i\)). \[
D_i = \frac{r_i^2 h_i}{p(1-h_i)^2}
\]
DFBETAS: Mide la influencia de la observación \(i\) en cada coeficiente individual\(\beta_j\). Es útil para ver si un punto influyente está afectando a una variable de interés particular. \[
\text{DFBETA}_{j,i} = \frac{\hat{\beta}_j - \hat{\beta}_{j(-i)}}{\text{SE}(\hat{\beta}_{j(-i)})} \approx \frac{(\mathbf{X}^T\mathbf{W}\mathbf{X})^{-1}_{jj}x_{ij}(y_i-\hat{\mu}_i)}{\text{SE}(\hat{\beta}_j)\sqrt{1-h_i}}
\]
La herramienta visual que consolida esta información es el gráfico de residuos vs. leverage. La estrategia ante estas observaciones no es eliminarlas automáticamente, sino investigarlas para entender su naturaleza.
6.5 Regresión logística
La regresión logística es una herramienta fundamental para modelar la probabilidad de eventos binarios en una variedad de contextos, desde la medicina hasta la economía y el marketing (Hosmer Jr, Lemeshow, y Sturdivant 2013). La correcta interpretación de los coeficientes mediante odds ratios, así como la evaluación del ajuste del modelo mediante curvas ROC y matrices de confusión, son esenciales para extraer conclusiones válidas de los datos.
6.5.1 Fundamentos de la regresión logística
La regresión logística es una técnica estadística utilizada para modelar la probabilidad de ocurrencia de un evento binario, es decir, cuando la variable dependiente toma solo dos posibles valores (por ejemplo, éxito/fracaso, sí/no, enfermo/sano). A diferencia de la regresión lineal, que modela una relación lineal entre variables, la regresión logística utiliza una función logística para asegurar que las predicciones estén en el rango [0,1], lo cual es necesario para interpretar los resultados como probabilidades.
La función Logística (Sigmoide)
La función logística transforma cualquier valor real en un valor comprendido entre 0 y 1. La forma matemática de la función logística es:
\(P(Y = 1 | X_1, \dots, X_p)\) es la probabilidad de que el evento ocurra.
\(\beta_0\) es el intercepto y \(\beta_1, \beta_2, \dots, \beta_p\) son los coeficientes asociados a las variables independientes \(X_1, X_2, \dots, X_p\).
La curva sigmoide que representa esta función tiene forma de “S”, lo que refleja que para valores muy pequeños o muy grandes del predictor, la probabilidad se aplana hacia 0 o 1, respectivamente.
Función de enlace Logit
En la regresión logística, la relación entre el predictor lineal y la probabilidad se establece mediante la función de enlace logit. El logit de una probabilidad \(p\) se define como:
Esta transformación convierte una probabilidad en una escala que va de \(-\infty\) a \(+\infty\), lo que permite ajustar un modelo lineal a los datos. El modelo logístico puede expresarse como:
6.5.2 Estimación por máxima verosimilitud en regresión logística
La estimación de los parámetros en regresión logística se basa en el método de máxima verosimilitud, adaptado específicamente para la distribución binomial con función de enlace logit.
Para una muestra de \(n\) observaciones independientes, donde \(y_i \in \{0,1\}\) representa el resultado binario para la observación \(i\), la función de verosimilitud se define como:
donde \(x_{ij}\) es el valor de la variable \(j\) para la observación \(i\).
Esta ecuación tiene una interpretación intuitiva: los estimadores de máxima verosimilitud se obtienen cuando la suma de los residuos ponderados por cada variable predictora es igual a cero.
6.5.2.1 Implementación del algoritmo IRLS
Dado que las ecuaciones de verosimilitud no tienen solución analítica cerrada, se utiliza el algoritmo IRLS. Para regresión logística, los elementos específicos son:
Actualización de parámetros:\[\boldsymbol{\beta}^{(t+1)} = (\mathbf{X}^T \mathbf{W}^{(t)} \mathbf{X})^{-1} \mathbf{X}^T \mathbf{W}^{(t)} \mathbf{z}^{(t)}\]
TipEjemplo: Estimación paso a paso en regresión logística
# Demostración del proceso de estimación por máxima verosimilitudlibrary(MASS)data(Pima.tr)# Función para calcular log-verosimilitud manualmentelog_likelihood_logistic <-function(beta, X, y) { eta <- X %*% beta p <-1/ (1+exp(-eta))# Evitar problemas numéricos p <-pmax(pmin(p, 1-1e-15), 1e-15)sum(y *log(p) + (1-y) *log(1-p))}# Preparar datosX <-model.matrix(type ~ glu + bmi, data = Pima.tr)y <-as.numeric(Pima.tr$type =="Yes")# Ajuste con glm para comparaciónmodelo_glm <-glm(type ~ glu + bmi, data = Pima.tr, family = binomial)beta_glm <-coef(modelo_glm)cat("=== ESTIMACIÓN POR MÁXIMA VEROSIMILITUD ===\n")
# Verificar que estos coeficientes maximizan la log-verosimilitudll_optimo <-log_likelihood_logistic(beta_glm, X, y)cat("\nLog-verosimilitud en el óptimo:", round(ll_optimo, 4), "\n")
Log-verosimilitud en el óptimo: -99.2352
# Comparar con valores ligeramente diferentesbeta_test <- beta_glm +c(0.1, 0, 0)ll_test <-log_likelihood_logistic(beta_test, X, y)cat("Log-verosimilitud con perturbación:", round(ll_test, 4), "\n")
6.5.3 Interpretación de coeficientes y odds ratios
Uno de los aspectos más importantes de la regresión logística es la interpretación de los coeficientes. Dado que los coeficientes están en la escala del logit, su interpretación directa no es tan intuitiva como en la regresión lineal. Sin embargo, podemos interpretarlos utilizando odds y odds ratios.
El odds o razón de probabilidades de que ocurra un evento es el cociente entre la probabilidad de que ocurra el evento y la probabilidad de que no ocurra:
\[
\text{odds} = \frac{p}{1 - p}
\]
Por ejemplo, si la probabilidad de éxito es 0.8, el odds sería:
\[
\text{odds} = \frac{0.8}{1 - 0.8} = 4
\]
Esto significa que el evento es 4 veces más probable que no ocurra.
El odds ratio (OR) mide el cambio en los odds cuando una variable independiente aumenta en una unidad. Se calcula como el exponencial del coeficiente de la regresión logística:
\[
\text{OR} = e^{\beta}
\]
Interpretación de OR:
Si OR > 1, el evento es más probable a medida que aumenta la variable independiente.
Si OR < 1, el evento es menos probable a medida que aumenta la variable independiente.
Si OR = 1, no hay efecto.
TipEjemplo
Supongamos que ajustamos un modelo de regresión logística para predecir la probabilidad de tener diabetes en función del índice de masa corporal (BMI). El coeficiente asociado a BMI es 0.08.
\[
\text{OR} = e^{0.08} \approx 1.083
\]
Esto significa que por cada incremento de 1 unidad en el BMI, la odds de tener diabetes aumentan en un 8.3%.
6.5.4 Bondad de ajuste del modelo logístico
La evaluación de la bondad de ajuste en regresión logística presenta desafíos únicos debido a la naturaleza binaria de la variable dependiente. A diferencia de la regresión lineal, donde el \(R^2\) tradicional proporciona una medida directa de la varianza explicada, en la regresión logística necesitamos adoptar enfoques alternativos que se basen en la verosimilitud del modelo y que sean apropiados para datos categóricos.
La bondad de ajuste en regresión logística se evalúa principalmente a través de dos enfoques complementarios: la deviance y los pseudo R². Ambos métodos nos permiten cuantificar qué tan bien nuestro modelo captura los patrones subyacentes en los datos binarios.
La deviance en regresión logística se calcula utilizando la distribución binomial subyacente. Para cada observación, comparamos la probabilidad que predice nuestro modelo con la “probabilidad perfecta” que asignaría un modelo saturado. Matemáticamente, esto se expresa como:
donde \(y_i \in \{0,1\}\) representa el resultado observado y \(\hat{p}_i\) es la probabilidad estimada por nuestro modelo. Es importante notar que cuando \(y_i = 0\) o \(y_i = 1\), algunos términos en esta expresión se anulan automáticamente, lo que refleja la naturaleza discreta de los datos binarios.
La interpretación de la deviance sigue principios similares a los discutidos anteriormente, pero es crucial recordar que ahora estamos tratando con datos binarios. La deviance nos ayuda a entender qué tan bien nuestro modelo logístico se ajusta a los datos de respuesta binaria en comparación con un modelo que simplemente predice la media.
Los pseudo R² son medidas alternativas que intentan capturar la proporción de variabilidad explicada por el modelo, similar al \(R^2\) en regresión lineal, pero adaptadas a la naturaleza de los datos binarios y la verosimilitud del modelo. Estas medidas son útiles para evaluar y comparar modelos, aunque su interpretación no es tan directa como el \(R^2\) tradicional.
El McFadden’s R² es quizás el más utilizado y se define como:
Este pseudo R² compara la log-verosimilitud de nuestro modelo con la de un modelo que solo incluye el intercepto. Los valores típicamente oscilan entre 0 y 1, aunque raramente alcanzan valores tan altos como el \(R^2\) en regresión lineal. En contextos aplicados, valores de McFadden entre 0.2 y 0.4 se consideran indicativos de un buen ajuste.
El Nagelkerke R² representa una versión normalizada que garantiza que el valor máximo sea 1:
Aunque este último tiene la limitación de que su valor máximo teórico es menor que 1, razón por la cual Nagelkerke propuso su corrección.
Es crucial entender que estos pseudo R² no deben interpretarse exactamente como el \(R^2\) tradicional. Mientras que en regresión lineal el \(R^2\) representa la proporción de varianza explicada, en regresión logística estos índices reflejan más bien la mejora en la verosimilitud que aporta nuestro modelo comparado con el modelo nulo. Sin embargo, proporcionan una herramienta valiosa para evaluar y comparar diferentes especificaciones de modelo.
La evaluación integral de la bondad de ajuste en regresión logística requiere considerar tanto la deviance como los pseudo R² en conjunto, complementando esta información con pruebas de significancia global del modelo mediante tests de razón de verosimilitudes, que permiten determinar si la inclusión de las variables predictoras mejora significativamente el ajuste comparado con el modelo nulo.
6.5.5 Validación del modelo logístico
Una vez evaluada la bondad de ajuste del modelo logístico, el siguiente paso fundamental es validar su capacidad predictiva y su rendimiento en la clasificación de nuevas observaciones. La validación en regresión logística presenta características particulares debido a la naturaleza categórica de la variable dependiente, lo que requiere métricas y enfoques específicos que van más allá de las medidas tradicionales de error de predicción.
La validación del modelo logístico se centra en dos aspectos complementarios: la capacidad discriminativa del modelo (qué tan bien puede distinguir entre las dos clases) y la precisión de clasificación (qué proporción de predicciones son correctas). Estas evaluaciones se realizan típicamente mediante la construcción de una matriz de confusión y el análisis de curvas ROC.
La matriz de confusión constituye la herramienta fundamental para evaluar el rendimiento de clasificación en regresión logística. Esta matriz organiza las predicciones del modelo en una tabla de contingencia 2×2 que compara los resultados predichos con los valores reales observados. Para construir esta matriz, primero debemos convertir las probabilidades estimadas por el modelo en predicciones de clase mediante un umbral de decisión, típicamente 0.5.
La clasificación de cada observación resulta en una de cuatro categorías:
Verdaderos Positivos (VP): Predijo positivo y es positivo.
Falsos Positivos (FP): Predijo positivo pero es negativo.
Verdaderos Negativos (VN): Predijo negativo y es negativo.
Falsos Negativos (FN): Predijo negativo pero es positivo.
A partir de esta clasificación, podemos calcular métricas fundamentales de rendimiento:
Precisión (Accuracy):\(\frac{VP + VN}{\text{Total}}\) - representa la proporción total de predicciones correctas
Sensibilidad:\(\frac{VP}{VP + FN}\) - mide la capacidad del modelo para identificar correctamente los casos positivos
Especificidad:\(\frac{VN}{VN + FP}\) - evalúa la capacidad para identificar correctamente los casos negativos
Es importante reconocer que estas métricas pueden verse influenciadas por el umbral de decisión elegido y por el balance de clases en los datos. Un modelo puede tener alta precisión global pero pobre capacidad para detectar la clase minoritaria, especialmente en datasets desbalanceados.
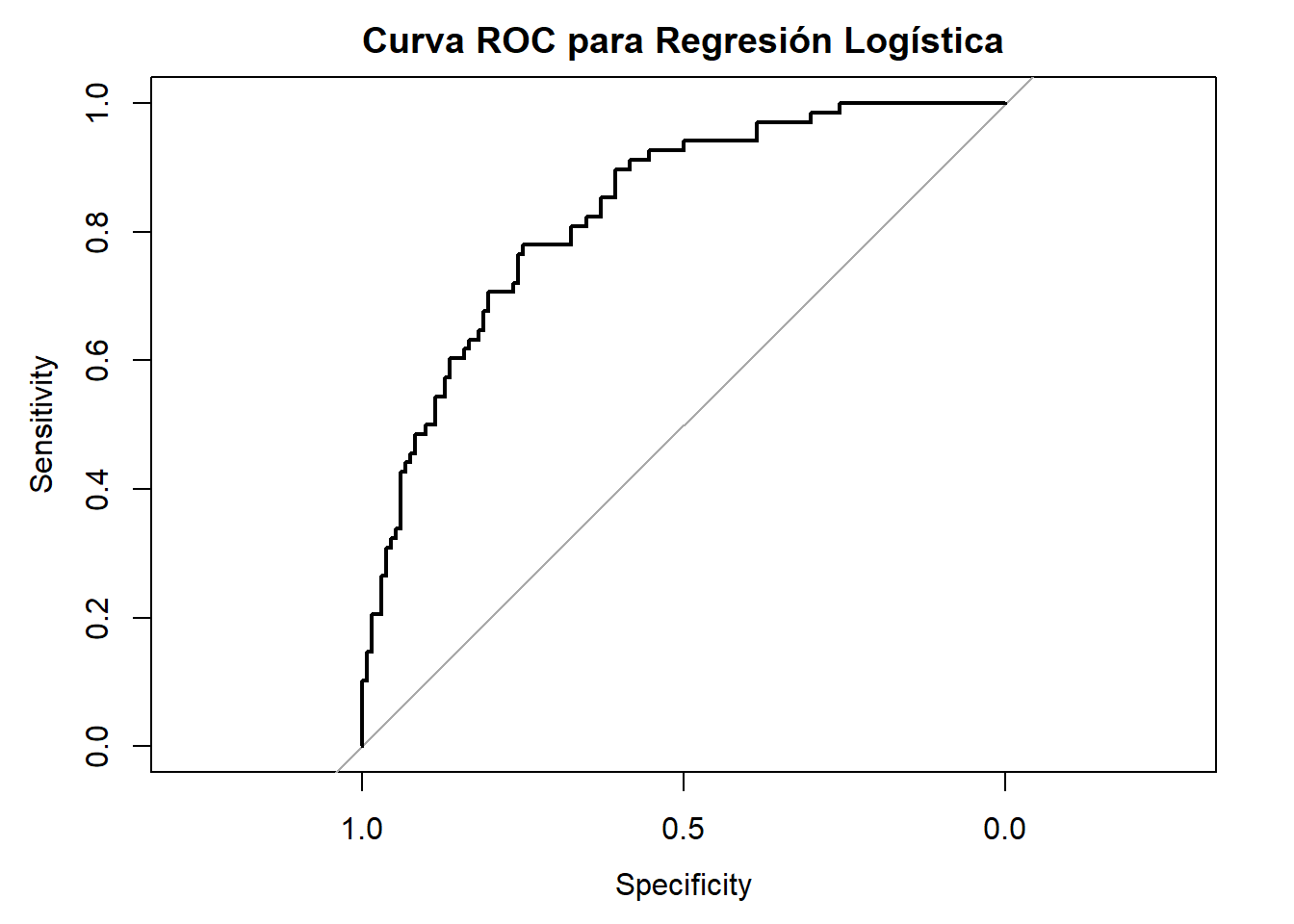
La Curva ROC (Receiver Operating Characteristic) proporciona una evaluación más comprehensiva del rendimiento del modelo al examinar la relación entre la sensibilidad y la especificidad a través de todos los posibles umbrales de decisión. Esta curva grafica la tasa de verdaderos positivos contra la tasa de falsos positivos (1 - especificidad) para cada umbral posible.
Un modelo perfecto produciría una curva ROC que pasaría por la esquina superior izquierda del gráfico (100% sensibilidad, 0% falsos positivos), mientras que un modelo sin capacidad discriminativa produciría una línea diagonal de 45 grados. La AUC (Área Bajo la Curva ROC) cuantifica esta capacidad discriminativa en un solo número que varía entre 0.5 (sin capacidad discriminativa) y 1.0 (discriminación perfecta).
La interpretación de la AUC sigue convenciones establecidas:
0.9 - 1.0: Excelente discriminación
0.8 - 0.9: Buena discriminación
0.7 - 0.8: Discriminación aceptable
0.6 - 0.7: Discriminación pobre
0.5 - 0.6: Sin capacidad discriminativa útil
La validación efectiva del modelo logístico requiere considerar tanto las métricas puntuales derivadas de la matriz de confusión como la capacidad discriminativa global capturada por la curva ROC y la AUC. Además, es crucial evaluar estas métricas tanto en los datos de entrenamiento como en conjuntos de validación independientes para detectar posibles problemas de sobreajuste y asegurar que el modelo generalizará adecuadamente a nuevos datos.
TipEjemplo
Vamos a aplicar la regresión logística en R utilizando el conjunto de datos Pima.tr del paquete MASS, que contiene información sobre mujeres pima y si tienen o no diabetes.
# Cargar la librería y el conjunto de datoslibrary(MASS)data(Pima.tr)# Ajustar el modelo de regresión logísticamodelo_logistico <-glm(type ~ npreg + glu + bmi, data = Pima.tr, family = binomial)# Resumen del modelosummary(modelo_logistico)
Call:
glm(formula = type ~ npreg + glu + bmi, family = binomial, data = Pima.tr)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.718723 1.411080 -6.179 6.46e-10 ***
npreg 0.149213 0.051833 2.879 0.00399 **
glu 0.033879 0.006327 5.355 8.55e-08 ***
bmi 0.094817 0.032405 2.926 0.00343 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 256.41 on 199 degrees of freedom
Residual deviance: 189.89 on 196 degrees of freedom
AIC: 197.89
Number of Fisher Scoring iterations: 5
# Predicciones de probabilidadpredicciones_prob <-predict(modelo_logistico, type ="response")# Clasificación con un umbral de 0.5predicciones_clase <-ifelse(predicciones_prob >0.5, "Yes", "No")# Crear matriz de confusióntabla_confusion <-table(Predicted = predicciones_clase, Actual = Pima.tr$type)print(tabla_confusion)
La regresión de Poisson es una técnica estadística utilizada para modelar datos de conteo, es decir, situaciones en las que la variable dependiente representa el número de veces que ocurre un evento en un período de tiempo o espacio específico (Coxe, West, y Aiken 2009). Este tipo de modelo es adecuado cuando la variable dependiente toma valores enteros no negativos (\(0, 1, 2, \dots\)) y sigue una distribución de Poisson.
La distribución de Poisson describe la probabilidad de que ocurra un número determinado de eventos en un intervalo fijo, dado que estos eventos ocurren de forma independiente y a una tasa constante.
La función de probabilidad de la distribución de Poisson es:
\(Y\) es la variable aleatoria que representa el número de eventos.
\(\lambda\) es la tasa media de ocurrencia de los eventos (esperanza de \(Y\)).
\(y\) es el número de eventos observados (\(y = 0, 1, 2, \dots\)).
6.6.1 Modelo de regresión de Poisson
En la regresión de Poisson, el objetivo es modelar la relación entre la tasa de ocurrencia de los eventos (\(\lambda\)) y un conjunto de variables predictoras \(X_1, X_2, \dots, X_p\).
6.6.2 Supuestos y limitaciones de la regresión de Poisson
Tal y como ocurre en el modelo de regresión lineal, para que la regresión de Poisson sea adecuada, se deben cumplir ciertos supuestos:
Independencia de los eventos: Los eventos deben ocurrir de manera independiente unos de otros.
Distribución de Poisson de la variable dependiente: La variable de respuesta debe seguir una distribución de Poisson, donde la media y la varianza son iguales:
\[
E(Y) = Var(Y) = \lambda
\]
No sobredispersión: Uno de los problemas comunes en los datos de conteo es la sobredispersión, que ocurre cuando la varianza de los datos es mayor que la media (\(Var(Y) > E(Y)\)). La presencia de sobredispersión indica que el modelo de Poisson puede no ser adecuado, y puede ser necesario considerar modelos alternativos como la regresión binomial negativa.
No exceso de ceros: Si hay demasiados ceros en los datos (por ejemplo, en el número de accidentes en diferentes localidades donde muchas tienen cero accidentes), puede ser necesario utilizar modelos de Poisson inflados en ceros (ZIP)(Lambert 1992).
6.6.3 Interpretación de los resultados
La interpretación de los coeficientes en la regresión de Poisson difiere de la regresión lineal debido al uso de la función de enlace logarítmica.
Los coeficientes \(\beta\) representan el logaritmo de la tasa de eventos asociados con un cambio en la variable independiente. Para interpretar en términos de la tasa de ocurrencia, se utiliza el exponencial de los coeficientes:
\[
e^{\beta_i}
\]
Esto representa el factor de cambio multiplicativo en la tasa de eventos por cada unidad adicional en la variable \(X_i\).
ImportanteInterpretando el coeficiente de Poisson: Incidence Rate Ratio (IRR)
En la regresión de Poisson, el coeficiente \(\beta_j\) está en la escala logarítmica de la tasa. Para una interpretación práctica, lo exponenciamos para obtener el Incidence Rate Ratio (IRR):
\[
\text{IRR} = e^{\beta_j}
\]
El IRR es un factor multiplicativo que nos dice cuánto cambia la tasa de eventos esperada por cada incremento de una unidad en el predictor \(X_j\).
Si IRR > 1: Un incremento en \(X_j\) se asocia con un aumento en la tasa de eventos. Un IRR de 1.25 significa que por cada unidad que aumenta \(X_j\), la tasa de eventos esperada se multiplica por 1.25 (es decir, aumenta un 25%).
Si IRR < 1: Un incremento en \(X_j\) se asocia con una disminución en la tasa de eventos. Un IRR de 0.80 significa que por cada unidad que aumenta \(X_j\), la tasa de eventos esperada se multiplica por 0.80 (es decir, disminuye un 20%).
Si IRR = 1: La variable \(X_j\) no tiene efecto sobre la tasa de eventos.
TipEjemplo
Vamos a utilizar R para ajustar un modelo de regresión de Poisson. Supongamos que tenemos datos sobre el número de accidentes de tráfico en diferentes intersecciones de una ciudad, junto con variables como el volumen de tráfico y la visibilidad.
# Simulación de datos para el número de accidentesset.seed(456) # Seed diferente para evitar duplicaciónn <-100# Número de observaciones# Variables predictorastrafico_nuevo <-rnorm(n, mean =1000, sd =300) # Volumen de tráfico en vehículos por díavisibilidad_nueva <-rnorm(n, mean =5, sd =2) # Visibilidad en kilómetros# Generar la tasa de accidentes (lambda) usando un modelo logarítmicolambda_nuevo <-exp(0.01* trafico_nuevo -0.2* visibilidad_nueva)# Generar el número de accidentes como una variable de Poissonaccidentes_nuevo <-rpois(n, lambda = lambda_nuevo)# Crear el data framedatos_ejemplo <-data.frame(accidentes = accidentes_nuevo, trafico = trafico_nuevo, visibilidad = visibilidad_nueva)head(datos_ejemplo)
# Ajustar el modelo de regresión de Poissonmodelo_ejemplo <-glm(accidentes ~ trafico + visibilidad, data = datos_ejemplo, family = poisson)# Resumen del modelosummary(modelo_ejemplo)
Call:
glm(formula = accidentes ~ trafico + visibilidad, family = poisson,
data = datos_ejemplo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 9.607e-04 2.316e-03 0.415 0.678
trafico 9.999e-03 1.360e-06 7350.127 <2e-16 ***
visibilidad -2.000e-01 1.012e-04 -1976.897 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 1.6856e+08 on 99 degrees of freedom
Residual deviance: 8.9300e+01 on 97 degrees of freedom
AIC: 1220.4
Number of Fisher Scoring iterations: 3
El coeficiente asociado a trafico indica cómo el volumen de tráfico afecta la tasa de accidentes.
El coeficiente asociado a visibilidad muestra cómo la visibilidad afecta la frecuencia de accidentes.
6.6.4 Estimación por máxima verosimilitud en regresión de Poisson
La estimación de parámetros en regresión de Poisson utiliza también el método de máxima verosimilitud, pero adaptado específicamente para la distribución de Poisson con función de enlace logarítmica. Este enfoque garantiza que las estimaciones aprovechen de manera óptima la información contenida en los datos de conteo.
Para una muestra de \(n\) observaciones independientes, donde \(y_i\) representa el conteo de eventos para la observación \(i\), la función de verosimilitud se define como:
Esta ecuación indica que los estimadores de máxima verosimilitud se obtienen cuando la suma de los residuos (observado menos esperado) ponderados por cada variable predictora es cero.
6.6.4.1 Implementación del algoritmo IRLS
Dado que las ecuaciones de verosimilitud no tienen solución analítica cerrada, se utiliza el algoritmo IRLS adaptado para regresión de Poisson. Los elementos específicos son:
Actualización de parámetros:\[\boldsymbol{\beta}^{(t+1)} = (\mathbf{X}^T \mathbf{W}^{(t)} \mathbf{X})^{-1} \mathbf{X}^T \mathbf{W}^{(t)} \mathbf{z}^{(t)}\]
6.6.4.2 Propiedades específicas de la estimación Poisson
La estimación por máxima verosimilitud en regresión de Poisson tiene características particulares que la distinguen de otros GLMs:
Equidispersión: El modelo asume que \(E(Y_i) = \text{Var}(Y_i) = \lambda_i\), lo que significa que la varianza aumenta linealmente con la media.
Convergencia: Generalmente requiere menos iteraciones que la regresión logística debido a la naturaleza más estable de la función de enlace logarítmica.
Estabilidad numérica: La función de enlace logarítmica garantiza automáticamente que \(\lambda_i > 0\), evitando problemas de valores negativos en las tasas estimadas.
Interpretación multiplicativa: Los coeficientes se interpretan como efectos multiplicativos sobre la tasa, lo que es natural para datos de conteo.
TipEjemplo: Estimación paso a paso en regresión de Poisson
# Demostración del proceso de estimación por máxima verosimilitud# Usar los datos simulados anterioresset.seed(123)n <-100trafico <-rnorm(n, mean =1000, sd =300)visibilidad <-rnorm(n, mean =5, sd =2)lambda <-exp(-2+0.001*trafico -0.2*visibilidad)accidentes <-rpois(n, lambda)datos_accidentes <-data.frame(accidentes, trafico, visibilidad)# Función para calcular log-verosimilitud manualmentelog_likelihood_poisson <-function(beta, X, y) { eta <- X %*% beta lambda <-exp(eta)sum(y *log(lambda) - lambda -lgamma(y +1))}# Preparar datosX <-model.matrix(accidentes ~ trafico + visibilidad, data = datos_accidentes)y <- datos_accidentes$accidentes# Ajuste con glmmodelo_glm_pois <-glm(accidentes ~ trafico + visibilidad, data = datos_accidentes, family = poisson)beta_glm_pois <-coef(modelo_glm_pois)cat("=== ESTIMACIÓN POR MÁXIMA VEROSIMILITUD - POISSON ===\n")
=== ESTIMACIÓN POR MÁXIMA VEROSIMILITUD - POISSON ===
Al igual que en la regresión logística, la bondad de ajuste en los modelos de Poisson se aleja del \(R^2\) tradicional y se centra en medidas basadas en la verosimilitud. El objetivo es cuantificar si el modelo captura adecuadamente la estructura de los datos de conteo.
La deviance sigue siendo la métrica fundamental. Para la regresión de Poisson, se calcula comparando la log-verosimilitud del modelo ajustado con la de un modelo saturado (donde \(\hat{\mu}_i = y_i\)). La fórmula específica es: \[D = 2 \sum_{i=1}^{n} \left[ y_i \log\left(\frac{y_i}{\hat{\mu}_i}\right) - (y_i - \hat{\mu}_i) \right]\] Donde el término \(y_i \log(y_i)\) se considera cero si \(y_i = 0\). Al igual que en otros GLMs, la deviance es clave para comparar modelos anidados mediante el Test de la Razón de Verosimilitudes (LRT).
Sin embargo, para los modelos de Poisson, la prueba de bondad de ajuste más importante en la práctica es la evaluación de la sobredispersión. Un buen ajuste del modelo de Poisson implica que se cumple el supuesto de equidispersión (\(Var(Y) = \mu\)). Por lo tanto, el estadístico de dispersión (\(\hat{\phi}\)) se convierte en una medida de facto de la bondad de ajuste: \[\hat{\phi} = \frac{X^2_{\text{Pearson}}}{n-p}\] Un valor de \(\hat{\phi}\) cercano a 1 indica que el supuesto de la distribución de Poisson se cumple y que el ajuste del modelo es adecuado. Si \(\hat{\phi}\) es significativamente mayor que 1, el modelo no se ajusta bien a la variabilidad de los datos, y este es el principal indicador para buscar alternativas como la regresión binomial negativa.
Aunque los pseudo R² (como el de McFadden) pueden calcularse, son menos utilizados e informativos en el contexto de la regresión de Poisson en comparación con el análisis de la dispersión.
6.6.6 Validación del modelo de Poisson
A diferencia de la regresión logística, donde la validación se centra en la capacidad de clasificación, la validación de un modelo de Poisson se enfoca en su capacidad de predicción: ¿qué tan cerca están los conteos predichos por el modelo de los conteos reales observados?
El proceso de validación suele implicar la división de los datos en un conjunto de entrenamiento (train) y uno de prueba (test). El modelo se ajusta con los datos de entrenamiento y su rendimiento predictivo se evalúa sobre los datos de prueba, que el modelo no ha visto antes. Esto nos da una estimación honesta de cómo generalizará el modelo a nuevos datos.
Las métricas de validación principales para modelos de conteo son:
Raíz del Error Cuadrático Medio (RMSE): Es una de las métricas más comunes y mide la desviación estándar de los residuos. Penaliza más los errores grandes. \[
\text{RMSE} = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{\mu}_i)^2}
\]
Error Absoluto Medio (MAE): Mide la magnitud promedio de los errores, siendo menos sensible a valores atípicos que el RMSE. \[
\text{MAE} = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{\mu}_i|
\]
Ambas métricas se expresan en las mismas unidades que la variable de respuesta (por ejemplo, “accidentes”, “compras”), lo que facilita su interpretación. Un modelo con valores de RMSE y MAE más bajos en el conjunto de prueba se considera que tiene un mejor rendimiento predictivo.
Una herramienta visual clave para la validación es el gráfico de valores predichos vs. valores reales en el conjunto de prueba. En un modelo con buena capacidad predictiva, los puntos deberían agruparse cerca de la línea diagonal \(y=x\), indicando que las predicciones (\(\hat{\mu}_i\)) son cercanas a los valores observados (\(y_i\)).
6.7 Otros GLMs
La regresión binomial negativa y los modelos basados en distribuciones como Gamma e Inversa Gaussiana amplían la capacidad de los Modelos Lineales Generalizados (GLM) para adaptarse a una amplia variedad de situaciones del mundo real. Estos modelos son especialmente útiles cuando los datos presentan características como sobredispersión, sesgo o restricciones en el dominio (por ejemplo, solo valores positivos). La elección adecuada del modelo y la función de enlace garantiza predicciones precisas y válidas, contribuyendo a la toma de decisiones informadas en campos como la salud, la ingeniería y la economía.
6.7.1 Regresión binomial negativa
Tal y como hemos visto en apartados anteriores, la sobredispersión ocurre cuando la varianza de los datos de conteo es mayor que la media, lo cual viola uno de los supuestos clave de la regresión de Poisson, que asume que la media y la varianza son iguales (\(E(Y) = Var(Y) = \lambda\)). La sobredispersión puede surgir por varias razones:
Heterogeneidad no modelada: Existen factores que afectan la variable dependiente pero no han sido incluidos en el modelo.
Dependencia entre eventos: Los eventos no ocurren de forma independiente.
Exceso de ceros: Hay más ceros en los datos de los que predice la distribución de Poisson.
Cuando la sobredispersión está presente, la regresión de Poisson subestima los errores estándar, lo que puede llevar a conclusiones incorrectas sobre la significancia de los predictores.
La regresión binomial negativa es una extensión de la regresión de Poisson que introduce un parámetro adicional para manejar la sobredispersión. Este modelo permite que la varianza sea mayor que la media:
\[
Var(Y) = \lambda + \alpha \lambda^2
\]
Donde \(\alpha\) es el parámetro de dispersión. Si \(\alpha = 0\), el modelo se reduce a la regresión de Poisson.
La forma funcional del modelo binomial negativo es similar al de Poisson:
Pero la varianza ahora incluye el término adicional \(\alpha\) para capturar la sobredispersión.
TipEjemplo
# Instalar y cargar la librería MASS que contiene la función glm.nblibrary(MASS)# Usar los datos de accidentes del ejemplo anterior# Ajuste de un modelo binomial negativomodelo_binom_neg <-glm.nb(accidentes ~ trafico + visibilidad, data = datos_accidentes)
Call:
glm.nb(formula = accidentes ~ trafico + visibilidad, data = datos_accidentes,
init.theta = 2158.536138, link = log)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.7560791 1.5223127 -3.781 0.000156 ***
trafico 0.0028439 0.0009831 2.893 0.003818 **
visibilidad 0.1308306 0.1402185 0.933 0.350795
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Negative Binomial(2158.536) family taken to be 1)
Null deviance: 59.679 on 99 degrees of freedom
Residual deviance: 50.680 on 97 degrees of freedom
AIC: 87.301
Number of Fisher Scoring iterations: 1
Theta: 2159
Std. Err.: 49427
Warning while fitting theta: iteration limit reached
2 x log-likelihood: -79.301
# Comparar la dispersión con el modelo de Poissoncat("Dispersión en Poisson (deviance/df.residual):", round(modelo_glm_pois$deviance / modelo_glm_pois$df.residual, 3), "\n")
Dispersión en Poisson (deviance/df.residual): 0.523
cat("Parámetro theta en Binomial Negativa:", round(modelo_binom_neg$theta, 3), "\n")
Interpretación del parámetro \(\theta\) en binomial negativa:
El parámetro \(\theta\) controla el grado de sobredispersión en el modelo
Valores altos de \(\theta\) (ej: \(\theta > 100\)): Poca sobredispersión, el modelo se aproxima a Poisson
Valores bajos de \(\theta\) (ej: \(\theta < 10\)): Mucha sobredispersión, diferencia significativa respecto a Poisson
Regla práctica: Si \(\theta\) es pequeño, confirma que había sobredispersión y que el modelo binomial negativa es más apropiado que Poisson
Comparación de modelos:
Si AIC de binomial negativa < AIC de Poisson → preferir binomial negativa
El modelo binomial negativa corrige la subestimación de errores estándar que ocurre en Poisson con sobredispersión
6.7.2 Modelos para variables continuas no normales
Existen situaciones en las que la variable dependiente es continua, pero no sigue una distribución normal. En estos casos, los Modelos Lineales Generalizados (GLM) permiten utilizar distribuciones alternativas como Gamma o Inversa Gaussiana, junto con funciones de enlace específicas.
6.7.2.1 Regresión gamma para datos positivos y sesgados
La regresión Gamma es adecuada para modelar variables continuas que son positivas y tienen una distribución sesgada a la derecha. Ejemplos típicos incluyen tiempos de espera, costos médicos o duración de procesos.
La distribución Gamma asume que la variable dependiente es continua y positiva.
La varianza de la variable dependiente aumenta proporcionalmente al cuadrado de la media.
# Simulación de costos médicosset.seed(123)n <-100ingresos <-rnorm(n, mean =50000, sd =10000)edad <-rnorm(n, mean =45, sd =10)costos <-rgamma(n, shape =2, rate =0.00005* ingresos +0.01* edad)# Ajuste del modelo Gammamodelo_gamma <-glm(costos ~ ingresos + edad, family =Gamma(link ="log"))# Resumen del modelosummary(modelo_gamma)
Call:
glm(formula = costos ~ ingresos + edad, family = Gamma(link = "log"))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.440e-01 5.294e-01 0.650 0.5173
ingresos -1.807e-05 7.804e-06 -2.316 0.0227 *
edad 3.584e-03 7.366e-03 0.487 0.6277
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Gamma family taken to be 0.5010938)
Null deviance: 60.771 on 99 degrees of freedom
Residual deviance: 58.345 on 97 degrees of freedom
AIC: 105.47
Number of Fisher Scoring iterations: 5
Los coeficientes muestran cómo los ingresos y la edad afectan los costos médicos esperados.
El enlace logarítmico asegura que las predicciones sean siempre positivas.
6.7.2.2 Regresión inversa gaussiana
La regresión Inversa Gaussiana es útil para modelar tiempos de respuesta o variables donde la varianza disminuye rápidamente a medida que la media aumenta. Este modelo se aplica en campos como la ingeniería, donde se analizan tiempos hasta fallas de sistemas.
# Instalar y cargar la librería correctalibrary(statmod)# Simulación de datosset.seed(123)n <-100carga_trabajo <-rnorm(n, mean =50, sd =10)# Generar tiempos hasta el fallo usando la distribución inversa gaussiana# Aseguramos que los valores de carga_trabajo sean positivos para evitar problemas numéricoscarga_trabajo[carga_trabajo <=0] <-1tiempo_fallo <-rinvgauss(n, mean =100/ carga_trabajo, dispersion =1)# Ajuste del modelo Inversa Gaussiana con enlace logarítmicomodelo_inversa_gauss <-glm(tiempo_fallo ~ carga_trabajo, family =inverse.gaussian(link ="1/mu^2"),start =c(0.01, 0.01))
Warning in sqrt(eta): Se han producido NaNs
Warning: step size truncated due to divergence
# Resumen del modelosummary(modelo_inversa_gauss)
Call:
glm(formula = tiempo_fallo ~ carga_trabajo, family = inverse.gaussian(link = "1/mu^2"),
start = c(0.01, 0.01))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.106143 0.462230 -0.230 0.819
carga_trabajo 0.008261 0.009623 0.859 0.393
(Dispersion parameter for inverse.gaussian family taken to be 1.348442)
Null deviance: 94.085 on 99 degrees of freedom
Residual deviance: 93.171 on 98 degrees of freedom
AIC: 294.2
Number of Fisher Scoring iterations: 5
Advertencia¿Qué GLM debo usar?
La elección del modelo correcto depende casi exclusivamente de la naturaleza de tu variable respuesta (\(Y\)). Aquí tienes una guía rápida:
¿Tu variable respuesta es binaria (Sí/No, 0/1, Éxito/Fracaso)?
Usa Regresión Logística.
¿Tu variable respuesta es un conteo de eventos (nº de accidentes, nº de clientes, nº de fallos)?
Empieza con una Regresión de Poisson.
Importante: Después de ajustar el modelo, comprueba si hay sobredispersión.
Si la hay (estadístico de dispersión \(\hat{\phi} > 1.5\) o la teoría lo sugiere), cambia a una Regresión Binomial Negativa.
¿Tu variable respuesta es continua y estrictamente positiva, con una distribución asimétrica hacia la derecha (ej. tiempos, costos, reclamaciones de seguros)?
Usa Regresión Gamma. Es una excelente alternativa a transformar la variable con logaritmos y usar un modelo lineal.
¿Tu variable respuesta es un tiempo hasta un evento y tiene una asimetría muy pronunciada?
Considera una Regresión Inversa Gaussiana.
Coxe, Stefany, Stephen G West, y Leona S Aiken. 2009. «The analysis of count data: A gentle introduction to Poisson regression and its alternatives». Journal of personality assessment 91 (2): 121-36.
Hosmer Jr, David W, Stanley Lemeshow, y Rodney X Sturdivant. 2013. Applied logistic regression. John Wiley & Sons.
Lambert, Diane. 1992. «Zero-inflated Poisson regression, with an application to defects in manufacturing». Technometrics 34 (1): 1-14.
Nelder, John Ashworth, y Robert WM Wedderburn. 1972. «Generalized linear models». Journal of the Royal Statistical Society Series A: Statistics in Society 135 (3): 370-84.